In this blog post, I will guide you through building a real-time sentiment analysis application for Twitch chat using Apache Flink. This application will be able to process live messages from a Twitch channel and determine the overall sentiment of the chat.
The project was built with the following environment:
OS: macOS Sonoma
Java: 11
Flink: 1.17.2
The underlying idea of this article is: to further educate ourselves in the field of Data Engineering, we should follow our passion and grow through actual projects.
Find a problem that interests and motivates you, and try to solve it.
By the end of this blog post, you will have a working application that can be used to track the sentiment of a Twitch chat in real-time. It can be used with one ore more Twitch channels. You will also learn the basics of Apache Flink and sentiment analysis in Java.
Streams of data are everywhere. Almost all data that is generated is generated as a stream of data naturally, even if we mostly process data in batches. This can be GPS data, interaction tracking for apps or websites, sensor data or messages in a Twitch chat.
Stream processing means to process data in motion
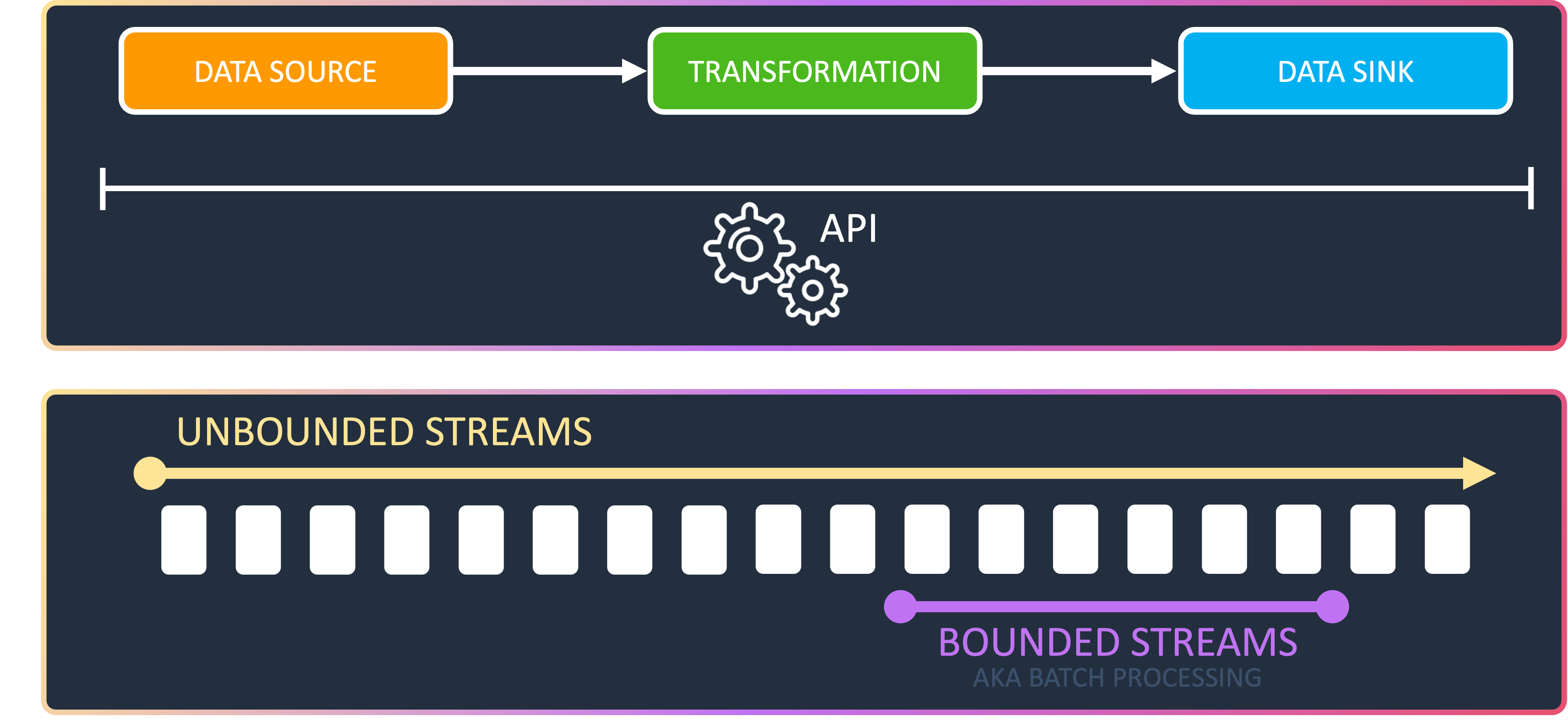
A stream processing application usually consists of data sources, which generate streams of data, operators to process the data and sinks. These days, there are many frameworks and services that allow to implement stream processing applications and often concepts are similar. One of them is Apache Flink.
Apache Flink is not only a framework but also a distributed process engine. It allows to create and run stateful computations on unbounded and bounded data streams. Ubounded streams have a defined start, but no defined end while bounded data streams have a defined start and end. This might sound familiar, since that can also be seen as a batch of data but represented as a stream.
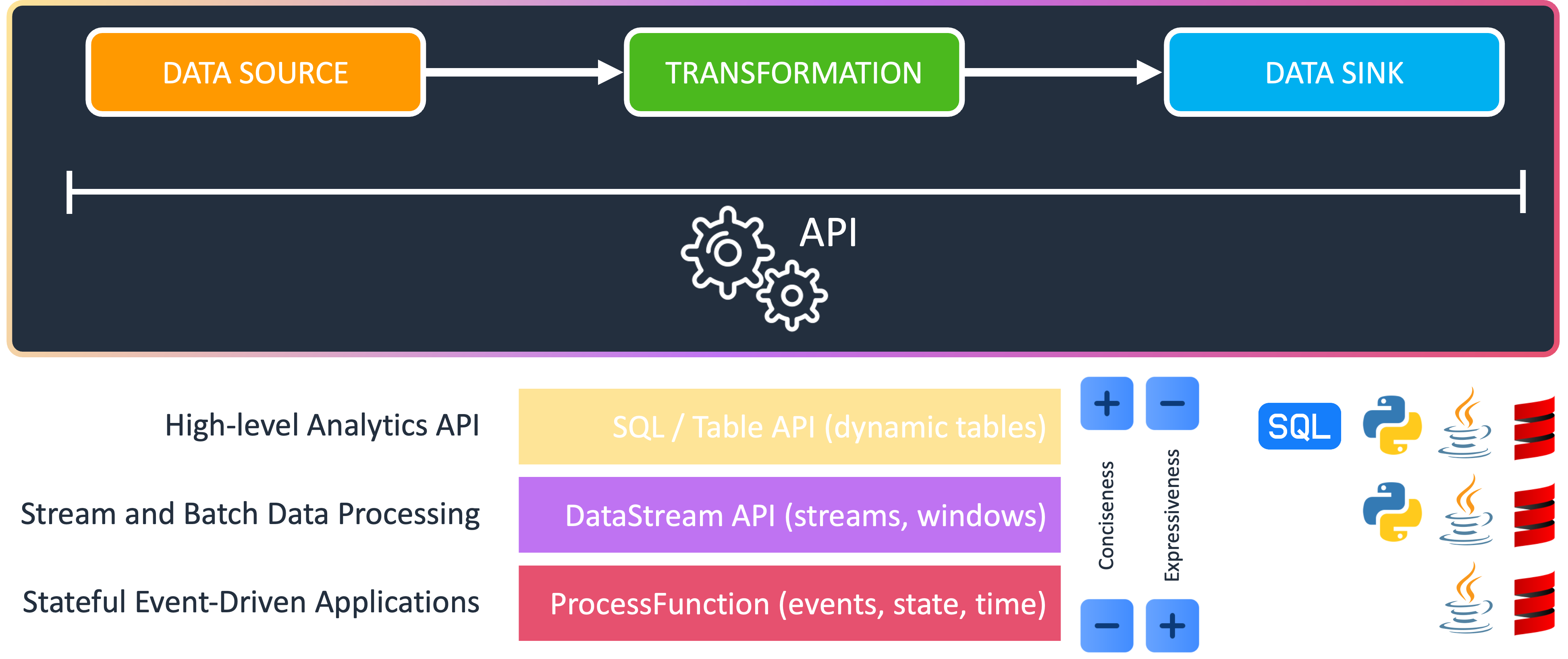
Flink offers APIs to define streaming applications. With those you can control data sources, transformations and data sinks. With the SQL / Table API you can define streaming applications using SQL, which is an amazing feature but please keep in mind that streaming SQL behaves differently from batch SQL, which might require a shift in how to approach problems. Then, there is the DataStream API which can be used to compose your streaming pipeline with predefined functions. This can be used in Python, Java and Scala. If you need full control over events, state and time, the ProcessFunction layer is the way to go.
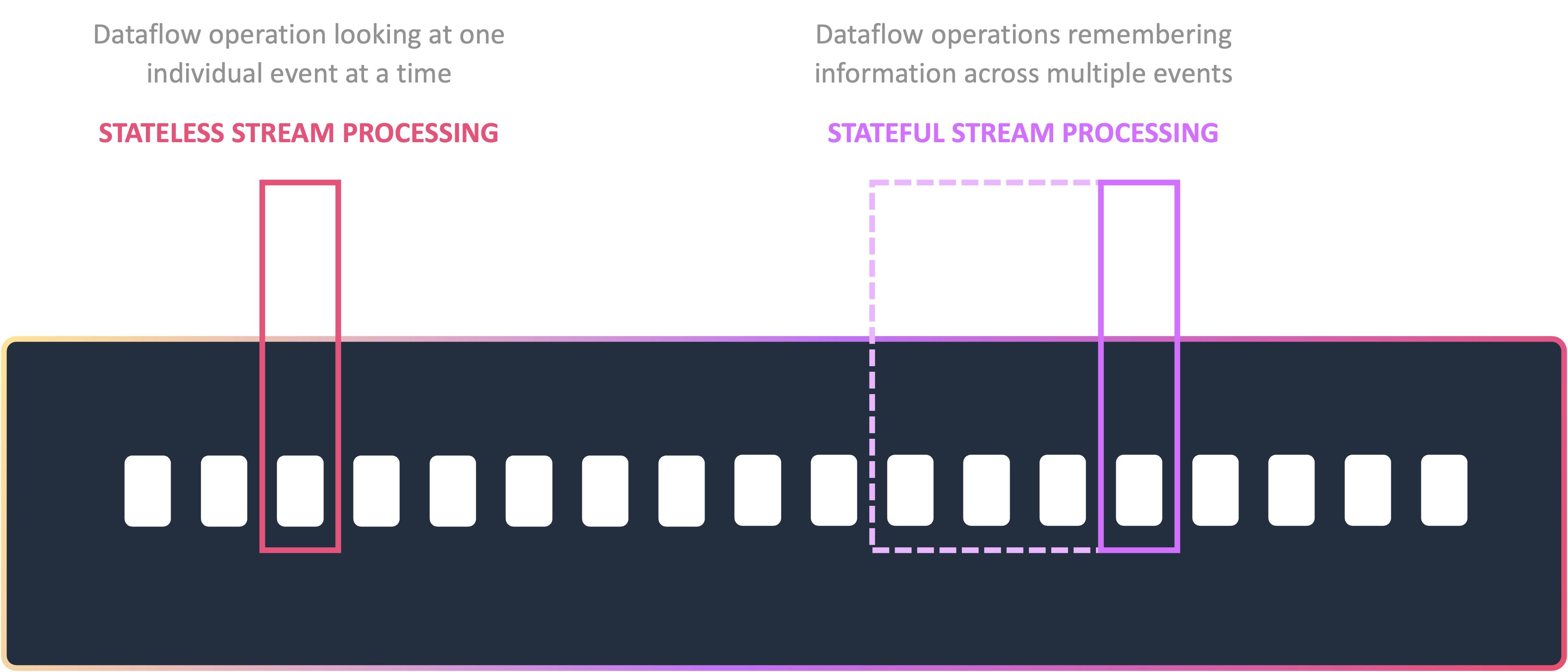
For this use-case, we will use the DataStream API in Java to define a custom source to read the Twitch chat as a stream of data. Futhermore, we will define a custom map function, which takes each Twitch message as input, performs the sentiment analysis on it and returns a tuple with the message and the analysis result. Finally, we simply use a pre-defined sink to print the result. In this particular case, we only look at one invdividual event at a time, this is called stateless stream processing. Bare in mind that one of the key features of Flink is to remember information across multiple events, e.g. in form of windowing functions. This is called stateful stream processing.
If you are interested in a more advanced Flink use-case including state and other advanced techniques like the Broadcast State Pattern, have a look at my talk at the Big Data Conference Europe 2023:
Imagine Natural Language Processing (NLP) as your super-powered translator for computer brains. It lets them understand the nuances of human language, just like you can tell the difference between a sarcastic “good job” and a genuine one. This goes beyond simple keyword matching and delves into the complexities of grammar, syntax, and semantics.
Here are some NLP applications you might encounter:
Spam filtering: NLP can identify suspicious patterns in emails, separating legitimate messages from spam.
Machine translation: NLP helps bridge the language gap by analyzing the structure and meaning of sentences for accurate translation.
Voice assistants: Siri, Alexa, and Google Assistant all leverage NLP to understand your voice commands and respond intelligently.
One other application of NLP is sentiment analysis. Think of it like an emotional compass for text. It assigns a sentiment score (positive, negative, or neutral) to a piece of text, helping us gauge the overall feeling behind it.
There are two main approaches to sentiment analysis:
Lexicon-based: This approach relies on pre-built dictionaries containing words with predefined sentiment scores. The sentiment score of a text is calculated based on the scores of the identified words.
Machine Learning-based: This method utilizes machine learning algorithms trained on massive datasets of text labeled with sentiment. These algorithms can learn complex relationships between words and their emotional connotations, leading to more nuanced sentiment analysis.
This is perfect for deciphering those Twitch chat vibes!
In our Twitch chat example, we can use sentiment analysis to see if the chat is overflowing with happiness or tilting over a missed play. This can be fascinating for streamers to understand their audience’s real-time reaction and maybe even adjust their content accordingly! It could be used for real-time monitoring of the communities mood.
Setting up a Flink project
A simple and fast way to setup a Flink project is Maven. Maven is a tool that can be used for building and managing primarily Java-based projects. Maven can support you as a developer by adressing the aspects of how your project is buil and how its dependencies are managed.
Maven also includes a project templating toolkit called Archetype. With Archetype you can quickly generate a new project based on an existing template.
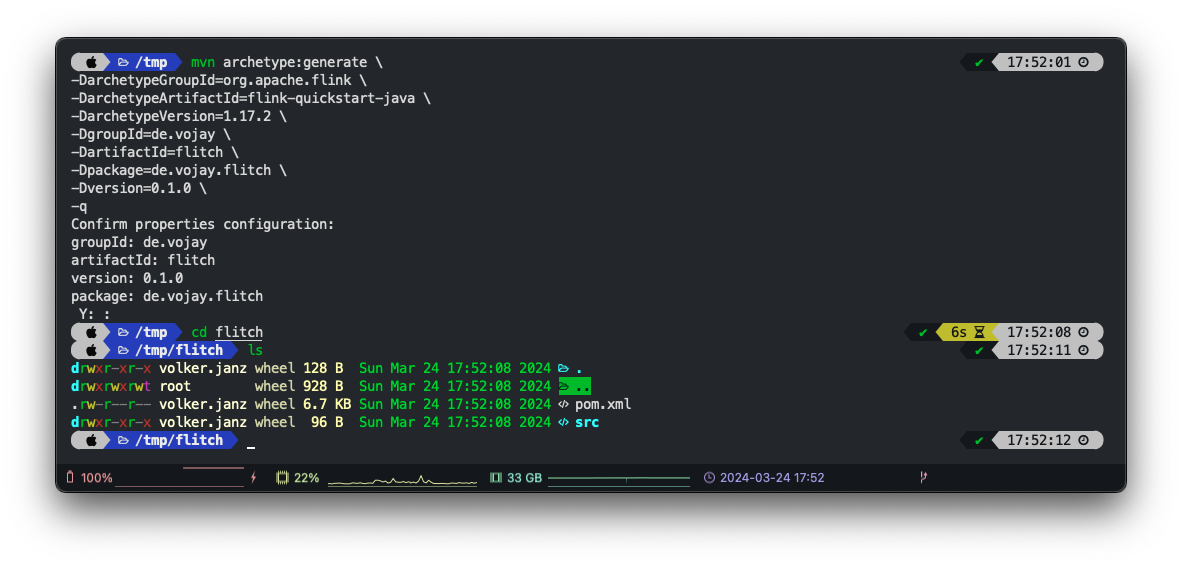
There are Archetypes for all kinds of projects, from a simple Java project (maven-archetype-quickstart) to framework specific project skeletons, for example to create Flink based projects (flink-quickstart-java).
Most of the parameters are optional, if you don’t add them, the CLI tool will ask you to enter the details while it is creating your project. With -q we reduce the output. After executing the above command, we will get the following output:
Before we get to the actual implementation, we will prepare the generated project a bit for our use-case.
Project settings in IntelliJ
If you are using IntelliJ, we now have to adjust the module and project settings, to ensure we are using the right Java version and also have the correct language level.
With the project opened in IntelliJ, click on File –> Project Structure.
Within the Project Structure window, navigate to Project and ensure to use the Java 11 SDK.
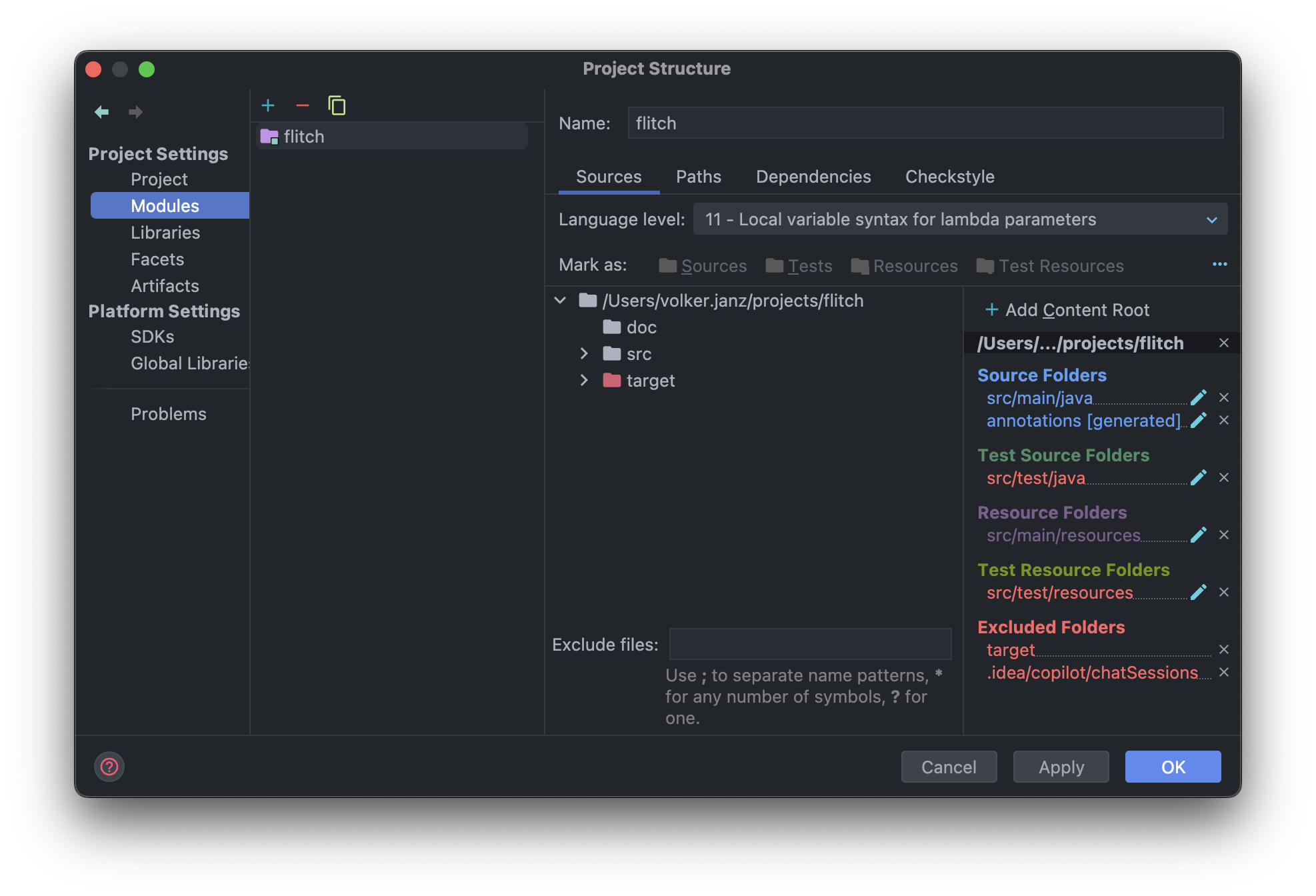
Finally, navigate to Modules and change the language level to 11.
Rename and reduce main class
Rename the generated class DataStreamJob simply to App.
With this, we create a execution environment, read data from a bounded stream with two elements (“Hello” and “World”), print the elements to STDOUT and execute the application with the name “Flitch”.
But for now, let’s not start the application since more adjustments are necessary.
pom.xml project settings
The pom.xml file in Maven is a configuration file that serves as the project’s blueprint. It stands for “Project Object Model” and contains information and configurations for the project, such as project dependencies, project version, build plugins, and goals, among others. Maven uses this file to understand the project structure, manage dependencies, and perform various tasks during the build process.
Let’s change the following aspects, so that we use the desired Java version, have a proper name and adjust the main class of the demo.
Set target Java version to 11 (LTS):
<target.java.version>11</target.java.version>
Change name:
<name>Flitch - Flink Twitch Demo Project</name>
Change main class:
<mainClass>de.vojay.flitch.App</mainClass>
Run configuration
Run configurations in IntelliJ are settings that specify how to launch and debug your project. They allow you to customize aspects like the main class to run, program arguments, and environment variables. You can create multiple configurations to easily switch between different running or debugging scenarios, streamlining your development process.
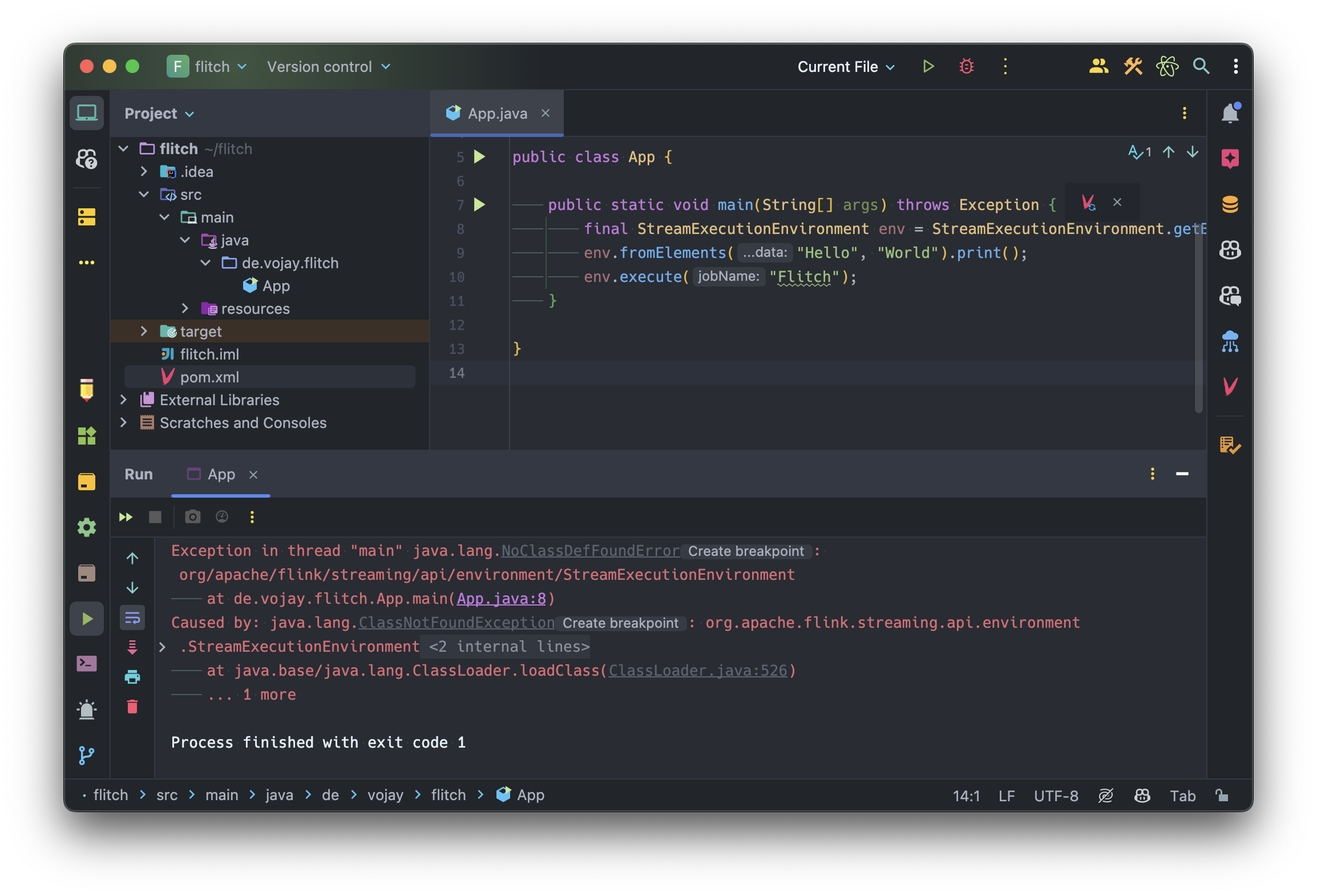
But before we create one, let’s see what happens if we run our application. So without further ado, let’s start our main class App by simply clicking the play button.
The application will fail, this is on purpose.
The reason it failed is a java.lang.NoClassDefFoundError. This is, because we have dependencies defined in our pom.xml, which are not in the classpath of Java when running the application:
The relevant part is the scope. In Maven, the scope of a dependency specifies the visibility and the lifecycle of the dependency in relation to the project. It determines how and when a dependency is included in your project, affecting classpath and module builds.
Scope provided means that the dependencies are expected to be provided by the JDK or the runtime environment when executing or deploying your project, thus not packaged.
When using Flink in a production environment, you will have a running Flink cluster somewhere, either on-premises or in the cloud. This environment already has the required dependencies in the classpath per default and we submit our application JAR to this production cluster. Thus, we do not need to package these dependencies with the JAR.
However, that also means when we run the application locally, these are not in the classpath. And since we have a plain Java setup, we get the java.lang.NoClassDefFoundError.
There are multiple solutions for this problem. We could define different profiles with different scopes in Maven, so that the scope is different in our local environment.
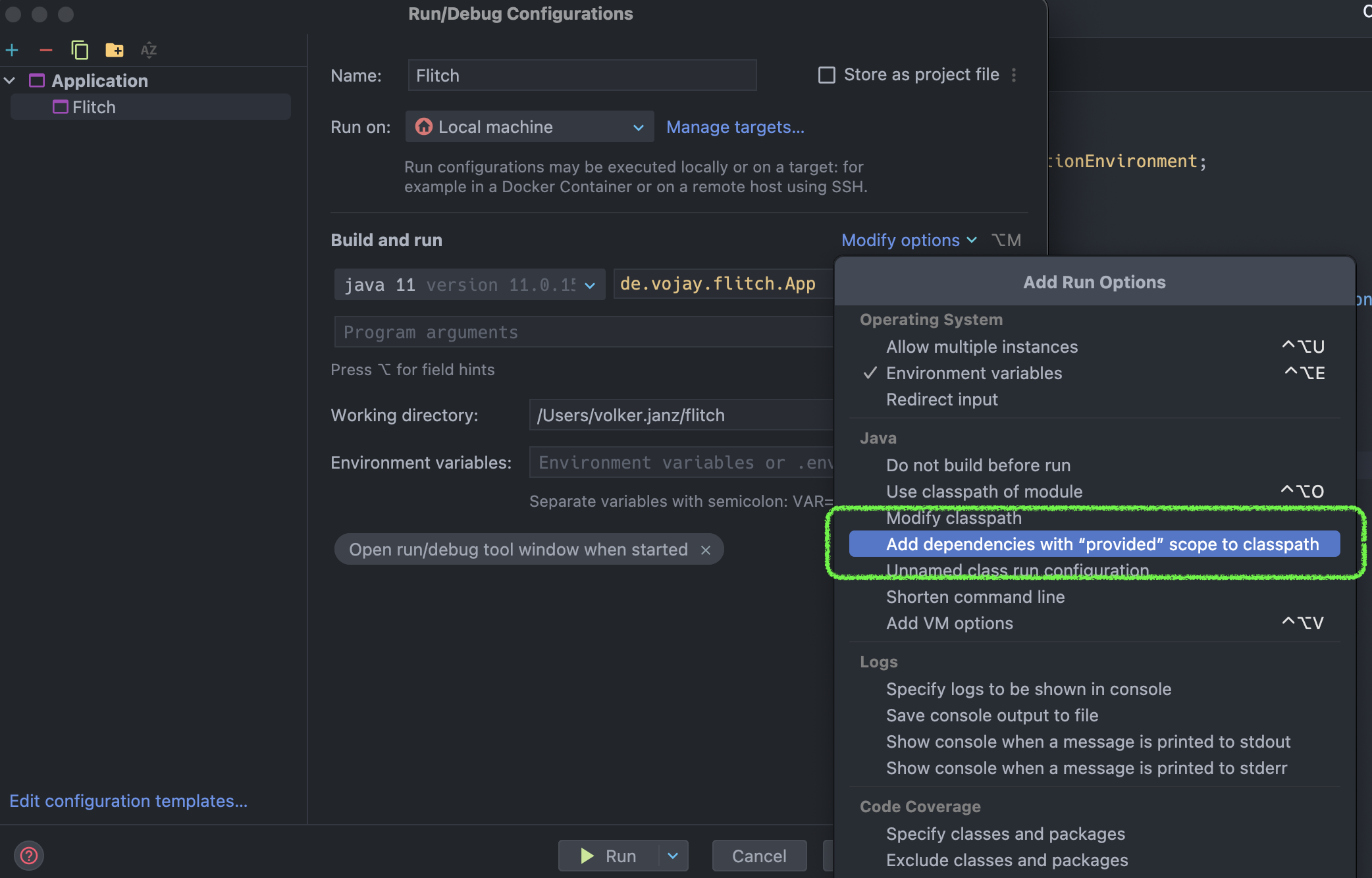
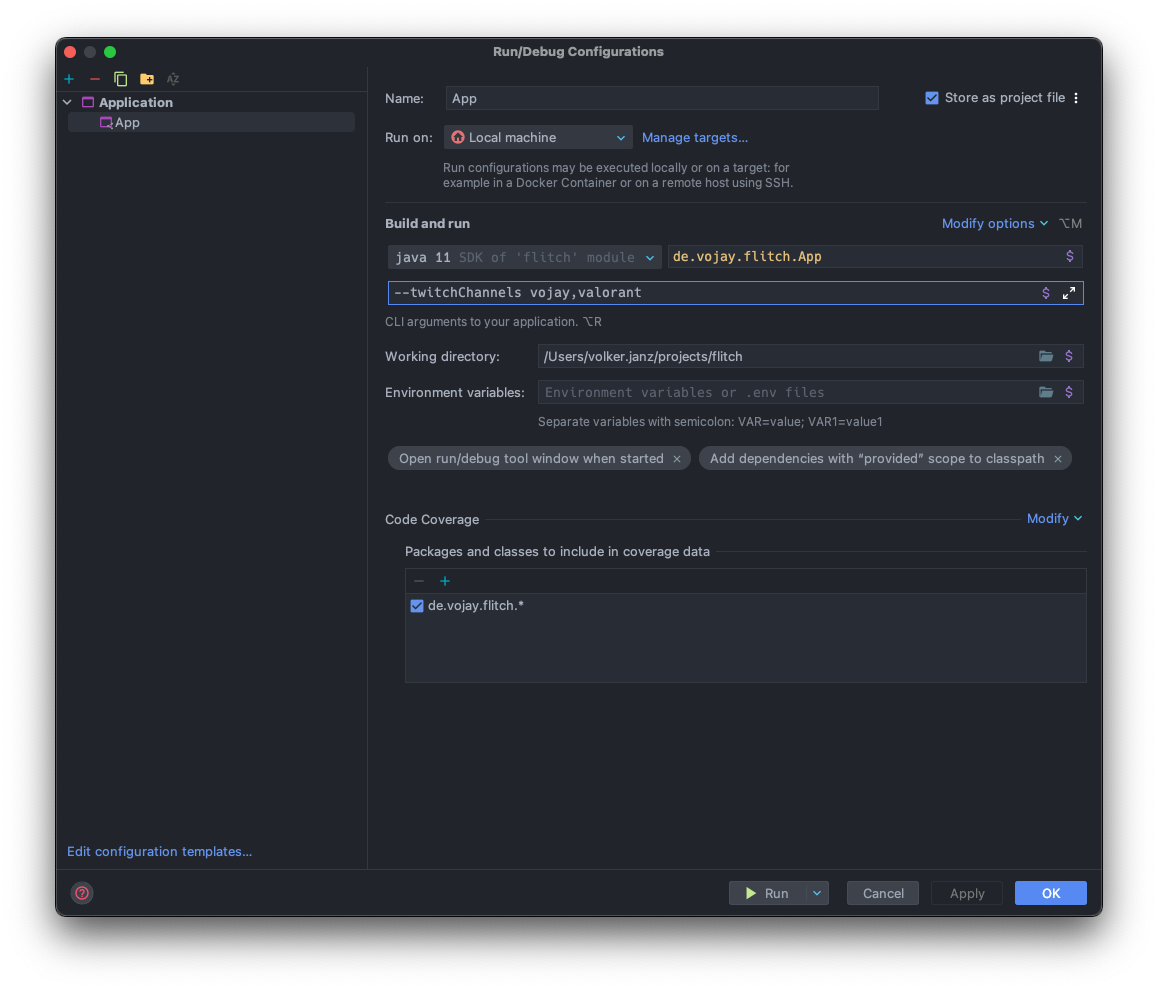
But since we are using IntelliJ, there is also a way to solve it with the run configuration. Click on Run –> Edit Configurations… and then click on the + or Add new to create a new run configuration. From the list, select “Application” and name it “Flitch”.
Ensure to select Java 11 and enter de.vojay.flitch.App as your main class.
To solve the java.lang.NoClassDefFoundError, we now have to enable the option Add dependencies with “provided” scope to classpath.
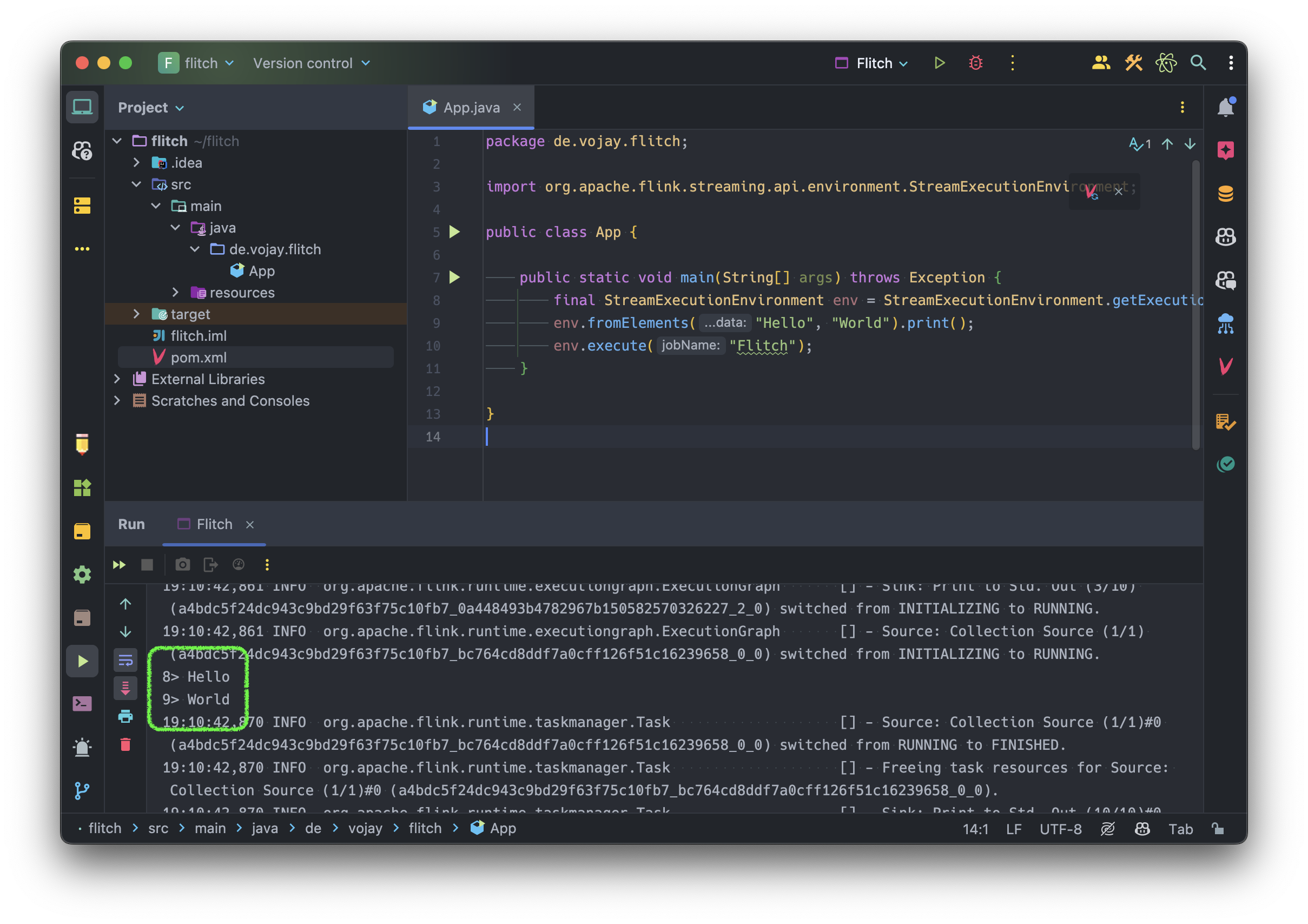
Your run configuration is ready, lets click “Run” and enjoy our first streaming application.
It works 🎉. The streaming application will run until the bounded stream is processed. You will also find the output of the two elements of your stream in the logs.
Local Flink Web UI
There’s still one thing before we turn our attention to the fun part. The Flink Web UI is a user-friendly interface that allows developers and administrators to monitor and manage their Apache Flink applications. It provides a real-time overview of running or completed jobs, displays metrics such as throughput and latency, and offers detailed insights into the job’s execution plan. Essentially, it’s a convenient dashboard where you can visualize the performance and status of your Flink applications, making the process of debugging, optimizing, and managing your streaming or batch processing jobs much easier and more intuitive.
When you run a Flink application locally like in this example, you usually do not have the Flink Web UI enabled. However, there is a way to also get the Flink Web UI in a local execution environment. I find this useful, especially to get an idea of the execution plan before running streaming applications in production.
Let’s start by adding a dependency to the pom.xml:
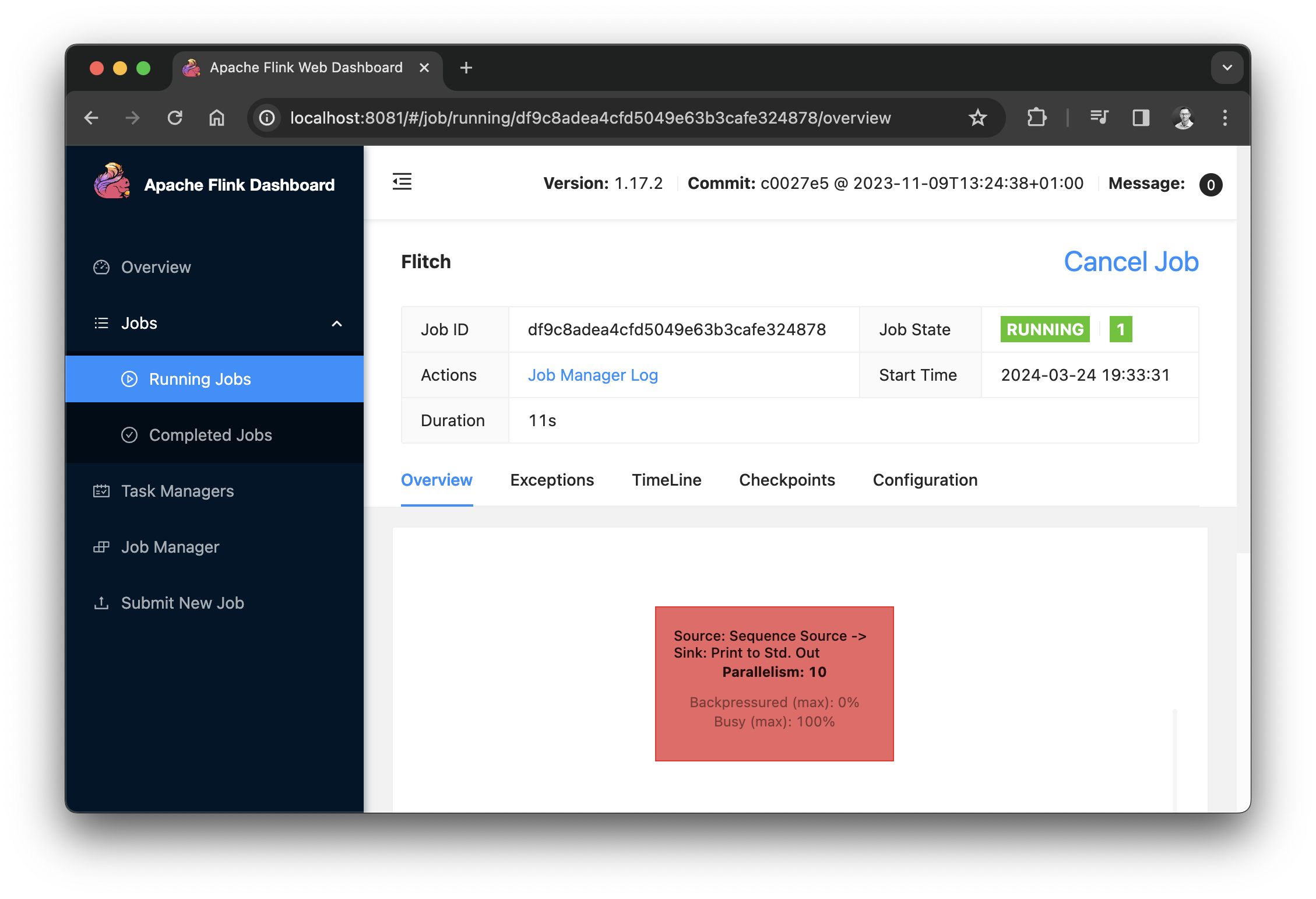
The streaming application will now process a sequence of numbers, so that it will not finish immediately. Also with createLocalEnvironmentWithWebUI we will have the Flink Web UI available locally on port 8081 while the application is running.
Start again and open http://localhost:8081/ in your browser. Apart from various metrics, you can also see the execution plan of your Flink application.
Now we have a proper local setup and can get started connecting our application to Twitch and run sentiment analysis on chat messages.
Read the Twitch chat
Twitch, the leading live streaming platform for gamers, offers a comprehensive API and a chat feature that’s deeply integrated with the Internet Relay Chat (IRC) protocol.
At its core, the Twitch API allows applications to interact with Twitch’s data. This includes retrieving information about live streams, VODs (Video on Demand), users, and game details. The API is RESTful, meaning it follows the architectural style of the web, making it straightforward to use with common HTTP requests. Developers can use this API to create custom experiences, such as displaying live stream stats, searching for channels, or even automating stream setups.
The Twitch chat is a vital aspect of the Twitch experience, allowing viewers to interact with streamers and other viewers in real-time. Underneath the modern interface of Twitch Chat lies the Internet Relay Chat (IRC) protocol, a staple of online communication since the late 80s. This reliance on IRC allows for a wide range of possibilities when it comes to reading and interacting with chat through custom applications.
For our purpose, we simply want to read the chat, without writing messages ourselves. Fortunately, Twitch allows anonymous connections to the chat for read-only application use-cases.
To reduce the implementation effort, we will use an existing library to interact with Twitch: Twitch4J. Twitch4J is a modern Java library designed to simplify the integration with Twitch’s features, including its API, Chat (via IRC), PubSub (for real-time notifications), and Webhooks. Essentially, it’s a powerful toolkit for Java developers looking to interact with Twitch services without having to directly manage low-level details like HTTP requests or IRC protocol handling.
We would like to have a lightweight, serializable Plain Old Java Object (POJO) in order to represent Twitch chat messages within our application. We are interested in the channel where the message was written, the user and the content itself.
Create a new class TwitchMessage with the following implementation:
As a side note: You do not have to write basic functions like toString() on your own, you can use IntelliJ to generate it for you. Simply click on Code –> Generate… –> toString() to get the result above.
Create custom Twitch source function for Flink
We will now use Twitch4J to implement a custom Twitch source function for Flink. The source function will generate an unbounded stream of data, in this case Twitch chat messages. That also means, the application will not terminate until we explicitly stop it.
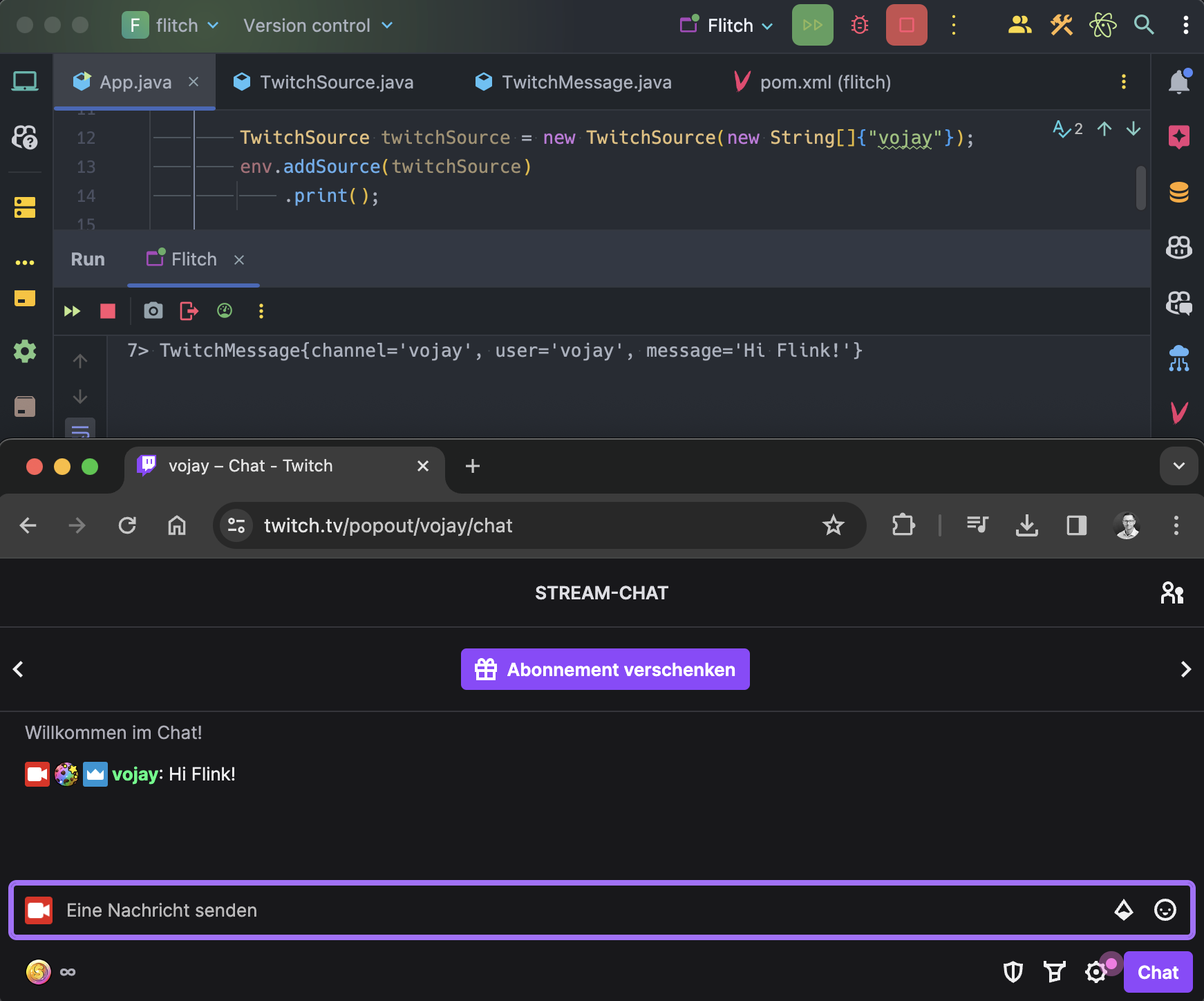
With this example we get a client that joins the Twitch channel called vojay. Yes, I once was an active streamer myself. Fun fact: I teached people game development and general software development in my streams. I also enjoyed playing retro games live on stream 🎮. But that is a different topic, let’s focus on the project 😉.
You should also notice, that there is no authentication in the example above. As said before, since we only want to read the chat, no authentication is needed. In fact, we simply join an IRC chat anonymously and read the messages.
Since we want to establish the connection to the Twitch chat only once per source instance, we have to extend the abstract RichSourceFunction class, in order to be able to override the open function, which allows to add code for initialization.
With that, we have all we need to consume messages and emit them for further processing as a stream of data.
The run function of a source function is where the magic happens. Here we generate the data and with a given SourceContext, we can emit data.
The SimpleEventHandler provided by Twitch4J can be used to react on specific messages.
Whenever we get an event of type IRCMessageEvent, which is a message in the Twitch chat, we generate an instance of our POJO and emit it to the stream via the context.
To ensure our source function does not terminate, we will add a loop with an artificial delay, which will run until our boolean variable running is set to false. This will be done in the cancel function, which is called by the Flink environment on shutdown.
With addSource we can add our source function. The elements are then processed by the next step in the stream, which is print(). With this sink, we will again output each element to STDOUT.
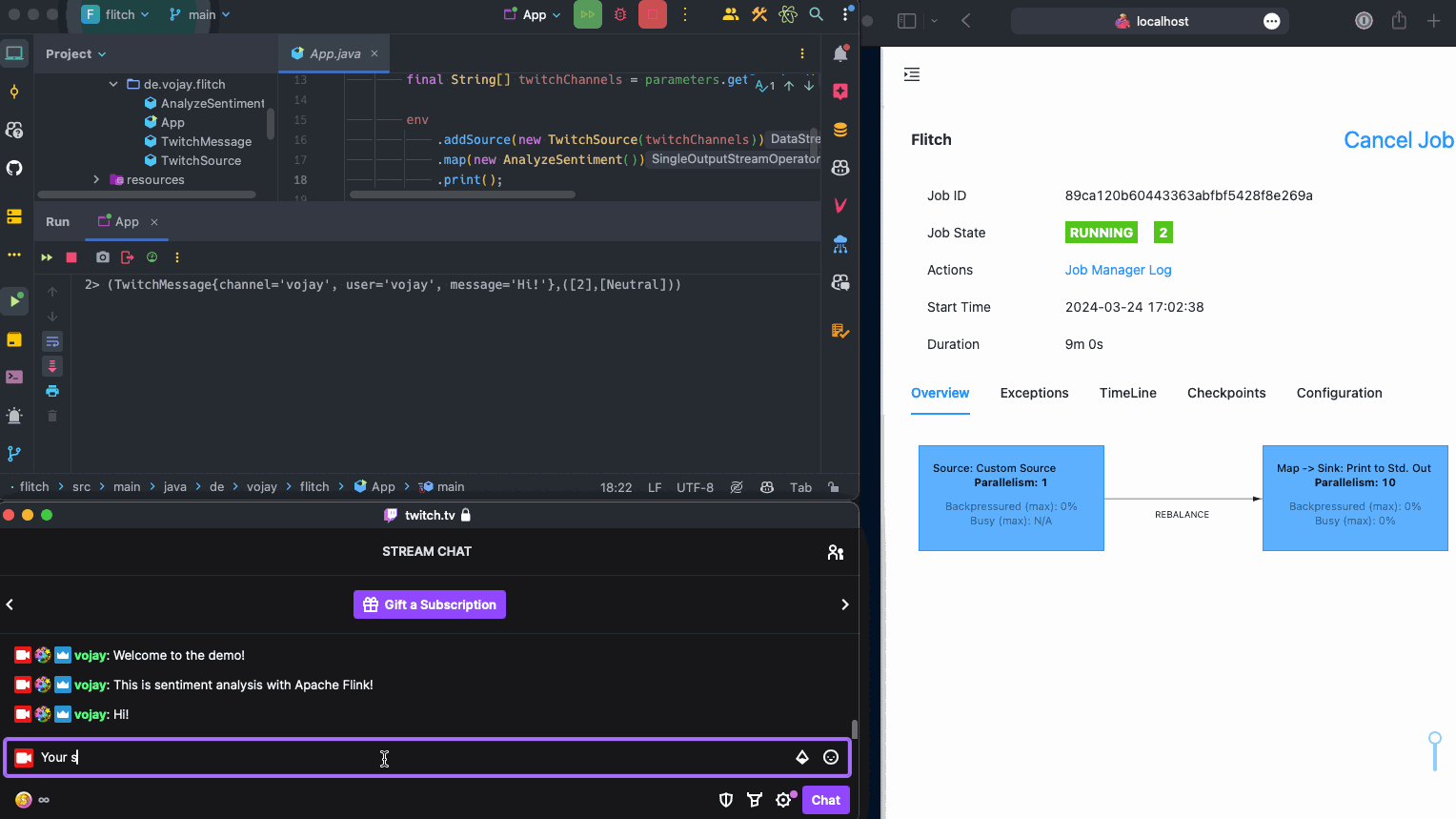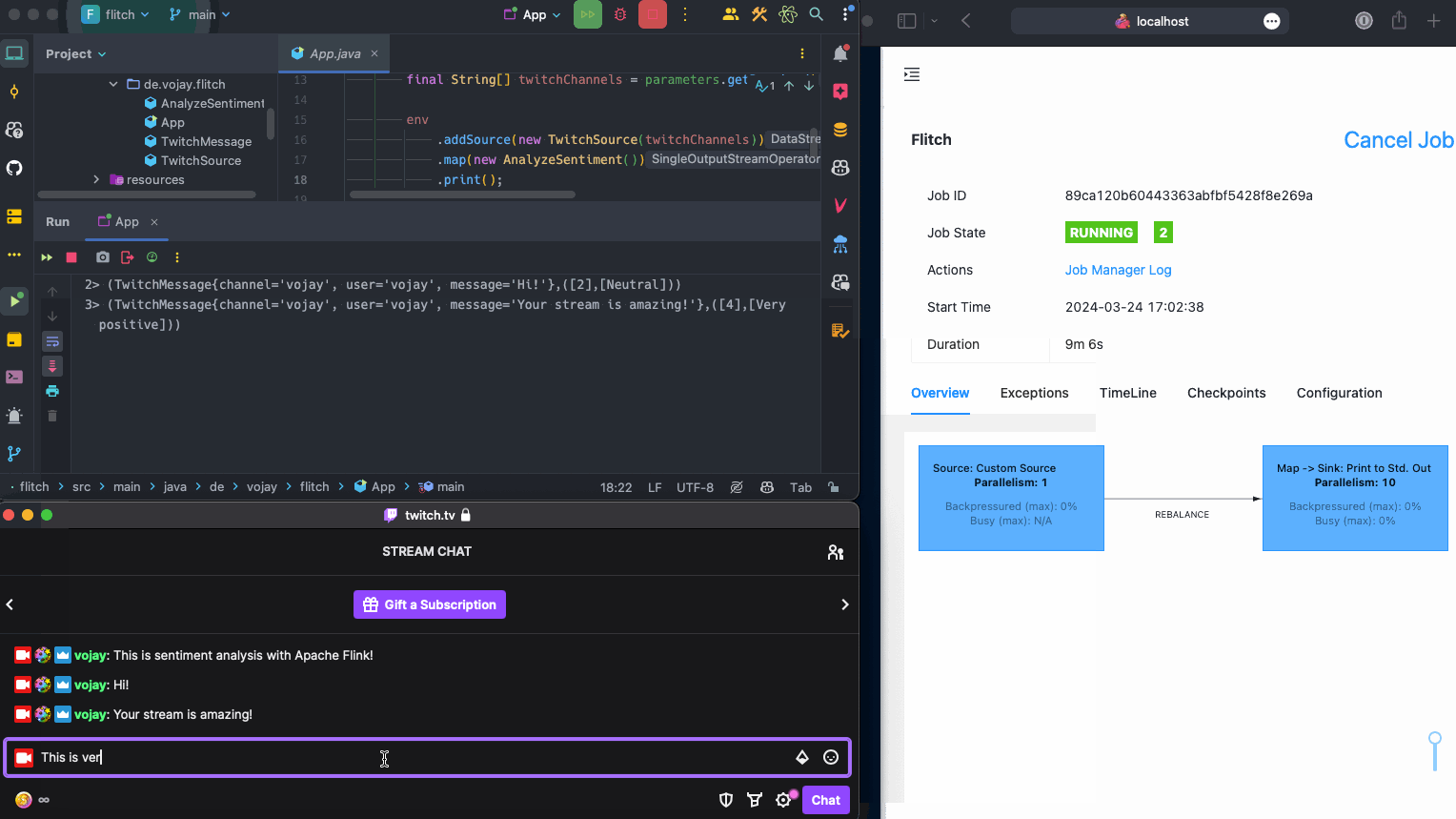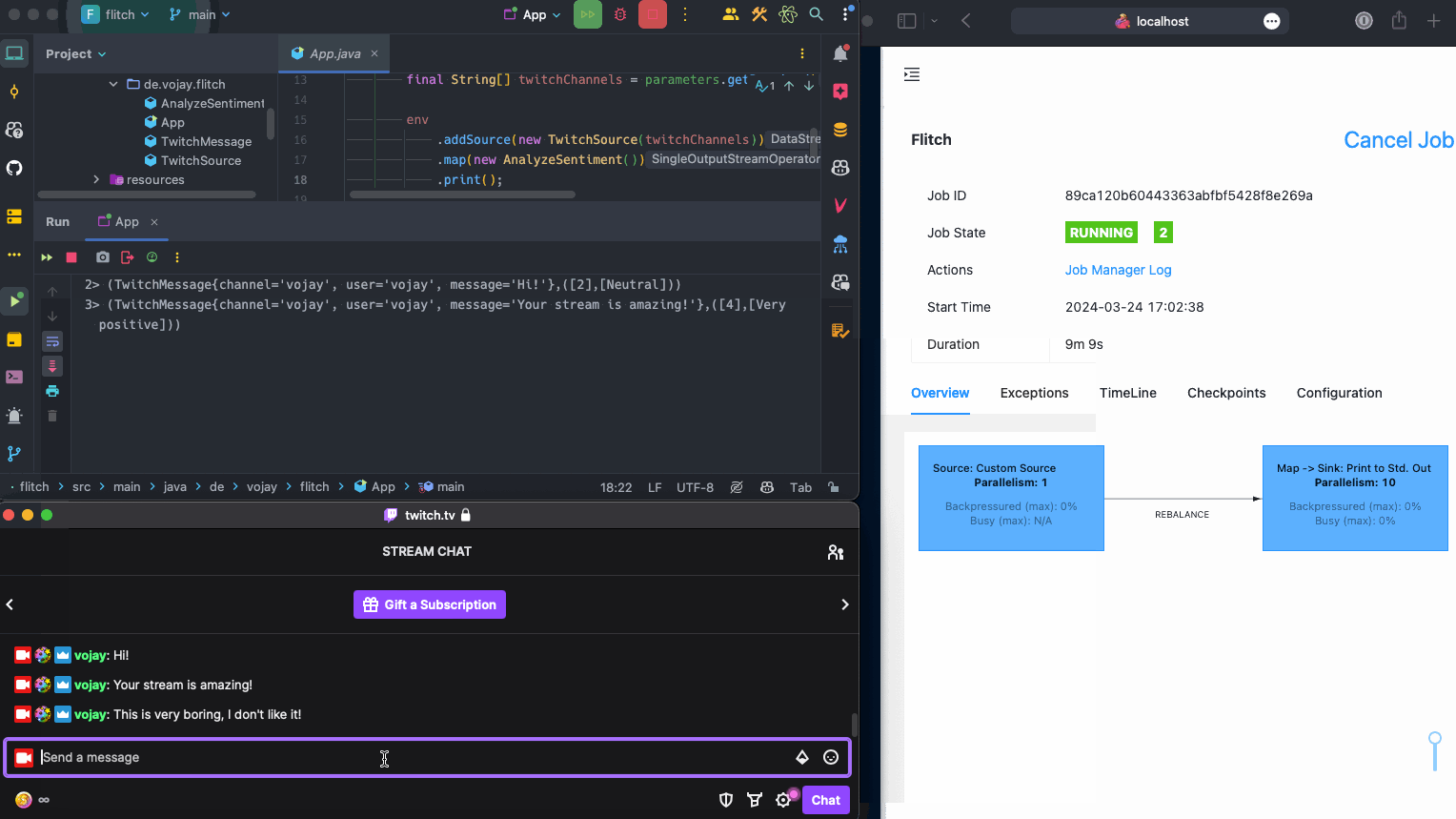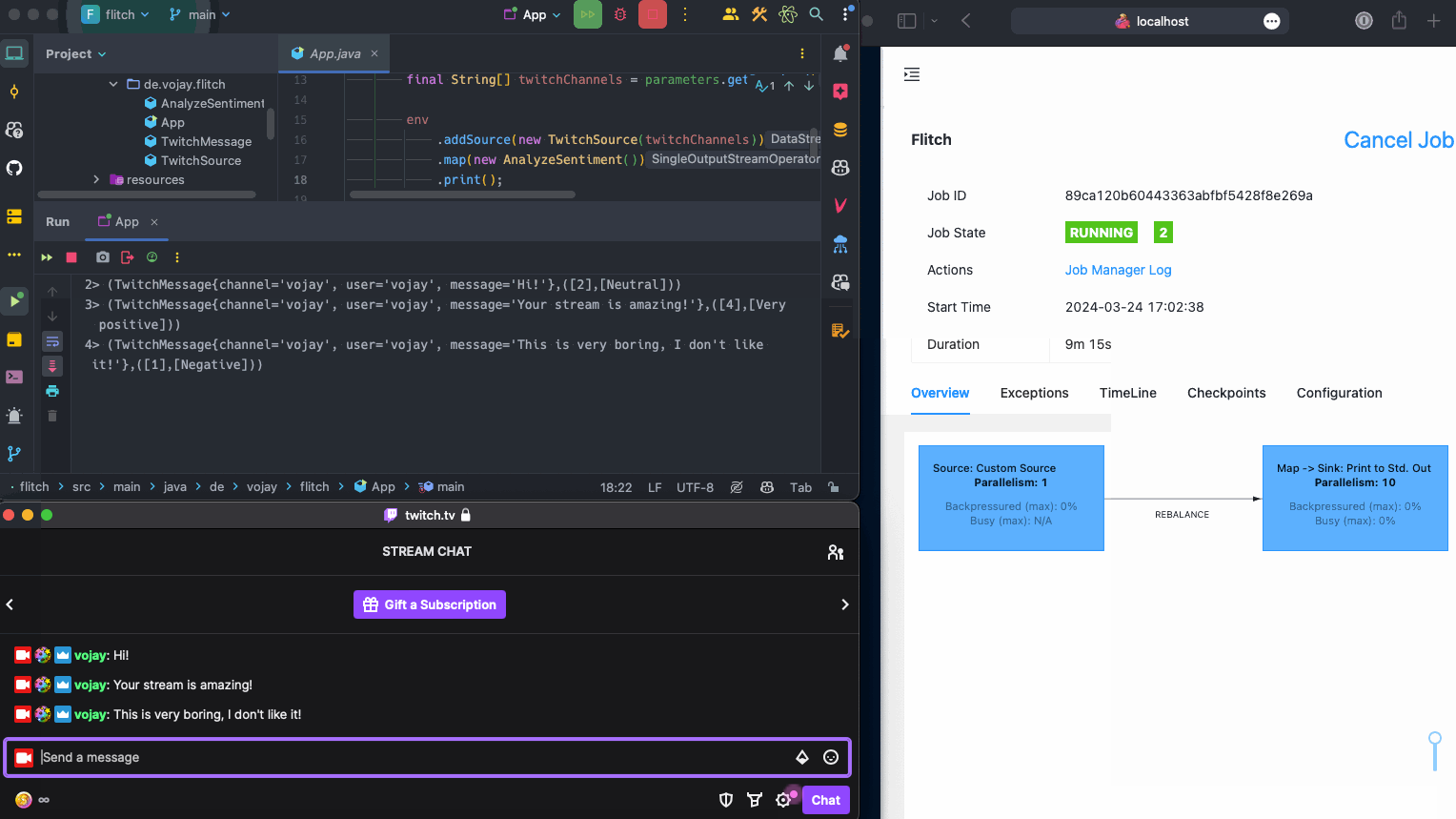
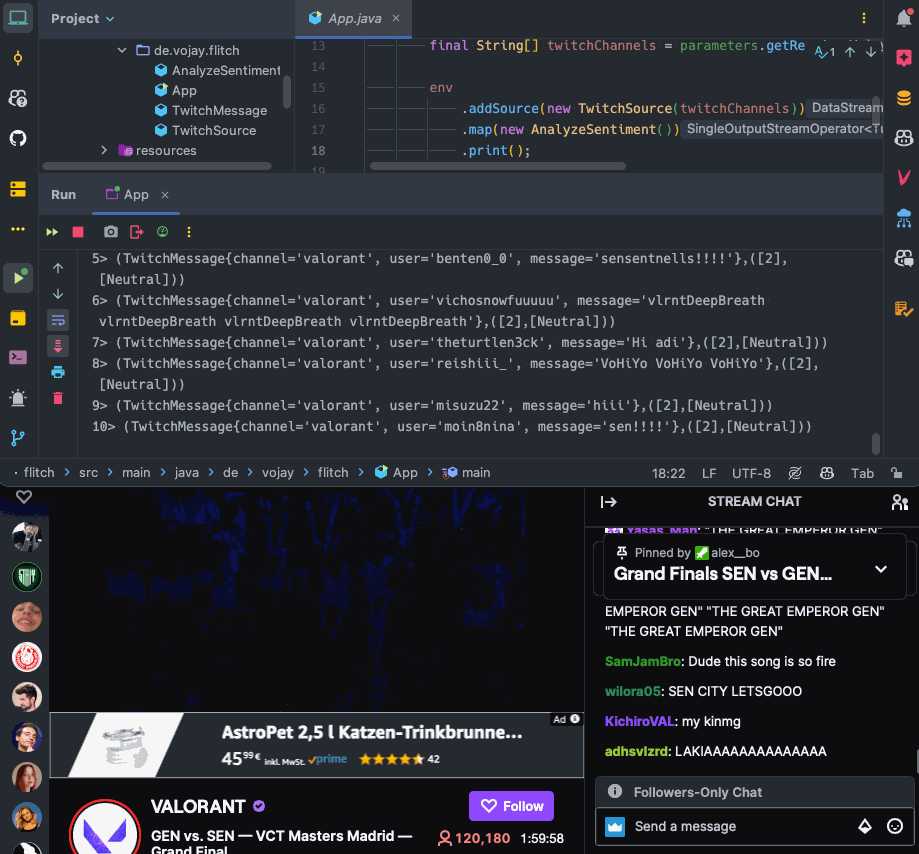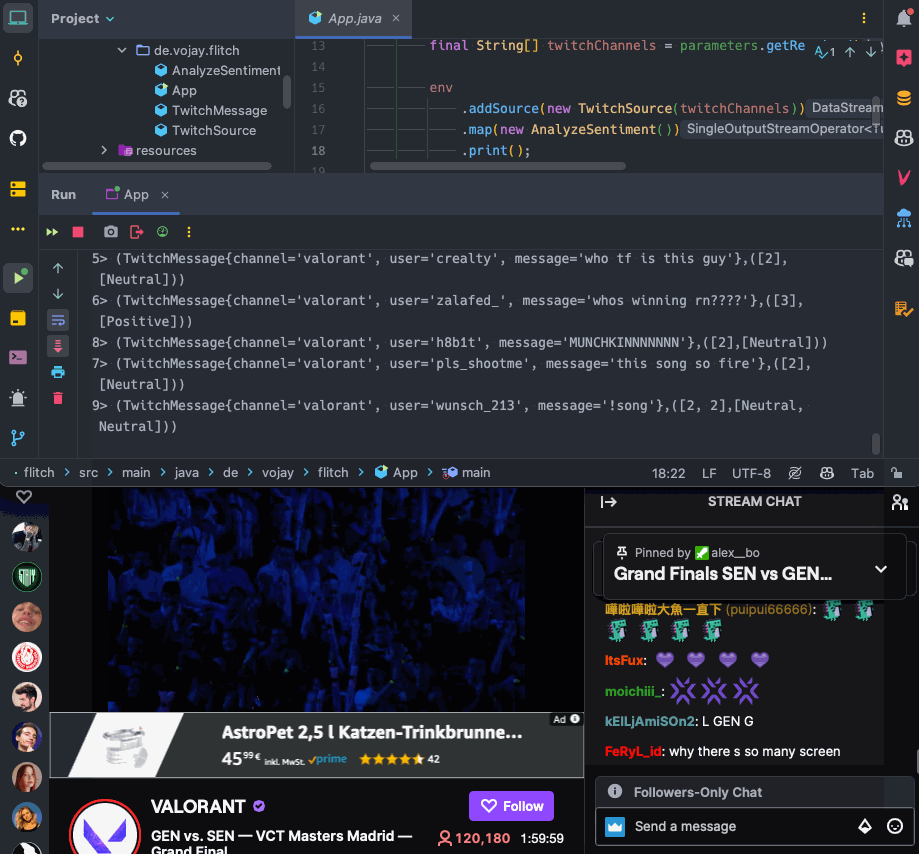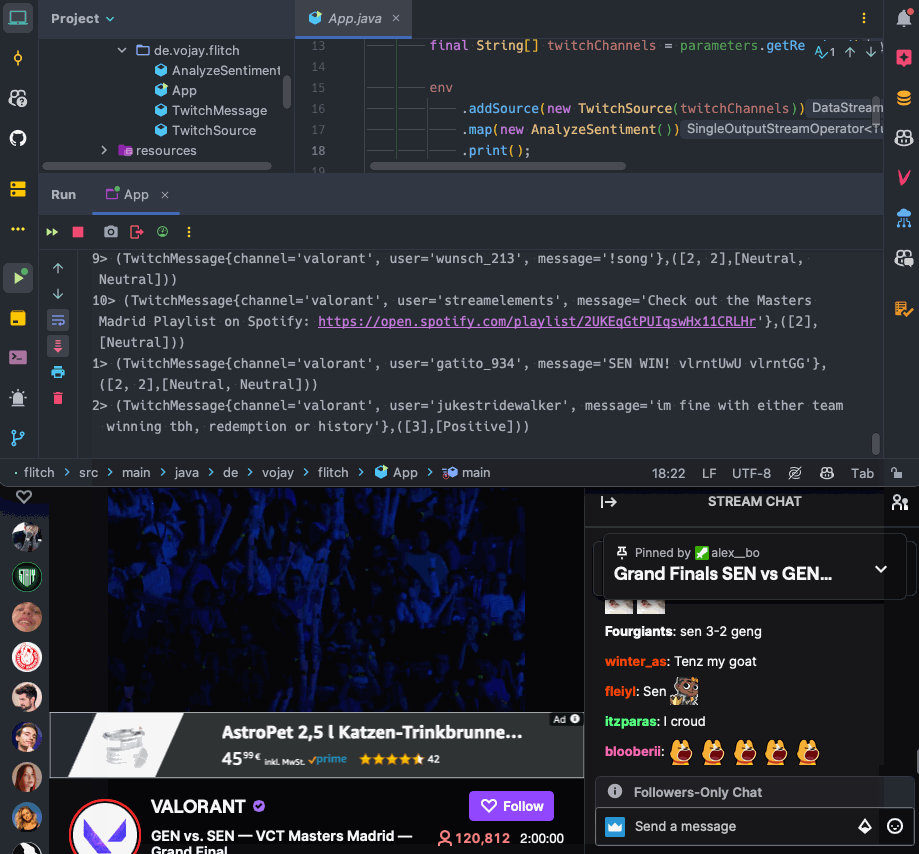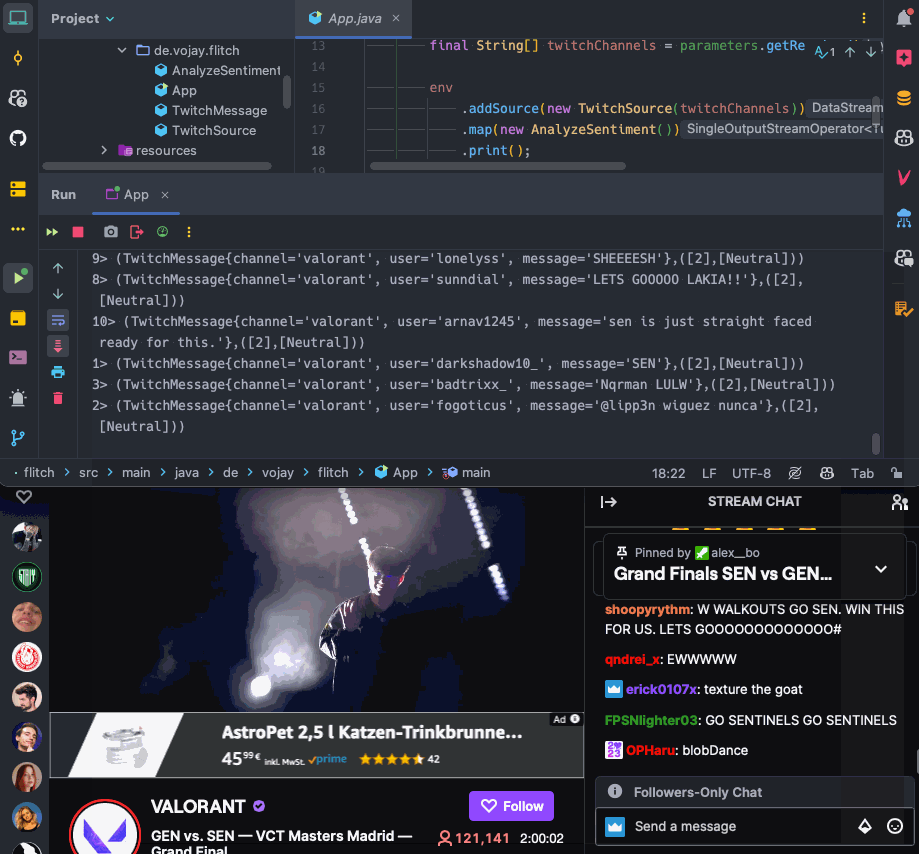
When running the application now and writing to the chat at https://twitch.tv/vojay, the messages will be processed and printed by our streaming application 🎉.
Twitch chat sentiment analysis
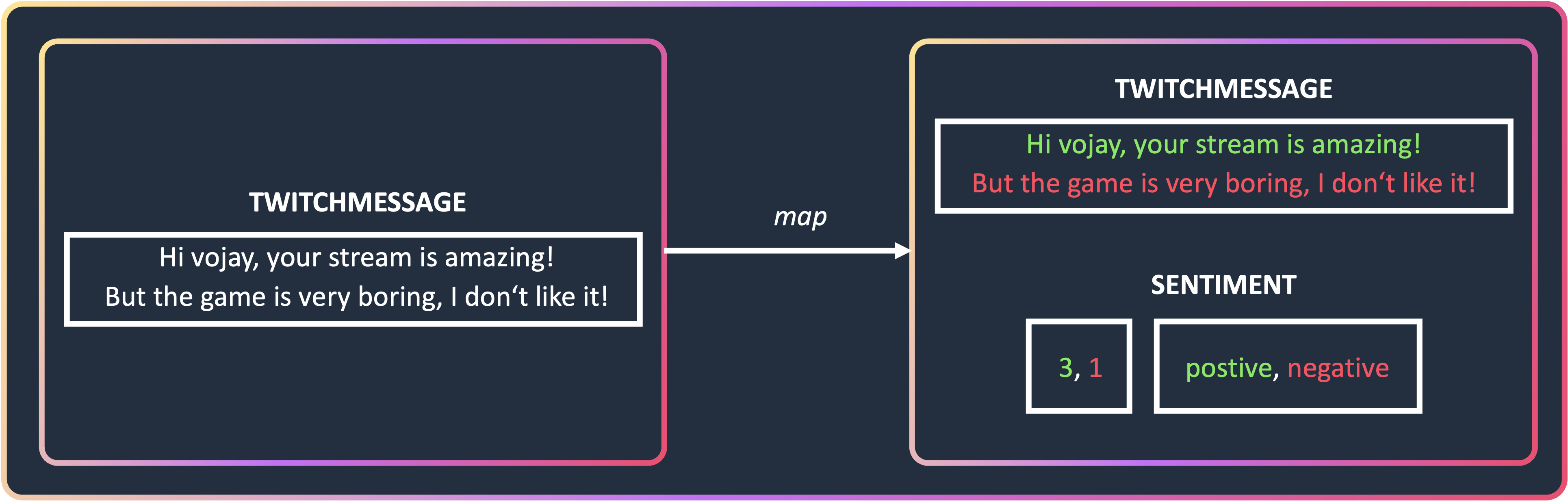
Now that we can read the Twitch chat as a stream of data, it is time to process each message. The basic idea is: for each Twitch message, we detect the individual sentences of the message and calculate the sentiment for each of the sentences. The output will be a structure like this:
Let’s break it down: the result contains the original POJO of the Twitch chat message together with another tuple with 2 elements:
A list of sentiment scores (List<Integer>) containing the score for each sentence in the message, from 0 (very negative) to 4 (very positive) and
a list of sentiment classes (List<String>) containing the readable class for each sentence in the message, for example: Neutral or Negative.
Add Stanford CoreNLP dependencies
To perform the sentiment analysis, we will use the CoreNLP library by the Stanford NLP Group. There are alternatives like Apache OpenNLP or the Deep Java Library. In this project, we will focus on CoreNLP but feel free to create alternative versions using one of the other libraries, which can be a great way to learn more about it.
CoreNLP is a comprehensive tool for NLP in Java, supporting multiple languages including Arabic, Chinese, English, French, German, Hungarian, Italian, and Spanish. It processes text to provide linguistic annotations such as sentence boundaries, parts of speech, named entities, and more through a pipeline system that generates CoreDocuments. These documents hold all annotation information, which can be accessed easily or exported.
In the context of CoreNLP, a pipeline is essentially a sequence of processing steps designed to analyze text. When you input raw text into CoreNLP, the pipeline passes the text through various annotators (processing units), each responsible for a different aspect of NLP. These annotators might identify sentence boundaries, recognize parts of speech, detect named entities, parse sentence structures, and more, depending on the specific tasks you want to perform.
In our case, we will use the sentences annotation to split the Twitch message into sentences and then use the sentiment core annotations on each sentence to get the sentiment of it. But first, we need to add the required dependencies to the pom.xml of our project:
The first dependency represents the library itself while the second dependency will fetch all the related pre-trained models into your local .m2 folder. Don’t be surprised, the first time Maven resolves the dependencies will take a while due to the download of the models.
Create sentiment analysis map function
For the map function, we will use the abstract class RichMapFunction as a basis, so that we can again override the open function in order to initialize the pipeline for sentiment analysis only once per instance. When extending the RichMapFunction, we need to specify to generics, one for the type of input and another one for the type of output. The input will be one Twitch message POJO, so TwitchMessage and the output will be the message again together with its sentiment in form of a list of scores and another list of classes, as described before.
Let’s start by creating a new class called AnalyzeSentiment and extend the RichMapFunction:
When initializing the Stanford CoreNLP pipeline, we have to specify the types of annotators we want to use in our pipeline, so that the library only loads the required models. This can be achieved via a Properties object, passed to the constructor of StanfordCoreNLP. This is how we initialize the pipeline for our use-case:
To make our map operator more readable, we extract the core logic to get the sentiment to a dedicated function. We start by processing the message with the pipeline:
We now have all ingredients for our real-time sentiment analysis streaming application 🚀. That means, we can switch back to our App class, where we define how the streaming application looks like.
Here, we will also introduce another useful Apache Flink feature, which is the ParameterTool. A generic helper class allowing to parameterize your application in different ways. We will use it to add a program argument --twitchChannels that allows to pass a comma-separated list of Twitch channels we want to use in our TwitchSource:
Before we run it again, we need to adjust our run configuration again by adding the new --twitchChannels parameter. As we marked it as required, the application would fail otherwise. Navigate to Run –> Edit Configurations… and add:
--twitchChannels vojay,valorant
as program arguments. You can use any Twitch channel here, feel free to browse Twitch for bigger channels and see what happens.
Now it is time to run your streaming application again and enjoy the show!
Conclusion
And there you have it! We’ve built a real-time sentiment analysis application for Twitch chat using Apache Flink. Now you can not only see the chat flow by, but also understand the emotional pulse of the audience. This might be the boilerplate for a more advanced version. Track the sentiment throughout a stream, see how the viewers react to big plays or funny moments, and use that knowledge to create even more engaging content.
Some inspiration to turn this prototype into a valuable, production-ready project:
⚙️ Adjust model
Use a model that is trained specifically on social media data (e.g., RoBERTa) or even better, train a model directly with historical Twitch chat data to incorporate Twitch-specific communication aspects like specific emoji codes.
🧮 Apply windowing
Extend the Flink pipeline with a window function, for example, a tumbling window per minute, and aggregate the sentiment score as an average per minute.
📦 Persist results
Persist the resulting stream with an aggregate per minute in Kafka or a Time Series Database (TSDB).
📊 Create dashboard
Create a dashboard on the aggregated data, visualizing the average sentiment per minute in a graph.
With these suggestions, you can combine the result with other metadata, like the actual category/game played of the stream or the time of the day, to create sophisticated recommendations about what content results in a positive Twitch chat experience.
So, the next time you tune into your favorite streamer, keep an eye out for that sentiment analysis running in the background. It might just reveal some fascinating insights about the passionate world of the Twitch chat!
But the most important thing about this article is: get inspired, learn and inspire others. The cool thing about Data Engineering and related fields:
data is everywhere
so there is always the next interesting question around the corner that can be used to learn and ideally share your inspiration with others.
Enjoy and let me know about your experiences in the comments ✌️.
Effective AI implementation relies not only on the quantity of data but also on technical expertise. Let's explore the significance of having a skilled data team for AI projects, learn about the Small Data movement and examine how far we can go with no-code or low-code AI platforms.
Netflix Maestro and Apache Airflow - Competitors or Companions in Workflow Orchestration?
Explore how Netflix Maestro and Apache Airflow, two powerful workflow orchestration tools, can complement each other. Delve into their features, strengths, and use cases to uncover whether they are companions or competitors.
Minds and Machines - AI for Mental Health Support, Fine-Tuning LLMs with LoRA in Practice
Explore the potential of Large Language Models (LLMs) changing the future of mental healthcare and learn about how to apply Parameter-Efficient Fine-Tuning (PEFT) to create an AI-powered mental health support chatbot by example


 Maven Archetype for Flink
Maven Archetype for Flink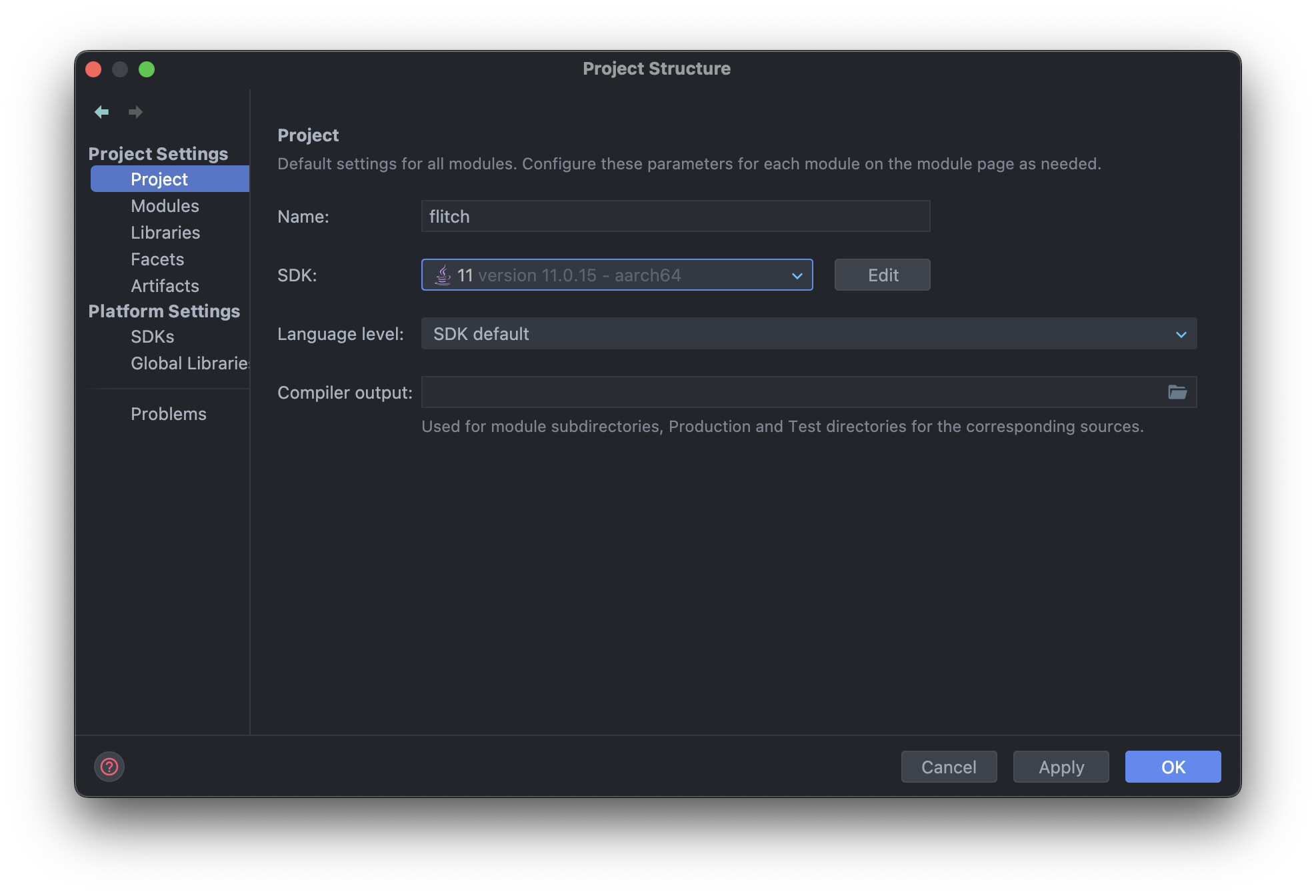

 Twitch4J logo, source:
Twitch4J logo, source: 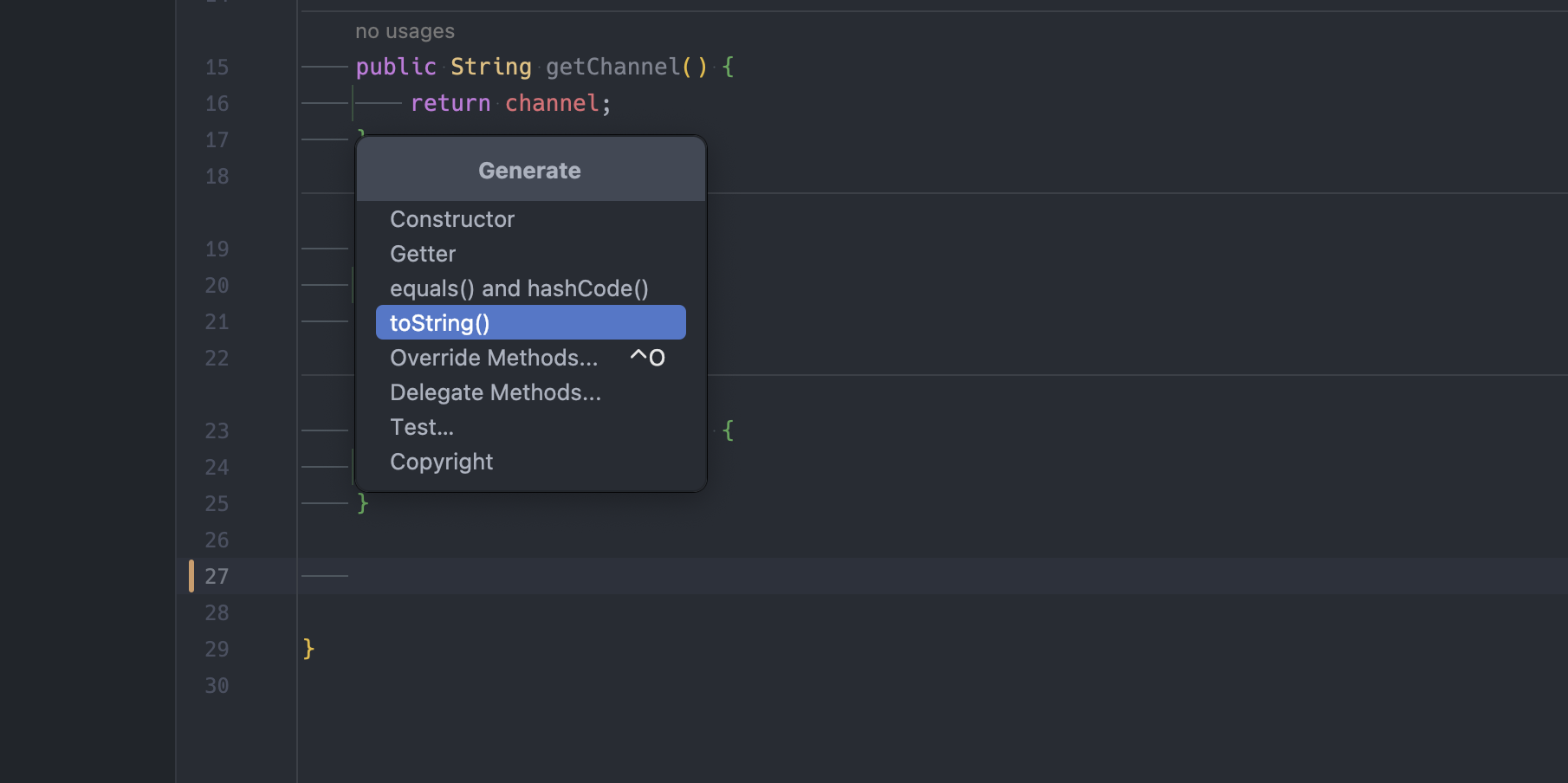





{kind=link}