Recently, Gunnar Morling, a Software Engineer at Decodable and an open-source enthusiast, who also regularly releases Checkpoint Chronicle, a monthly roundup of interesting topics in the data and streaming community, posted an intriguing question that inspired this article.
The task
Gunnar asked the following, inspiring question on X:
"How do you build a service which needs to persist a record in a database and store a corresponding file in S3?"--Someone asked me this, and I think it makes for a great SWE technical interview question. You can discuss design considerations, failure modes, testing, etc.
Certainly, this question is excellent for sparking technical discussions during interviews. However, I’d like to approach it from a different angle.
Throughout my career, I’ve learned from many talented individuals and am grateful for the challenges we’ve tackled together. One lesson, from a respected colleague, emphasized the importance of asking the Spice Girls question in such situations. You might wonder, “What is the Spice Girls question?” — I assure you, it will resonate once I explain. The Spice Girls question is:
So tell me what you want, what you really, really want
This question delves into the underlying motivation, the WHY? — the ultimate problem the stakeholder would like to solve. Before start working on any project, I recommend clarifying three questions for yourself and your team:
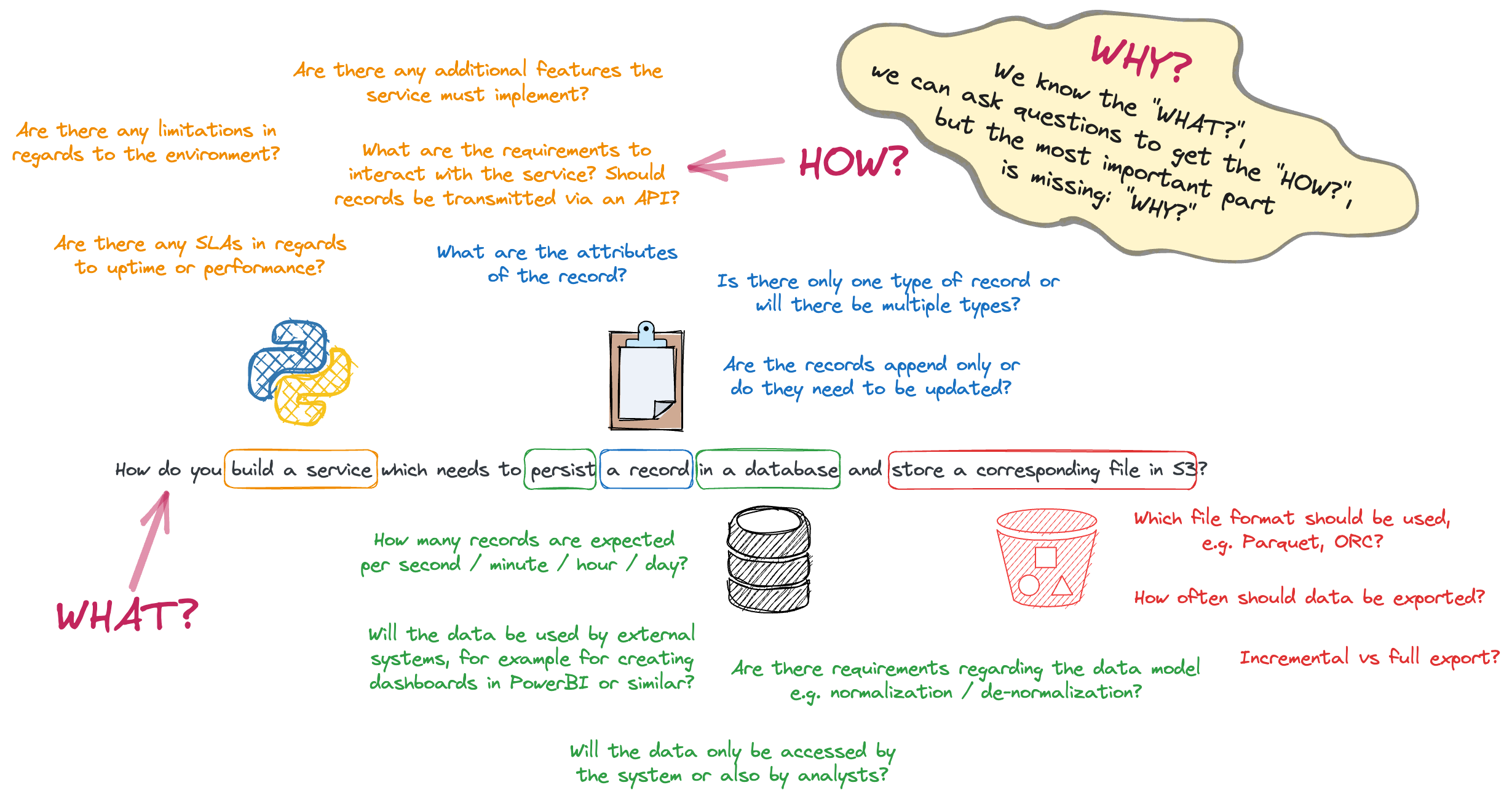
How do you build a service which needs to persist a record in a database and store a corresponding file in S3?
We can then break down the task into components and ask questions about each of them to clarify the HOW?:
… build a service …
Are there SLAs regarding uptime or performance?
What additional features must the service implement?
What are the requirements for interacting with the service?
Should records be transmitted via an API?
Who will use this service?
Will records be transmitted individually or in batches?
… a record …
What does a record look like? What are its attributes?
Are records append-only or updatable?
Are there multiple types of records?
… persist … in a database …
What is the expected volume of records per second/minute/hour/day?
Will the data be used by external systems (e.g., for dashboards)?
Are there data model requirements (e.g., normalization)?
Will data be accessed directly by analysts?
Are there specific requirements for Consistency, Availability, or Partition tolerance (CAP)?
… store a corresponding file in S3 …
Which file format should be used (e.g., Parquet, ORC)?
How frequently should data be exported?
Is it an incremental or full export?
There are many more questions, for example regarding testing, transaction handling, duplicates, failure recovery and more, but all of them aim to clarify the HOW?.
However, without understanding the initial problem, we lack clues about the WHY?.
And that should be the first thing to clarify. Let’s stick to this approach and explain why we should start with WHY?.
Imagine a stakeholder presents you with the task, and as you keep asking WHY?, you eventually receive the answer:
I want the file in S3 so I can easily download the data to my laptop and share it in our management Slack channel every Monday.
Following up, you might suggest automating this process by extending the service to fetch and post the data to Slack via a bot every Monday. Voila! By understanding the WHY?, you’ve streamlined the solution, eliminating the need to store files in S3.
Starting with WHY? often leads to simpler and more efficient solutions.
Moreover, knowing the WHY? can boost intrinsic motivation. For instance, imagine you get the following answer instead:
We need to collect and export this data to S3 to share it with our external partner, a famous print magazine publisher. Your work will soon be featured in this magazine! We can even give a team shoutout.
Understanding the WHY? can inspire greater dedication to solving the problem. It’s more motivating to know why you’re providing a service rather than simply fulfilling a task.
There are also ways to support gathering this information. For instance, using project management or task tracking software like Jira, you can require filling out specific templates when creating tickets:
I need (what?):
Because (why?):
The results of this ticket will be accepted when (acceptance criteria?):
This process underlines another essential lesson: leave the HOW? to the technical experts. Ideally, stakeholders present a clear problem without dictating the solution.
Agreeing on acceptance criteria ensures that your solution delivers the desired business value.
In summary, I would respond to Gunnar’s query with the Spice Girls question:
So tell me what you want, what you really, really want
Then break down the task into components, and clarify the HOW? with follow-up questions.
Ultimately, it all boils down to one key aspect:
Communication is key
Of course, in an interview setting, this question is intended to inspire technical discussions with the candidate about design considerations, failure recovery, the pros and cons of different frameworks and solutions, testing, and more. However, I think it’s valuable to demonstrate an understanding of how to approach these situations in real-world scenarios to ensure that your solutions have a real business impact.
Creating valuable software is about not only solving technical puzzles but also understanding their broader implications for the organization.
Keep it simple
With the rise of Big Data and the increasing volume, speed, and diversity of data, along with the expanding landscape of major cloud providers and the growing hype around AI, there’s a common tendency to overcomplicate solutions right from the start. The attraction of cutting-edge technologies often leads us to adopt complex architectures prematurely, sometimes forgetting about simpler and more efficient approaches. It’s important to balance the use of advanced technologies with practicality, scalability, and alignment with business objectives.
People are often surprised how much data wrangling can be done with a simple Bash script, without relying on frameworks, cloud technologies, or complex systems 😉.
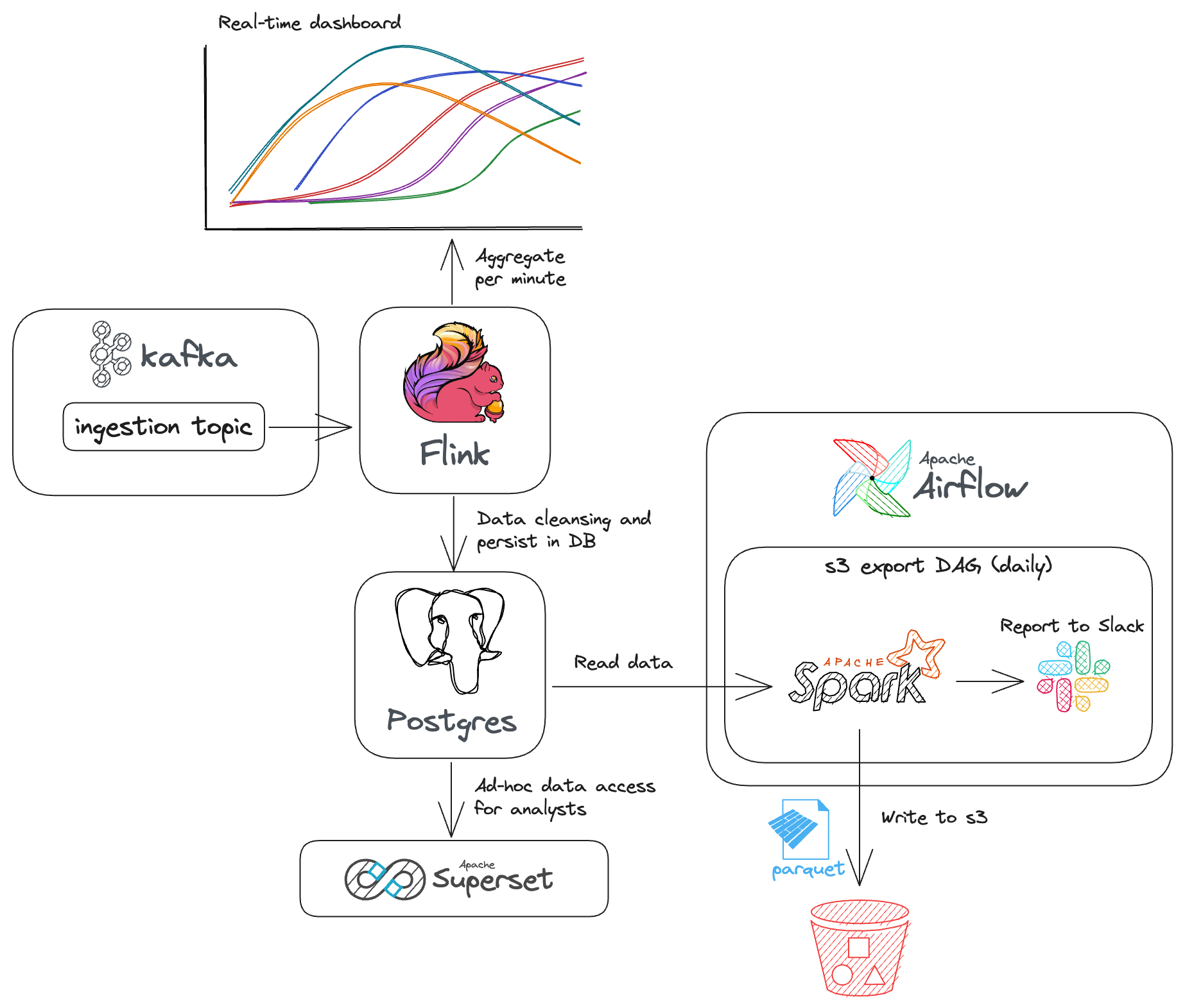
We might consider tackling the problem using dedicated, distributed technologies for each aspect. For instance, we could ingest data into a Kafka topic, then process this data with a Flink job to aggregate it by minute intervals for a real-time dashboard, while also persisting records in a PostgreSQL database. We could configure this database as a data source in Superset to enable ad-hoc data access. Additionally, we could set up a DAG in Airflow to trigger a Spark job that reads data from PostgreSQL and writes it to the desired S3 bucket in Parquet format. As part of the DAG, a Slack notification could be sent upon completion of the export.
This solution offers several advantages, including scalability at all levels, extensibility, and additional features to enhance data usability. However, it also has a significant drawback: complexity. We must consider testability at each stage and as a holistic system. Features like a real-time dashboard may seem appealing, but are they truly necessary? What if they are rarely used, or if the system is shut down shortly after deployment—was the effort worthwhile? Moreover, how long will it take to get everything operational? What if stakeholders realize later that the solution does not adequately solve the problem?
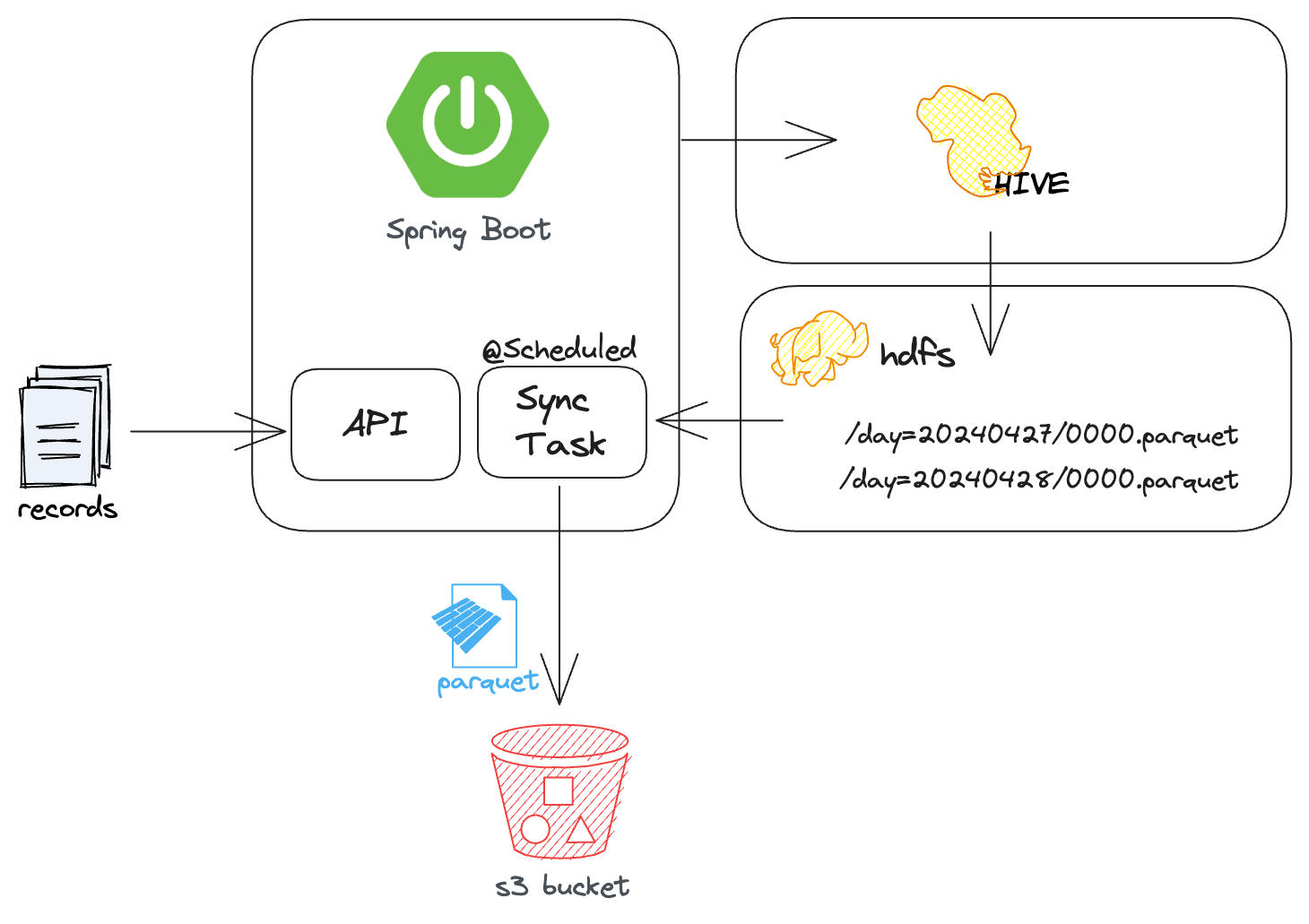
Another approach could involve developing the service using Spring Boot, with an API that accepts records and writes them to a Hive table persisted in HDFS within a Hadoop cluster. This Hive table could be partitioned by day and utilize Parquet as the storage format. Additionally, we could implement a scheduled task within our service using annotations to periodically synchronize the latest file from HDFS to S3.
We could also consider leveraging more cloud-centric technologies. For instance, using Amazon Redshift with an external table to store data directly in S3 (cool solution btw 😉) , or utilizing Google Cloud with Cloud SQL or Cloud Spanner to export data to Google Cloud Storage (GCS) and then synchronize it with the S3 bucket using gsutil.
We can also discuss how to handle transactions across the involved components. What about exactly once or eventual consistency? How does that connect to the initial requirements?
The possibilities are numerous, and don’t get me wrong—each of these approaches is fascinating to discuss, especially in an interview setting. I would be eager to engage in discussions or implement such solutions, given their technological complexity and appeal.
However, my point is that we often gravitate towards complexity, whereas there’s a certain beauty in simplicity and pragmatism. Let’s strive to keep our solutions straightforward.
Can a duck solve the issue?
So, what does a pragmatic solution look like? Without addressing the WHY? and HOW? questions discussed in the earlier chapters of this article, there’s no definitive answer. That’s the beauty of the question—it allows us to make assumptions and craft hypothetical solutions based on our understanding.
Therefore, let us see if a duck can solve the issue 🦆.
In fact, let’s try to combine the following key technologies:
Poetry serves three main purposes: building, publishing, and tracking projects. It provides a deterministic way to manage dependencies, share projects, and monitor dependency states. Additionally, Poetry handles the creation of virtual environments, simplifying development workflows.
FastAPI is a Python framework designed for rapid API development. It leverages open standards, offering a seamless experience without requiring new syntax. With features like automatic documentation generation, robust validation, and integrated security, FastAPI accelerates development while ensuring optimal performance.
DuckDB can be likened to the Swiss Army knife of databases. It’s easy to install, portable, and open-source. DuckDB boasts a rich SQL dialect and supports data import/export in various formats like CSV, Parquet, and JSON. It seamlessly integrates with Pandas dataframes and can store data locally without the need for complex server-client connections. Its portability allows for simple data storage in a local file.
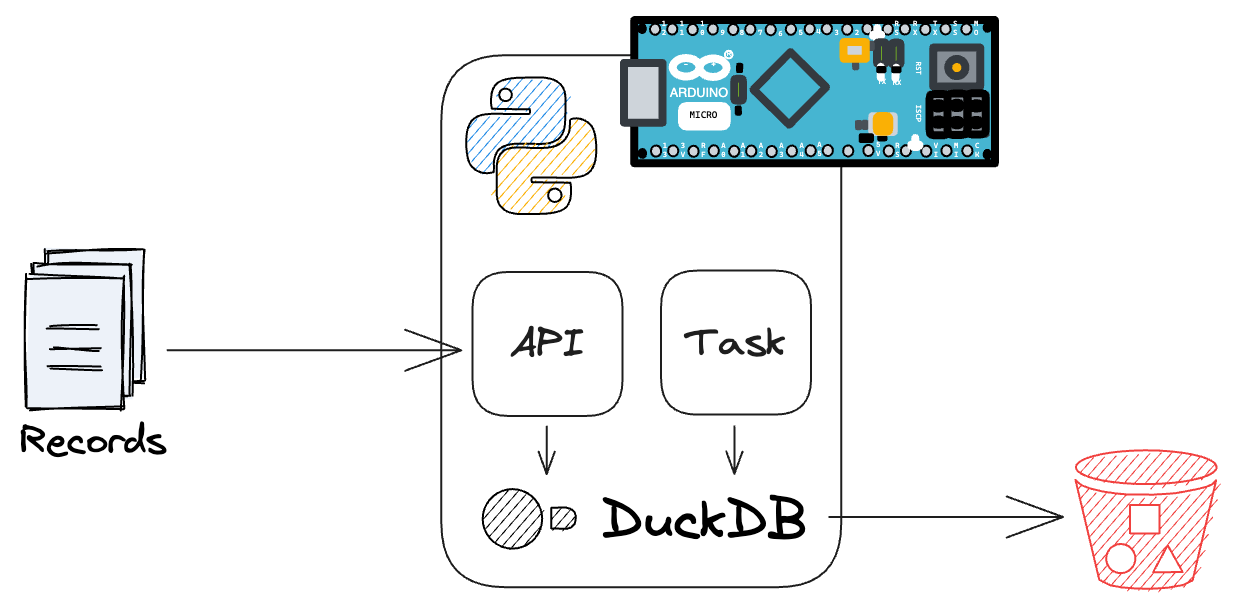
Here’s the concept: we utilize Poetry for Python project management, FastAPI for API-based data ingestion, DuckDB for data storage and S3 export. This streamlined setup consolidates everything into a single service, suitable even for a Raspberry Pi environment thanks to DuckDB’s embedded database capabilities. The service facilitates easy end-to-end testing without additional ecosystem dependencies, enabling stakeholders to swiftly adopt and utilize the solution. While more complex solutions may emerge later, this approach offers an early proof of concept and generates value promptly.
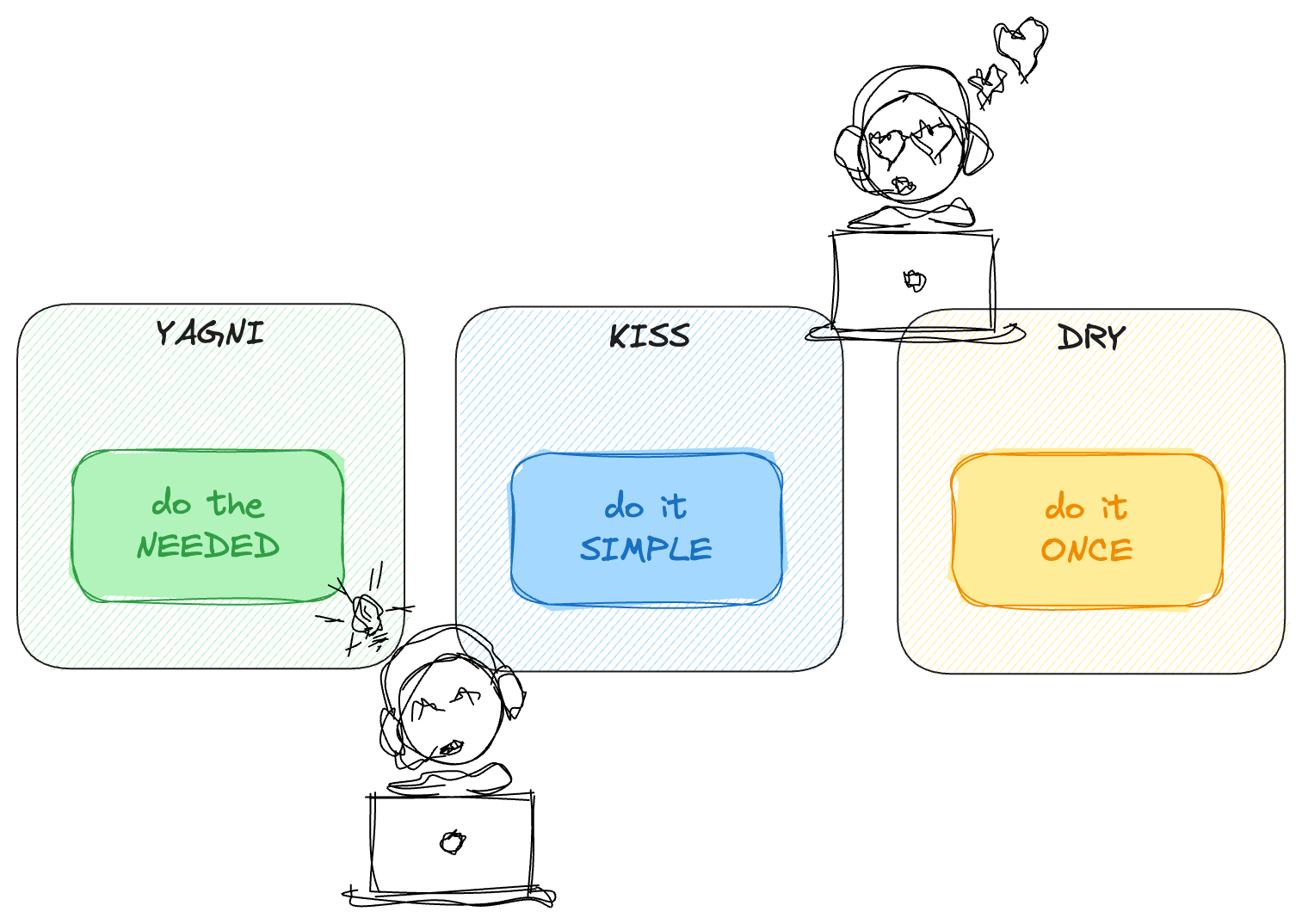
While this may not represent an ideal solution, especially depending on the data volume, the focus is on pragmatism, adhering to the YAGNI (You Aren’t Gonna Need It), KISS (Keep It Simple, Stupid), and DRY (Don’t Repeat Yourself) principles.
Now, let’s delve into how the actual code would appear.
Implementation
We begin with setting up the project and adding dependencies with Poetry:
importduckdbfromfastapiimportFastAPIfromfastapi_utils.tasksimportrepeat_everyfrompydanticimportBaseModelclassRecord(BaseModel):id:intvalue:str|None=''con=duckdb.connect('data.db')app=FastAPI()@app.on_event('startup')defsetup():con.execute('INSTALL httpfs')con.execute('LOAD httpfs')con.execute('CREATE SECRET (TYPE S3, KEY_ID "x", SECRET "x", REGION "us-east-1"')con.execute('CREATE TABLE IF NOT EXISTS records (id INTEGER PRIMARY KEY, value STRING)')@app.on_event('startup')@repeat_every(seconds=3600)defsync():con.execute('COPY records TO "s3://bucket/file.parquet;"')@app.post('/record')asyncdefstore_record(record:Record):con.execute('INSERT INTO records (id, value) VALUES (?, ?) ON CONFLICT DO UPDATE SET value = EXCLUDED.value',[record.id,record.value])return{'count':con.sql('SELECT COUNT(*) FROM records').fetchall()[0][0]}
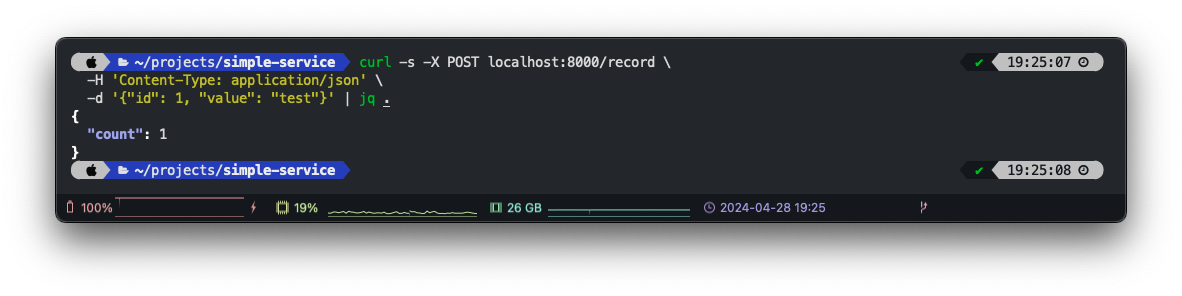
With this service, we can send records as JSON via a POST request to the API, e.g. to localhost:8000/record. The data is persisted in a file called data.db. A record has a unique ID and a value. If the ID already exists, the value will be updated. Every hour (3600 seconds), all data will be synced to a Parquet file in a S3 bucket.
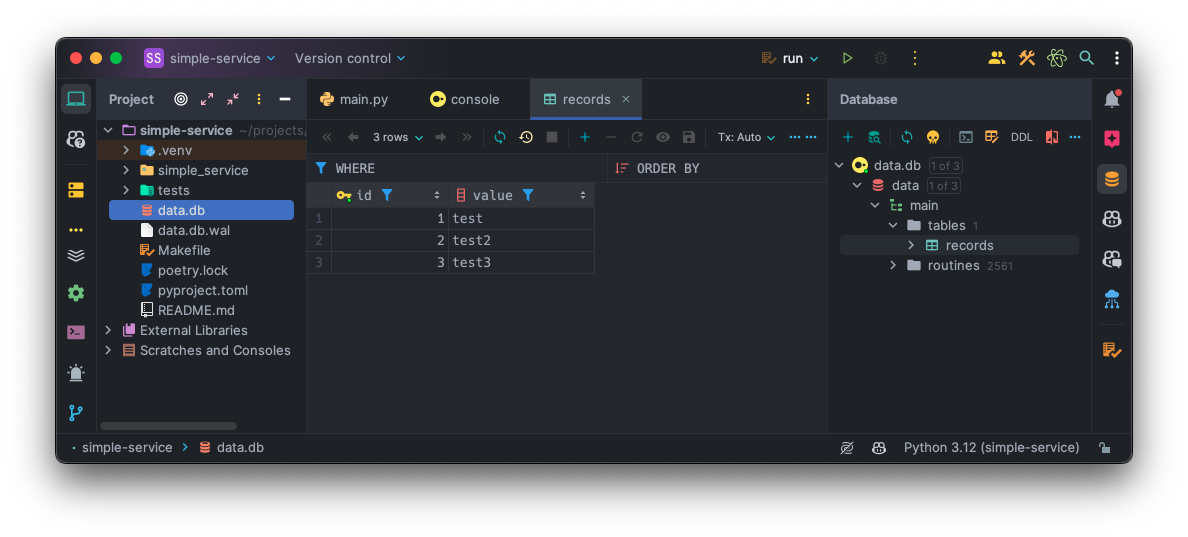
As you can see, the service responded as expected. Afterwards, I added two more records and then connected to the DuckDB database file via PyCharm to illustrate that data is actually persisted:
Certainly, this solution presents various risks and limitations. Using an embedded database and copying all data with each sync operation will lead to performance problems quickly with higher volume of data. However, this approach provides a simple starting point and requires only 38 lines of code, which is a compelling advantage.
With this setup, we can initiate an end-to-end test and progressively evolve the system. The next steps might involve replacing DuckDB with a more advanced database and decoupling components such as the S3 synchronization process.
In the end, we may evolve toward one of the previously mentioned solutions. However, there’s also a possibility that we never reach this stage due to evolving requirements or changing needs.
I’m not suggesting that this solution fully addresses the initial question. Rather, I want to highlight the importance of considering these pragmatic solutions during the creative process and leveraging them for rapid prototyping. We often forget that these pragmatic solutions exist.
Conclusion
In conclusion, I’d like to say thank you to Gunnar for his inspiring content and for representing a wonderful community. Since becoming active in sharing knowledge and engaging with the Data Engineering / Data / Software Development community, I’ve gained valuable insights, endless inspiration, and had the pleasure of connecting with amazing individuals. I’m truly grateful for the positivity and willingness to support one another within this community. So, thank you to everyone, and remember:
So tell me what you want, what you really, really want
Let’s embrace simplicity and continue to support each other in our journeys. At least for that part we don’t need a WHY? 🫶.
Effective AI implementation relies not only on the quantity of data but also on technical expertise. Let's explore the significance of having a skilled data team for AI projects, learn about the Small Data movement and examine how far we can go with no-code or low-code AI platforms.
Netflix Maestro and Apache Airflow - Competitors or Companions in Workflow Orchestration?
Explore how Netflix Maestro and Apache Airflow, two powerful workflow orchestration tools, can complement each other. Delve into their features, strengths, and use cases to uncover whether they are companions or competitors.
Minds and Machines - AI for Mental Health Support, Fine-Tuning LLMs with LoRA in Practice
Explore the potential of Large Language Models (LLMs) changing the future of mental healthcare and learn about how to apply Parameter-Efficient Fine-Tuning (PEFT) to create an AI-powered mental health support chatbot by example





{kind=link}