Close your eyes for a moment. Now, picture yourself struggling with overwhelming anxiety, battling the demons of depression, or feeling lost in a sea of emotional turmoil. This isn’t a scene from a dystopian novel; it’s the reality for millions of people around the world facing mental health challenges.
In the United States alone, according to a report by the National Institute of Mental Health (NIMH), over 57 million adults experienced a mental illness in 2021. That’s more than one in five adults, highlighting the significant prevalence of mental health struggles. Yet, access to quality mental healthcare remains a distant dream for many. Long wait times, exorbitant costs, and location barriers create a formidable wall between those who need help and the resources available.
The consequences of this silent epidemic are devastating. Untreated mental illness can lead to lost productivity, strained relationships, and even suicide. It’s a crisis that demands innovative solutions.
But what if there was a way to access mental health support confidentially, conveniently, and around the clock? AI-powered companions have the potential to revolutionize the way we approach mental healthcare. A safe space in your pocket, offering a listening ear, helpful resources, and basic coping mechanisms, whenever you need it most.
This isn’t science fiction; it’s the future we’re building. In the Mental Health AI Hackathon 2024, organized by Hackathon Raptors, creative solutions by the participants showcase the immense potential of this technology. Within this article, we will discuss the potential, risks and challenges, have a look at the hackathon and hopefully raise awareness for dedicating time and resources to improve the future of mental healthcare.
While Large Language Models (LLMs) like ChatGPT or Gemini are capturing the headlines today, the idea of chatbots playing a role in therapy has a surprisingly long history. Our journey back in time begins with ELIZA, a program developed in the 1960s by Joseph Weizenbaum at MIT. The 1966 paper is still available online.
ELIZA wasn’t originally intended for the therapeutic realm. Its purpose was to explore the dynamics of human-machine communication, not to provide mental health support but it ended up sparking a conversation about the potential of chatbots in mental health support.
Actually, ELIZA itself was an interpreter whereas the ruleset came from scripts. Reading these scripts was done using the Symmetric List Processor (SLIP) programming language, also invented by Joseph Weizenbaum for this purpose. While SLIP was originally an extension to Fortran, it was later embedded into the Michigan Algorithm Decoder (MAD) and Algorithmic Language (ALGOL).
The most famous script is the DOCTOR script. Drawing inspiration from Rogerian therapy, a client-centered method that emphasizes listening and reflecting back the client’s words, ELIZA with the DOCTOR script uses pattern matching, decomposition and reassembly rules to emulate a Rogerian psychotherapist. Due to the popularity of the DOCTOR script, these days what is commonly called ELIZA is actually referencing the DOCTOR script.
By identifying key phrases in a user’s statement, ELIZA could rephrase them as open-ended questions or encouraging statements. For example, a user might say, “I feel lost.” ELIZA, might respond with, “Can you tell me more about feeling lost?” This simple technique created the illusion that ELIZA was truly understanding and responding to the user’s emotions.
This illusion became known as the “Eliza Effect.” Users, including Weizenbaum’s own secretary, reported feeling heard and understood by ELIZA, even though the program lacked any real comprehension. This unexpected outcome highlighted the power of empathetic communication, even when delivered by a machine.
While not a licensed therapist, ELIZA served as a pioneer in the field of chatbot therapy. It demonstrated that conversation itself, even without deep understanding, could have a therapeutic effect. This revelation sparked further research into the potential of chatbots to provide mental health support.
Now, after about half a century, we have Large Language Models (LLMs) we can ask to emulate a basic version of the 1966 ELIZA. For this purpose, I used GPT-4 Turbo with the following prompt:
Write a Python script, which emulates ELIZA, the chatbot developed in the 1960s by Joseph Weizenbaum. Use the DOCTOR variant of it as a reference to simulate a psychotherapist of the Rogerian school.
Here is what GPT-4 created for us:
importreimportrandomclassEliza:def__init__(self):self.reflections={...}self.patterns=[...]defreflect(self,fragment):tokens=fragment.lower().split()fori,tokeninenumerate(tokens):iftokeninself.reflections:tokens[i]=self.reflections[token]return''.join(tokens)defanalyze(self,statement):forpattern,responsesinself.patterns:match=re.match(pattern,statement.rstrip(".!"))ifmatch:response=random.choice(responses)returnresponse.format(*[self.reflect(g)forginmatch.groups()])return"Tell me more."defrun(self):print("Hello. How are you feeling today?")whileTrue:statement=input("> ")ifstatement.lower()in["exit","quit","bye","goodbye"]:print("Goodbye. It was nice talking to you.")breakresponse=self.analyze(statement)print(response)if__name__=="__main__":eliza=Eliza()eliza.run()
I removed the reflections and patterns from the code to keep it readable, you can find the full working version here:
Of course this is a simplified version and limited when it comes to reflections and patterns, but it shows how much happened in the context of Natural language processing (NLP) or AI as we are now able to ask a Large Language Model (LLM) to create a chatbot which mimics the conversation style of a Rogerian psychotherapist.
But enough from the past, let’s discover the future we’re building and see what conclusions we can draw from the Mental Health AI Hackathon 2024 and what this means for mental healthcare.
Hacking for Hope: The Mental Health AI Hackathon
As discussed earlier, millions struggle without access to proper care while ELIZA, an early chatbot from the 1960s, hinted at the potential of technology in this field. Now, the Mental Health AI Hackathon 2024 steps forward, aiming to bridge this gap with AI-powered chatbots offering support, resources, and a potential path to professional help.
The Mental Health AI Hackathon 2024, organized by Hackathon Raptors, is a unique event tackling a pressing issue. This year’s challenge focuses on creating AI-powered chatbots specifically designed to offer mental health support.
The competition seeks passionate developers and tech enthusiasts to leverage AI for a positive social impact. The goal? To develop chatbots that can provide comfort, guidance, and resources to those seeking mental well-being support.
What makes a successful mental health chatbot? How to build a chatbot with heart?
💚 Empathy Matters: Can the chatbot understand and respond to complex emotions in a supportive way?
🎭 Adaptability is Key: Mental health needs vary. The winning chatbot should adapt and scale to handle diverse users and languages.
🔒 Security First: Protecting user privacy is crucial. The chatbot’s architecture needs to be secure and follow data protection regulations.
📚 Bridging the Gap: The ideal chatbot acts as a bridge, connecting users with professional help and resources.
🏔️ A Journey, Not a Destination: Mental health is ongoing. The chatbot should encourage users to return for continuous support.
About Hackathon Raptors
Hackathon Raptors is a community interest company based in the UK. They organize hackathons that make a real difference, with focus on impactful challenges, just like the mentioned Mental Health AI Hackathon 2024. Furthermore, Hackathon Raptors is a association bringing together experts from all over the world.
A Balancing Act: The Potential and Pitfalls of AI in Mental Health Support
The promise of AI driven applications for mental health support is undeniable. These applications hold the potential to revolutionize how we approach mental well-being. However, there are potential concerns that require careful consideration:
Limited Empathy and Emotional Intelligence: While AI can excel at pattern recognition and data analysis, replicating true human empathy and emotional intelligence remains a challenge. Can a chatbot truly understand human emotion and respond in a way that feels supportive?
Bias in Algorithmic Design: LLMs are only as good as the data they are trained on. Unbalanced datasets or biases in the training process can lead to chatbots that perpetuate stereotypes or provide inaccurate or unhelpful responses.
Data Privacy and Security: Mental health information is deeply personal and sensitive. The security of user data and ensuring compliance with data privacy regulations is very important. Therefore, this must be seen as a risk when it comes to data breaches.
Over-reliance and Misdiagnosis: Chatbots are not replacements for qualified mental health professionals. Over-reliance on AI for complex issues could lead to misdiagnosis, delayed or even wrong treatment.
The Human Touch: While chatbots can offer valuable support, human connection remains crucial for many facing mental health challenges. Can AI truly replace the therapeutic value of human interaction?
Hallucination and Misinformation: AI chatbots can suffer from a phenomenon known as hallucination, where they generate false or misleading information. This can be particularly dangerous in the context of mental health, potentially making existing anxieties worse or providing inaccurate advice.
Additionally, for individuals with severe mental health issues, conversations with an AI chatbot might have unintended consequences. Imagine someone struggling with suicidal ideation. While a chatbot could offer supportive resources and crisis hotlines, it cannot replicate the nuanced understanding and emotional support provided by a human therapist. In such cases, AI intervention could create a false sense of security or even lead the user to isolate themselves further.
When working on such systems it is important to make these concerns visible and transparent. This is the only way to address them properly and to find potential solutions to mitigate the risks.
Each of the issues can be addressed individually and hackathons like the Mental Health AI Hackathon 2024 are a great way to create prototype applications that cover these aspects.
But let’s have a closer look at how to approach these concerns with concrete measures. Solving such issues is all about embedding the LLM into a surrounding system, which adds more control and improves the input and output of the model.
Cognitive Behavior Therapy (CBT)
One way could be, to implement a structured therapeutical approach like Cognitive Behavior Therapy (CBT). CBT is a well-established form of psychotherapy with a strong track record of effectiveness in treating various mental health conditions, including anxiety, depression, and phobias. A CBT therapy involves changing thinking patterns with strategies like:
Learning to recognize distortions in thinking, then to reevaluate them in light of reality.
Gaining a better understanding of the behavior and motivation of others.
Using problem-solving skills to cope with difficult situations.
Learning to develop a greater sense of confidence in own abilities.
By incorporating CBT principles, AI chatbots can potentially guide users to identify unhelpful thinking patterns, practice cognitive reframing techniques, and explore healthy coping mechanisms. This can empower users to take a more active role in managing their mental well-being.
CBT triad
Fine-tuned models
Another way is to fine-tune LLMs by training on data targeting mental health issues to get more accurate results. LLM fine-tuning is a process that takes a pre-trained language model and customizes it for specific tasks. It leverages the general language understanding, acquired by the model during its initial training phase, and adapts it to more specialized requirements. However, this process might involve adjustments of so many parameters that it’s leading to several challenges, including:
High Computational Cost: Fine-tuning massive models like GPT-3 requires significant computational resources.
Storage Bottleneck: Storing a fine-tuned model for each downstream task creates a storage burden, limiting model deployment on resource-constrained environments.
Redundant Updates: During fine-tuning, only a fraction of the LLM parameters are crucial for the specific task. Updating the entire set can be inefficient.
To address these challenges, researchers have developed Parameter-Efficient Fine-Tuning (PEFT) techniques that minimize the number of parameters updated during fine-tuning. Low-Rank Adaptation (LoRA) for example, is a highly efficient method of LLM fine-tuning. LoRA modifies the fine-tuning process by freezing the original model weights and applying changes to a separate set of weights, which are then added to the original parameters.
Quantized LoRA (QLoRA) builds upon LoRA and incorporates quantization techniques to further enhance efficiency. QLoRA reduces the precision of the weights (e.g., from 32-bit to 4-bit) during storage and computation. This significantly reduces memory requirements without sacrificing accuracy. QLoRA also employs a double quantization technique. It not only quantizes the model weights but also the quantization constants themselves, leading to further memory savings.
Another, and rather new, approach is Odds Ratio Preference Optimization (ORPO), which combines instruction tuning and preference alignment into one single training process, improving runtime and reducing resource utilization.
Hugging Face offers a PEFT library for Python with state-of-the-art PEFT methods, such as LoRA and QLoRA. Furthermore, you can find a collection of questions and answers sourced from two online counseling and therapy platforms in form of a dataset on Hugging Face, which would be a great start to fine-tune a model for a potential mental health supporting chatbot.
The concerns mentioned previously often involve misinformation, inaccurate or unhelpful responses. In the realm of Large Language Models (LLM) and AI, one paradigm becoming more and more popular to reduce the risk of these issues is Retrieval-Augmented Generation (RAG). But what does RAG entail, and how does it influence the landscape of AI development?
At its essence, RAG enhances LLM systems by incorporating external data to enrich their predictions. Which means, you pass relevant context to the LLM as an additional part of the prompt, but how do you find relevant context? Usually, this data can be automatically retrieved from a database with vector search or dedicated vector databases. Vector databases are especially useful, since they store data in a way, so that it can be queried for similar data quickly. The LLM then generates the output based on both, the query and the retrieved documents.
Picture this: you have an LLM capable of generating text based on a given prompt. RAG takes this a step further by infusing additional context from external sources, like up-to-date psychological studies, to enhance the relevance and accuracy of the generated text.
Let’s break down the key components of RAG:
LLMs: LLMs serve as the backbone of RAG workflows. These models, trained on vast amounts of text data, possess the ability to understand and generate human-like text.
Vector Indexes for contextual enrichment: A crucial aspect of RAG is the use of vector indexes, which store embeddings of text data in a format understandable by LLMs. These indexes allow for efficient retrieval of relevant information during the generation process.
Retrieval process: RAG involves retrieving pertinent documents or information based on the given context or prompt. This retrieved data acts as the additional input for the LLM, supplementing its understanding and enhancing the quality of generated responses. This could be getting all relevant information known and connected to a specific movie.
Generative Output: With the combined knowledge from both the LLM and the retrieved context, the system generates text that is not only coherent but also contextually relevant, thanks to the augmented data.
RAG architecture taking Google VertexAI and Gemini as example
In more general terms, RAG is a very important concept, especially when crafting more specialized LLM applications. This concept can avoid the risk of false positives, giving wrong answers, or hallucinations in general.
These are some open-source projects that might be helpful when approaching RAG in one of your projects:
txtai: All-in-one open-source embeddings database for semantic search, LLM orchestration and language model workflows.
LangChain: LangChain is a framework for developing applications powered by large language models (LLMs).
Qdrant: Vector Search Engine for the next generation of AI applications.
Weaviate: Weaviate is a cloud-native, open source vector database that is robust, fast, and scalable.
Of course, with the potential value of this approach for LLM-based applications, there are many more open- and close-source alternatives, but with these, you should be able to get your research on the topic started.
Hackathon Guide: Building Your First Mental Health Chatbot
Disclaimer: the following chapter should help people, who are interested in developing an AI-powered chatbot to get started. This is not meant to be a sophisticated, production-ready mental health support solution.
To inspire you to get started with your own AI-driven project in regards to mental health, let’s fine-tune a LLM and create our own, basic AI-powered mental health support chatbot step by step.
Since fine-tuning a LLM needs a decent environment, I am using a Jupyter notebook running in a Google Cloud Vertex AI Workbench instance. Vertex AI Workbench instances are Jupyter notebook-based development environments for the entire data science workflow. These instances are prepackaged with JupyterLab and have a preinstalled suite of deep learning packages, including support for the TensorFlow and PyTorch frameworks. You can configure different types of instances based on your needs.
To finish the fine-tuning process in a reasonable amount of time and to have access to some modern features like FlashAttention (explained later), I used the following machine type:
GPU type: NVIDIA A100 80GB
Number of GPUs: 1
12 vCPU
6 cores
170 GB memory
Running this instance costs around $4.193 hourly. Since you pay for instances for what you use, it means there are no upfront costs and per second billing. The fine-tuning process will take around 30 minutes, so the total costs are around $2.
Vertex AI Workbench Instance for fine-tuning
You can also run the process on your local machine or using Google Colab, which is a web-based platform built around Jupyter Notebooks. You access Colab through your web browser, no software installation needed on your own computer.
The code you run in Colab actually executes on powerful machines in Google’s cloud, not your personal computer. This gives you access to advanced hardware like GPUs and TPUs, which are great for speeding up data analysis and machine learning tasks.
Colab provides a user-friendly environment with powerful computing resources in the cloud, all accessible through your web browser, and what is really cool: you can get started for free. The free tier already offers access to hardware accelerator options however, free Colab resources are not guaranteed and not unlimited, and usage limits sometimes fluctuate. These interruptions might be frustrating, but this is the price for having a sophisticated, free notebook platform.
Talking about prices, of course you can upgrade to another plan, including Pay As You Go or Colab Pro.
For this example, the free version with a T4 GPUwould not offer enough resources for the fine-tuning process, which is why I choose a more sophisticated Vertex AI Workbench instance. However, Colab is great way to get started with such projects so I still wanted to mention this option.
Parameter-Efficient Fine-Tuning (PEFT) of Llama 2 with Mental Health Counseling Data
With a NVIDIA A100 80GB Tensor-Core-GPU, we have a really good basis for our fine-tuning process.
Like explained earlier, fine-tuning LLMs is often costly due to their scale. Parameter-Efficient Fine-Tuning (PEFT) methods enable efficient alternatives by only fine-tuning a small number of model parameters.
In this example, we will use the meta-llama/Llama-2-7b-chat-hf by Meta hosted on Hugging Face. This model uses 7 billion parameters, optimized for dialogue. To fine-tune this model, we will use the Amod/mental_health_counseling_conversations dataset, also available on Hugging Face, which contains a collection of questions and answers sourced from two online counseling and therapy platforms, covering a wide range of mental health topics.
The basic idea is: we load the model, tokenizer and dataset from Hugging Face. Then we create a LoraConfig with settings based on the previously mentioned Quantized LoRA (QLoRA) paper, then we prepare the model for training, configure a so called SFTTrainer (Supervised Fine-Tuning Trainer) for the fine-tuning process, train the model, save the model and then push this fine-tuned model back to Hugging Face so that we can use it in an application later.
I am running the process within a Jupyter notebook, so let’s break down each individual step of the fine-tuning procedure.
First, we install all required libraries, including PyTorch and the toolkits provided by Hugging Face. The environment this is running in allows to use FlashAttention based on the FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness paper, which requires CUDA 11, NVCC, and an Turing or Ampere GPU. This particular dependency has to be installed after torch, so we run it in a second step seperately.
Next, we setup some variables to specify the model we are going to use, the dataset but also the Hugging Face User Access Token. This token is used to interact with the Hugging Face platform to download and publish models, datasets and more. To create a token, you can register for free at https://huggingface.co/, then open up your account settings and select Access Tokens from the menu. For this process, we need a token with write access since we are going to publish the fine-tuned model to Hugging Face later.
If you want to try the fine-tuning yourself, just replace the placeholder in the following code with your own token.
# see: https://huggingface.co/docs/hub/security-tokens
# must be write token to push model later
hf_token="your-token"# https://huggingface.co/meta-llama/Llama-2-7b-chat-hf
base_model="meta-llama/Llama-2-7b-chat-hf"# https://huggingface.co/datasets/Amod/mental_health_counseling_conversations
fine_tuning_dataset="Amod/mental_health_counseling_conversations"# name for output model
target_model="vojay/Llama-2-7b-chat-hf-mental-health"
For the next part it is important to understand, that prompts are usually created by multiple elements following a specific template. This depends on the model of course and the llama-2-chat model uses the following format, based on the Llama 2 paper, to define system and instruction prompts:
This format might look cryptic at first, but it becomes more clear when looking at the individual elements:
<s>: beginning of sequence.
</s>: end of sequence.
<<SYS>>: beginning of system message.
<</SYS>>: end of system message.
[INST]: beginning of instructions.
[/INST]: end of instructions.
system_prompt: overall context for model responses.
user_message: user instructions for generating output.
model_response: expected model response for training only.
When we train the model, we must follow this format, so the next step is to define a proper template and functions to transform the sample data accordingly. Let’s start with the system or base prompt to create an overall context:
defget_base_prompt():return"""
You are a knowledgeable and supportive psychologist. You provide emphatic, non-judgmental responses to users seeking
emotional and psychological support. Provide a safe space for users to share and reflect, focus on empathy, active
listening and understanding.
"""
We will re-use this base prompt later to enrich user input before we send it to the LLM for evaluation. This would be a great opportunity for projects in this context, since the base prompt could be improved to make the LLM respond much better.
Now let’s define a function to format training data accordingly:
The next part is the fine-tuning part itself, which is wrapped into a function, so that we first simple define the process and then execute it as a next step in the notebook:
deftrain_mental_health_model():model=AutoModelForCausalLM.from_pretrained(base_model,token=hf_token,quantization_config=BitsAndBytesConfig(load_in_4bit=True,bnb_4bit_quant_type="nf4",bnb_4bit_compute_dtype=torch.float16,bnb_4bit_use_double_quant=False),torch_dtype=torch.float16,# reduce memory usage
attn_implementation="flash_attention_2"# optimize for tensor cores (NVIDIA A100)
)# LoRA config based on QLoRA paper
peft_config=LoraConfig(lora_alpha=16,lora_dropout=0.1,r=8,bias="none",task_type="CAUSAL_LM")model=prepare_model_for_kbit_training(model)model=get_peft_model(model,peft_config)args=TrainingArguments(output_dir=target_model,# model output directory
overwrite_output_dir=True,# overwrite output if exists
num_train_epochs=2,# number of epochs to train
per_device_train_batch_size=2,# batch size per device during training
gradient_checkpointing=True,# save memory but causes slower training
logging_steps=10,# log every 10 steps
learning_rate=1e-4,# learning rate
max_grad_norm=0.3,# max gradient norm based on QLoRA paper
warmup_ratio=0.03,# warmup ratio based on QLoRA paper
optim="paged_adamw_8bit",# memory-efficient variant of AdamW optimizer
lr_scheduler_type="constant",# constant learning rate
save_strategy="epoch",# save at the end of each epoch
evaluation_strategy="epoch",# evaluation at the end of each epoch,
fp16=True,# use fp16 16-bitprecision training instead of 32-bit to save memory
tf32=True# optimize for tensor cores (NVIDIA A100)
)tokenizer=AutoTokenizer.from_pretrained(base_model,token=hf_token)tokenizer.pad_token=tokenizer.eos_tokentokenizer.padding_side="right"# limit samples to reduce memory usage
dataset=load_dataset(fine_tuning_dataset,split="train")train_dataset=dataset.select(range(2000))eval_dataset=dataset.select(range(2000,2500))trainer=SFTTrainer(model=model,train_dataset=train_dataset,eval_dataset=eval_dataset,peft_config=peft_config,max_seq_length=1024,tokenizer=tokenizer,formatting_func=lambdaentry:format_prompt(get_base_prompt(),entry["Context"],entry["Response"]),packing=True,args=args)gc.collect()torch.cuda.empty_cache()trainer.train()trainer.save_model()trainer.push_to_hub(target_model,token=hf_token)
Vertex AI Workbench notebook
I added comments to all training arguments to make the configuration transparent. However, the specifics depend on the environment you are running the training in and on the input model and dataset, so adjustments might be necessary.
Let’s have a closer look to how the process works in detail. With AutoModelForCausalLM.from_pretrained we are loading the model and by setting the quantization_config we transform it to 4-bit weights and activations through quantization, which offers benefits in regards to performance. By setting attn_implementation to flash_attention_2.
FlashAttention-2 is a faster and more efficient implementation of the standard attention mechanism that can significantly speedup inference by additionally parallelizing the attention computation over sequence length and partitioning the work between GPU threads to reduce communication and shared memory reads/writes between them.
The LoraConfig configures the Low-Rank Adaptation (LoRA) process. lora_alpha controls the scaling factor for the weight matrices, the lora_dropout sets the dropout probability of the LoRA layers, r controls the rank of the low-rank matrices, bias determines how bias terms are handled and task_type reflects the task of the fine-tuned model.
Once the LoraConfig is setup, we create the PeftModel with the get_peft_model() function.
With the prepared model, the next step is to prepare the training. To do so, we create a TrainingArguments object, which controls all major aspects of the training process, including:
output_dir=target_model,# model output directory
overwrite_output_dir=True,# overwrite output if exists
num_train_epochs=2,# number of epochs to train
per_device_train_batch_size=2,# batch size per device during training
gradient_checkpointing=True,# save memory but causes slower training
logging_steps=10,# log every 10 steps
learning_rate=1e-4,# learning rate
max_grad_norm=0.3,# max gradient norm based on QLoRA paper
warmup_ratio=0.03,# warmup ratio based on QLoRA paper
optim="paged_adamw_8bit",# memory-efficient variant of AdamW optimizer
lr_scheduler_type="constant",# constant learning rate
save_strategy="epoch",# save at the end of each epoch
evaluation_strategy="epoch",# evaluation at the end of each epoch,
fp16=True,# use fp16 16-bitprecision training instead of 32-bit to save memory
tf32=True# optimize for tensor cores (NVIDIA A100)
Afterwards, we create the tokenizer for the model with AutoTokenizer.from_pretrained.
The next step is to load the mental health dataset. Here we are limiting the sample size to reduce memory usage and speed up the training.
With all that, we can instantiate the SFTTrainer, train, save and publish the fine-tuned model, using trainer.push_to_hub .
In the next step, we call the train_mental_health_model() and can simply watch while the magic happens:
train_mental_health_model()
Fine-tuning progress
I pushed the fine-tuned model to Hugging Face, so you can fetch it from there if you want to skip the fine-tuning process.
Fine-tuned model on Hugging Face
Keep in mind that this fine-tuned model is actually an adapter for the base-model. Which means, in order to use it, we need to load the base-model and apply this fine-tuning adapter:
For a hackathon project, improving this fine-tuning process would be a great way to create a more sophisticated mental health support application.
Create a Chatbot with the Fine-tuned Model
Now that we have a fine-tuned model, let’s create a chatbot to make use of it. To keep it simple, we run a pragmatic CLI bot within the local environment.
Let’s start by having a closer look how to create the project and how dependencies are managed in general. For this, we are using Poetry, a tool for dependency management and packaging in Python.
The three main tasks Poetry can help you with are: Build, Publish and Track. The idea is to have a deterministic way to manage dependencies, to share your project and to track dependency states.
Poetry also handles the creation of virtual environments for you. Per default, those are in a centralized folder within your system. However, if you prefer to have the virtual environment of project in the project folder, like I do, it is a simple config change:
poetry config virtualenvs.in-project true
With poetry new you can then create a new Python project. It will create a virtual environment linking you systems default Python. If you combine this with pyenv, you get a flexible way to create projects using specific versions. Alternatively, you can also tell Poetry directly which Python version to use: poetry env use /full/path/to/python.
Once you have a new project, you can use poetry add to add dependencies to it.
Let’s start by creating the project for our bot and add all necessary dependencies:
With that, we can create the app.py main file with the code to run our bot. As before, if you want to run this on your own, please replace the Hugging Face token placeholder with your own token. This time, a read-only token is sufficient as we simply fetch the base and fine-tuned models from Hugging Face without uploading anything.
Another thing to mention is, that I am running this on the following environment:
Apple MacBook Pro
CPU: M1 Max
Memory: 64 GB
macOS: Sonoma 14.4.1
Python 3.12
To increase performance, I am using the so called Metal Performance Shaders (MPS) device for PyTorch to leverage the GPU on macOS devices:
Also, we will use the same base prompt as we used for training. Putting everything together, this is the pragmatic CLI version of our chatbot:
importtorchfromhuggingface_hubimportloginfromtransformersimportAutoModelForCausalLM,AutoTokenizerdevice=torch.device("mps")torch.set_default_device(device)login(token="your-token")title="Mental Health Chatbot"description="This bot is using a fine-tuned version of meta-llama/Llama-2-7b-chat-hf"model_id="meta-llama/Llama-2-7b-chat-hf"adapter_model_id="vojay/Llama-2-7b-chat-hf-mental-health"model=AutoModelForCausalLM.from_pretrained(model_id,torch_dtype=torch.float16)model.load_adapter(adapter_model_id)model.to(device)tokenizer=AutoTokenizer.from_pretrained(model_id)tokenizer.pad_token=tokenizer.eos_tokentokenizer.padding_side="right"defget_base_prompt():return"""
You are a knowledgeable and supportive psychologist. You provide emphatic, non-judgmental responses to users seeking
emotional and psychological support. Provide a safe space for users to share and reflect, focus on empathy, active
listening and understanding.
"""defformat_prompt(base,user_message):returnf"<s>[INST] <<SYS>>{base}<</SYS>>{user_message} [/INST]"defchat_with_llama(prompt):input_ids=tokenizer.encode(format_prompt(get_base_prompt(),prompt),return_tensors="pt")input_ids=input_ids.to(device)output=model.generate(input_ids,pad_token_id=tokenizer.eos_token_id,max_length=2000,temperature=0.9,top_k=50,top_p=0.9)decoded=tokenizer.decode(output[0],skip_special_tokens=True)returndecoded.split("[/INST]")[1].lstrip()whileTrue:prompt=input("You: ")response=chat_with_llama(prompt)print(f"Llama: {response}")
Time to give it a try! Let’s run it with the following chat input:
I'm going through some things with my feelings and myself. I barely sleep and I'vebeenstrugglingwithanxiety,andstress.Canyourecommendanycopingstrategiestoavoidmedication?
This is the result:
AI-powered mental health chatbot
In fact, our fine-tuned model answered so well, that I would like to quote the answer here, as this is a nice addition to this article when talking about mental health.
Yes, there are many things you can do to help manage stress and anxiety without medication.
Take care of yourself, get enough sleep, eat well, and exercise. When we don’t take care of ourselves we are more prone to feeling stressed and anxious.
Practice mindfulness. This means paying attention to the moment without judging yourself. Mindfulness can help us to let go of the past and not worry about the future
Practice meditation. Mindfulness meditation is a way to train yourself to focus on your breath and be present.
Take some time to think about the things that make you happy. What are the things that you are grateful for? What are the things that you like to do?
Find some quiet time and journal your thoughts. Writing about your thoughts and feelings can be very helpful in managing stress and anxiety.
Practice some form of relaxation, whether it be yoga, tai chi, or deep breathing.
Practice some form of self-care, whether it be a massage, or getting a manicure.
Try to find someone to talk to. Sometimes talking to someone can help us to see things in a different perspective.
Try to find humor in your situation. Sometimes laughter can be helpful in lifting your spirits.
Practice some form of physical exercise. Exercise can help us to feel more relaxed and less stressed.
Take a walk outside, get out of the house, and get some fresh air.
Practice some form of relaxation, whether it be listening to music, or reading.
Try to stay present in the moment.
And that’s it, our very own AI-powered mental health chatbot. With that, maybe there is some helpful advice for you, stay healthy and let’s discover how to continue from here in the next chapter.
Level Up Your Hackathon Project: Next Steps for Your Mental Health Chatbot
The example we explored provides a solid foundation to build upon. Here are some ways to create an even more sophisticated solution for your hackathon project:
Optimize the fine-tuning process: Refine the LoRA parameters and training configuration to improve the chatbot’s performance. This can lead to more empathic and natural language generation. Also try other approaches like Odds Ratio Preference Optimization (ORPO) to improve performance.
Enhance base prompts: Craft a base prompt that encourage the chatbot to respond in a supportive and understanding manner. Integrate a template to guide users towards seeking professional help when necessary.
Implement Retrieval-Augmented Generation (RAG): Incorporate RAG to provide the chatbot with additional context to enrich the users requests. This allows for more informed and relevant responses.
Move beyond simple chat: Consider implementing a more structured interaction model, perhaps one based on principles of Cognitive Behavioral Therapy (CBT). This can offer a more focused and potentially therapeutic experience for users.
Focus on usability: Instead of putting all focus on improving the model itself, a frontend-centered approach could also be to create a custom UI, maybe with focus on accessibility or using a creative form of interaction.
Apart from these improvements, I always encourage to think outside the box. Creating AI-powered applications for mental health support does not mean to create chatbots for virtual counseling or therapy only. Another way to approach this task could be to think about how to improve aspects that cause or amplify mental health problems, such as stress. If we re-phrase the problem to find AI-driven solutions to reduce stress, it opens doors for many ideas that indirectly help with the initial problem, for example individualized, AI-driven meditation support to reduce stress and consequently reduce the risk for mental health problems. Another way could be to focus on helping with specific types of mental health problems, such as Post-Traumatic Stress Disorder (PTSD).
There are plenty of opportunities which might help a lot of people if certain risks are addressed properly. Therefore, I am looking forward to see what eye-opening solutions will be created during the Mental Health AI Hackathon 2024.
To give you some more inspiration regarding AI-driven application development:
If you are interested in using the Google Gemini LLM with a more advanced API based on FastAPI and a dedicated Vue-based frontend, checkout this article:
Imagine a world where mental health support is available to everyone, anytime, anywhere. Millions struggle without access to quality care due to long wait times, exorbitant costs, and location barriers.
AI-powered chatbots can bridge this gap by offering 24/7, accessible mental health support. These tools provide a safe space for people to begin their mental health journey, offering a listening ear, helpful resources, and basic coping mechanisms, whenever they need it most.
However, it’s important to acknowledge and address the potential limitations, ethical concerns and risks of AI chatbots in this area. Subject-specific approaches like Cognitive Behavioral Therapy (CBT) and technical solutions like Low-Rank Adaptation (LoRA) and Retrieval-Augmented Generation (RAG) can mitigate risks but they must be discussed and further improved.
By embracing these advancements and prioritizing ethical development, such applications can become powerful tools for democratizing mental healthcare. The Mental Health AI Hackathon 2024 supports this progress, fostering innovation and collaboration to create AI solutions that prioritize user safety and mental health support for a broader population.
This future is closer than we think. With responsible development and a focus on ethical considerations, technology might revolutionize mental healthcare, making it accessible and available to everyone, every day.
Even though AI, LLMs, ML, and data are all around today, there are still numerous opportunities to use AI for positive social impact. Mental health support, in particular, presents significant risks and challenges, but by making these transparent and discussing them openly, we can make the way for meaningful progress. I look forward to hearing your ideas, experiences, concerns, and solutions.
Effective AI implementation relies not only on the quantity of data but also on technical expertise. Let's explore the significance of having a skilled data team for AI projects, learn about the Small Data movement and examine how far we can go with no-code or low-code AI platforms.
Netflix Maestro and Apache Airflow - Competitors or Companions in Workflow Orchestration?
Explore how Netflix Maestro and Apache Airflow, two powerful workflow orchestration tools, can complement each other. Delve into their features, strengths, and use cases to uncover whether they are companions or competitors.

 Photo by
Photo by 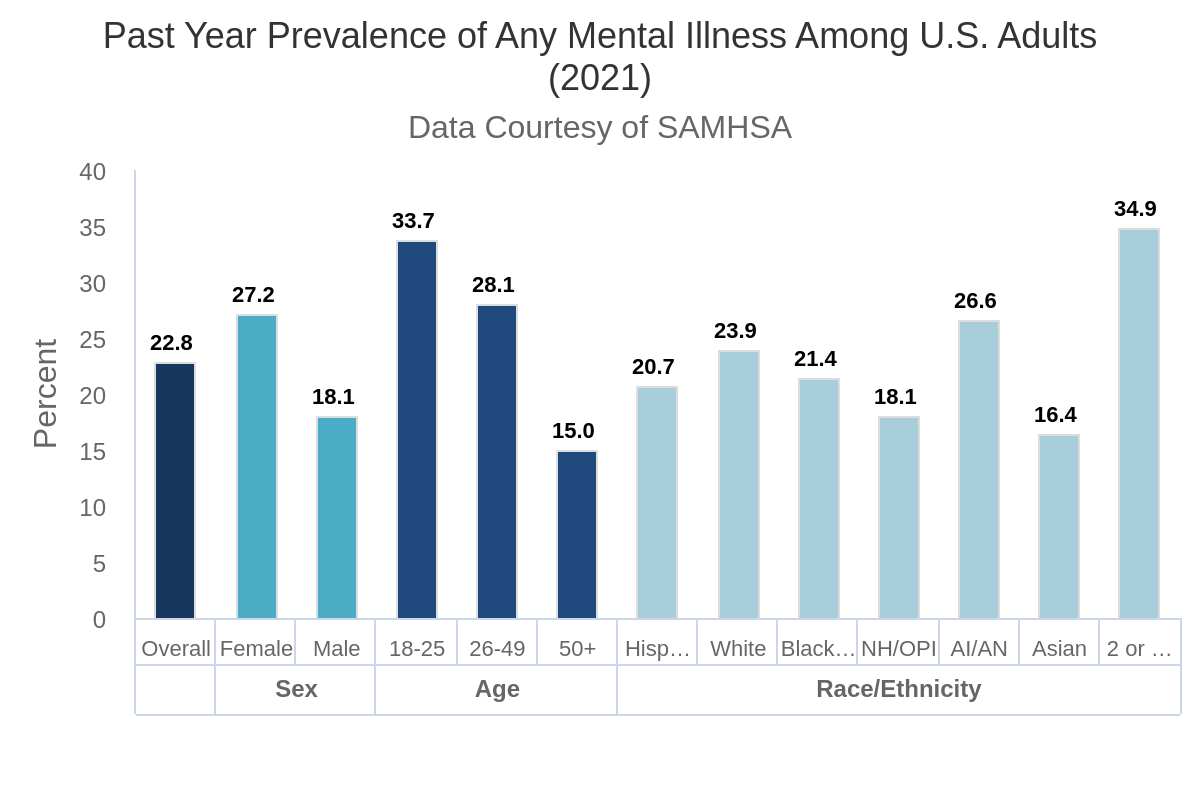 Source:
Source:  Source:
Source:  Source:
Source: 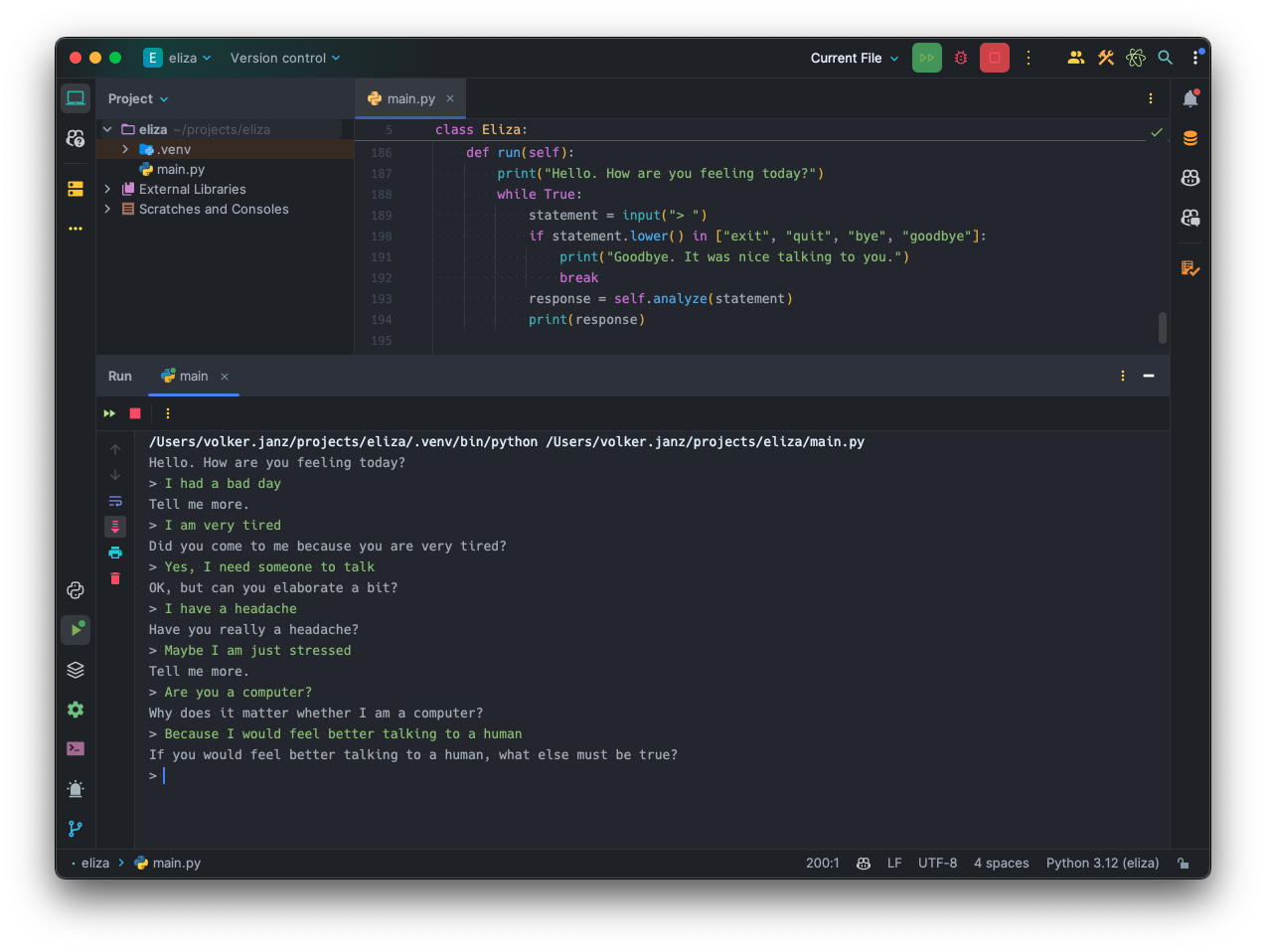 ELIZA implemented by GPT
ELIZA implemented by GPT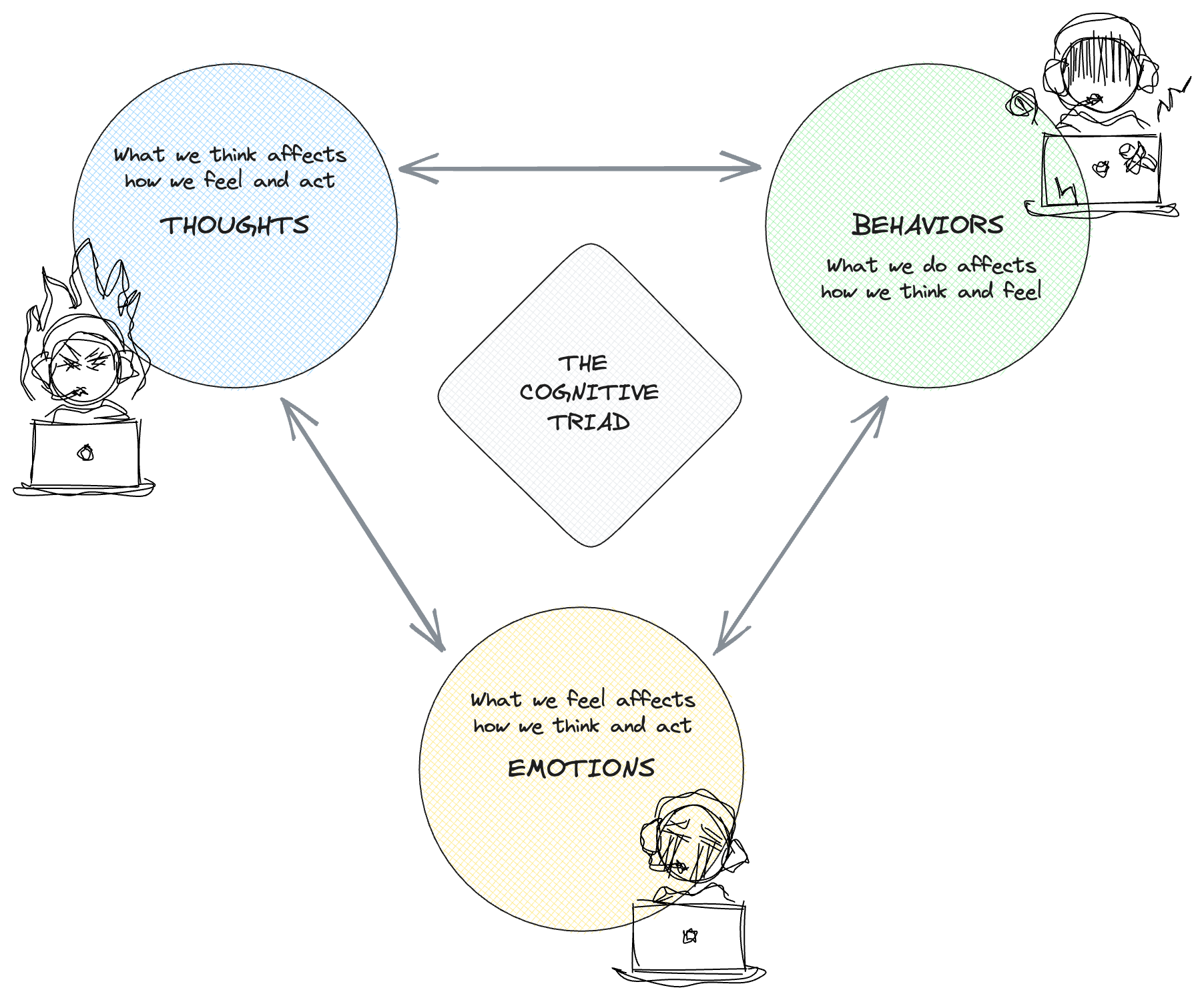 CBT triad
CBT triad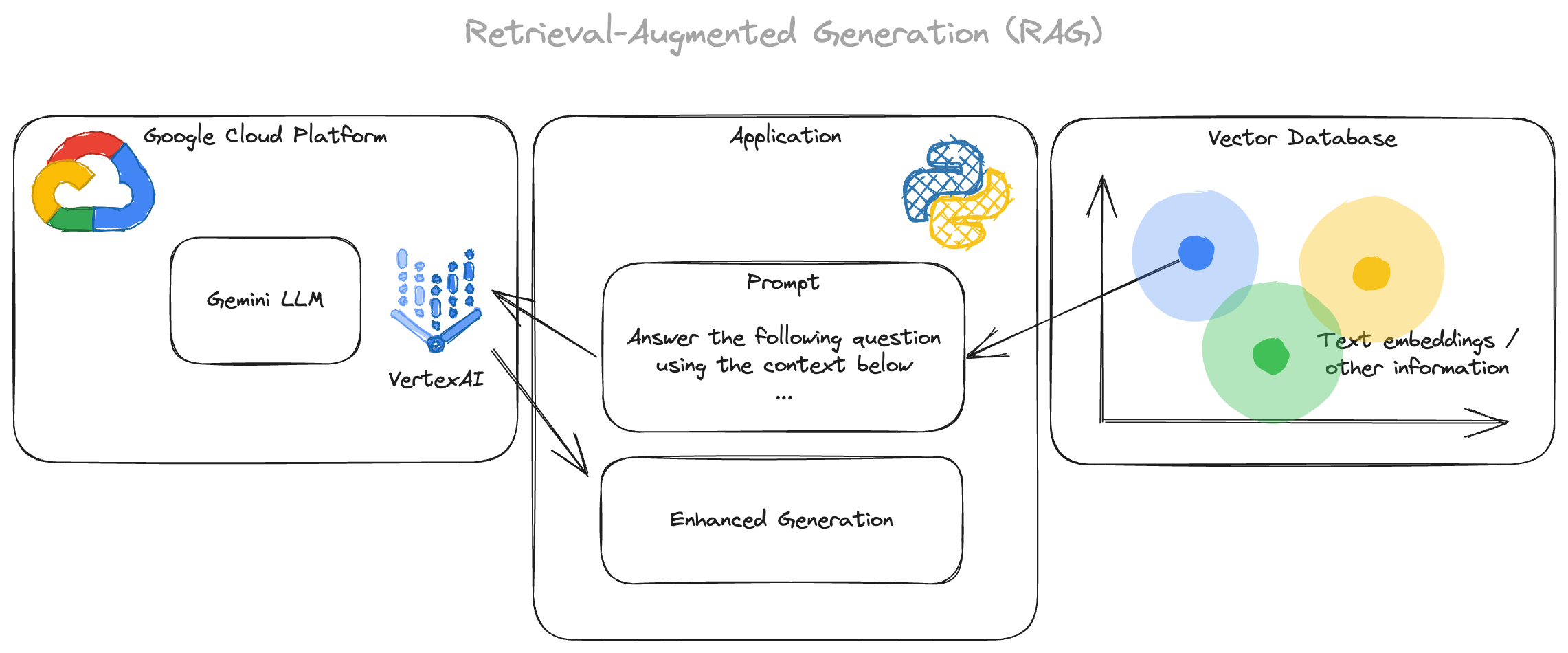 RAG architecture taking Google VertexAI and Gemini as example
RAG architecture taking Google VertexAI and Gemini as example AI therapy session, generated with
AI therapy session, generated with 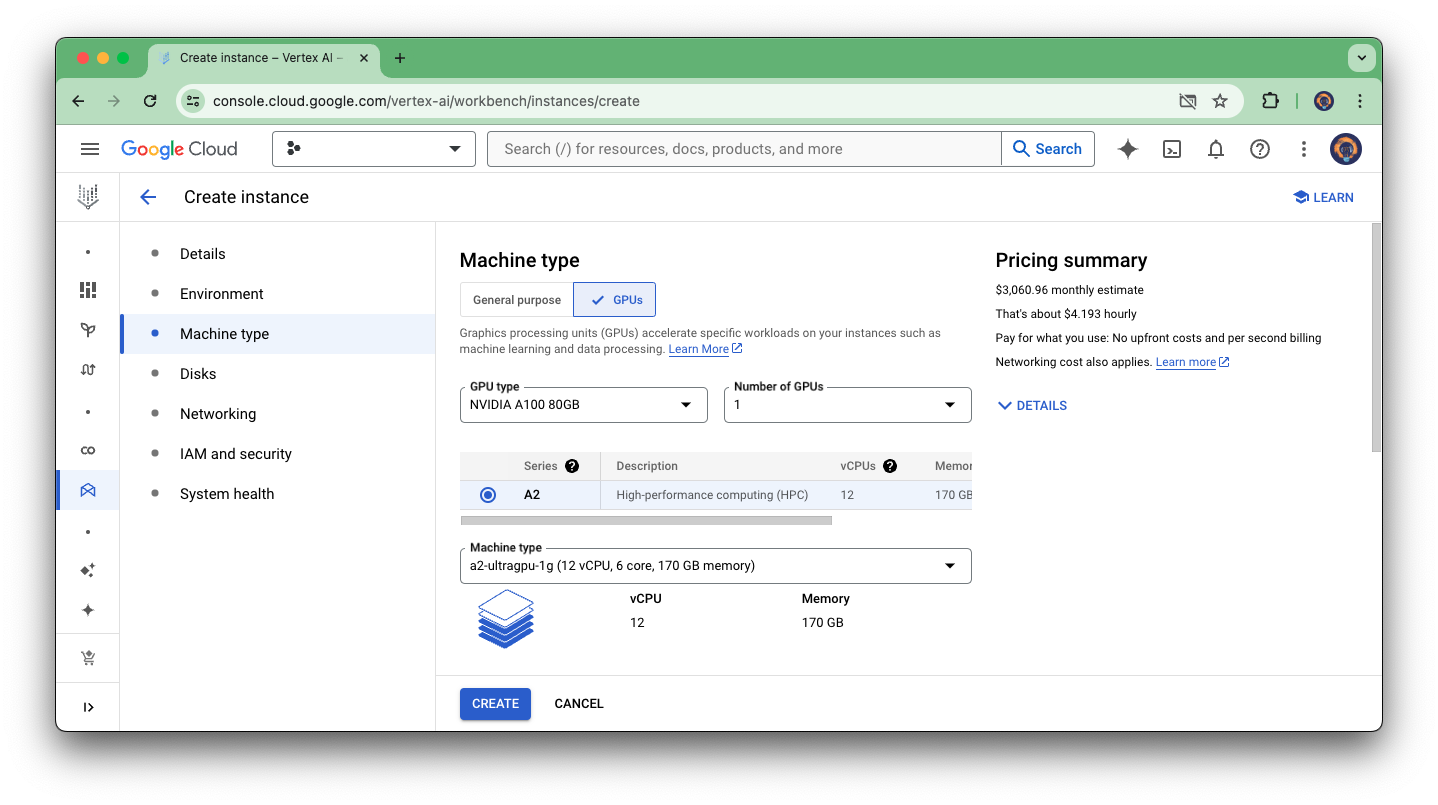 Vertex AI Workbench Instance for fine-tuning
Vertex AI Workbench Instance for fine-tuning Google Colab, source:
Google Colab, source: 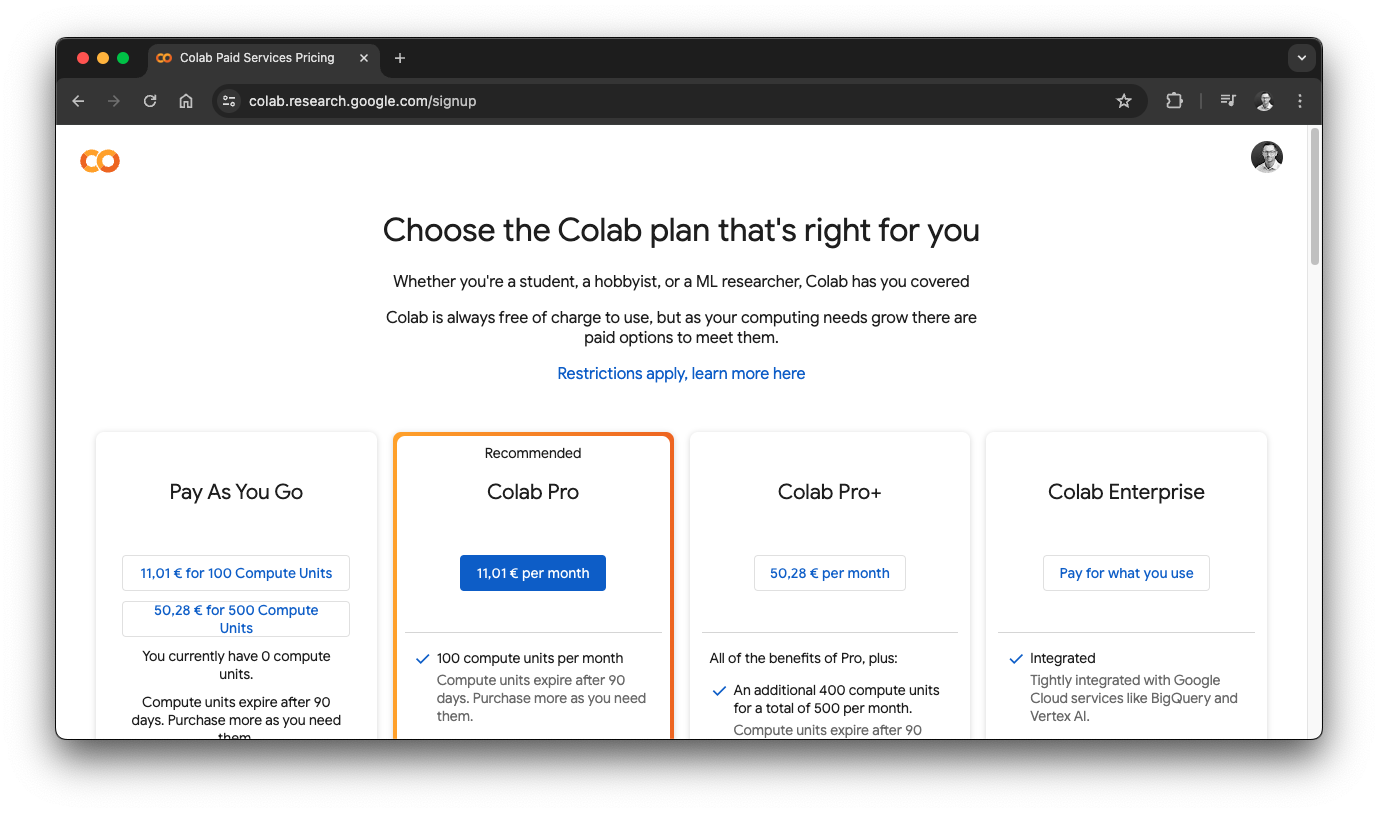 Google Colab pricing, source:
Google Colab pricing, source:  Vertex AI Workbench notebook
Vertex AI Workbench notebook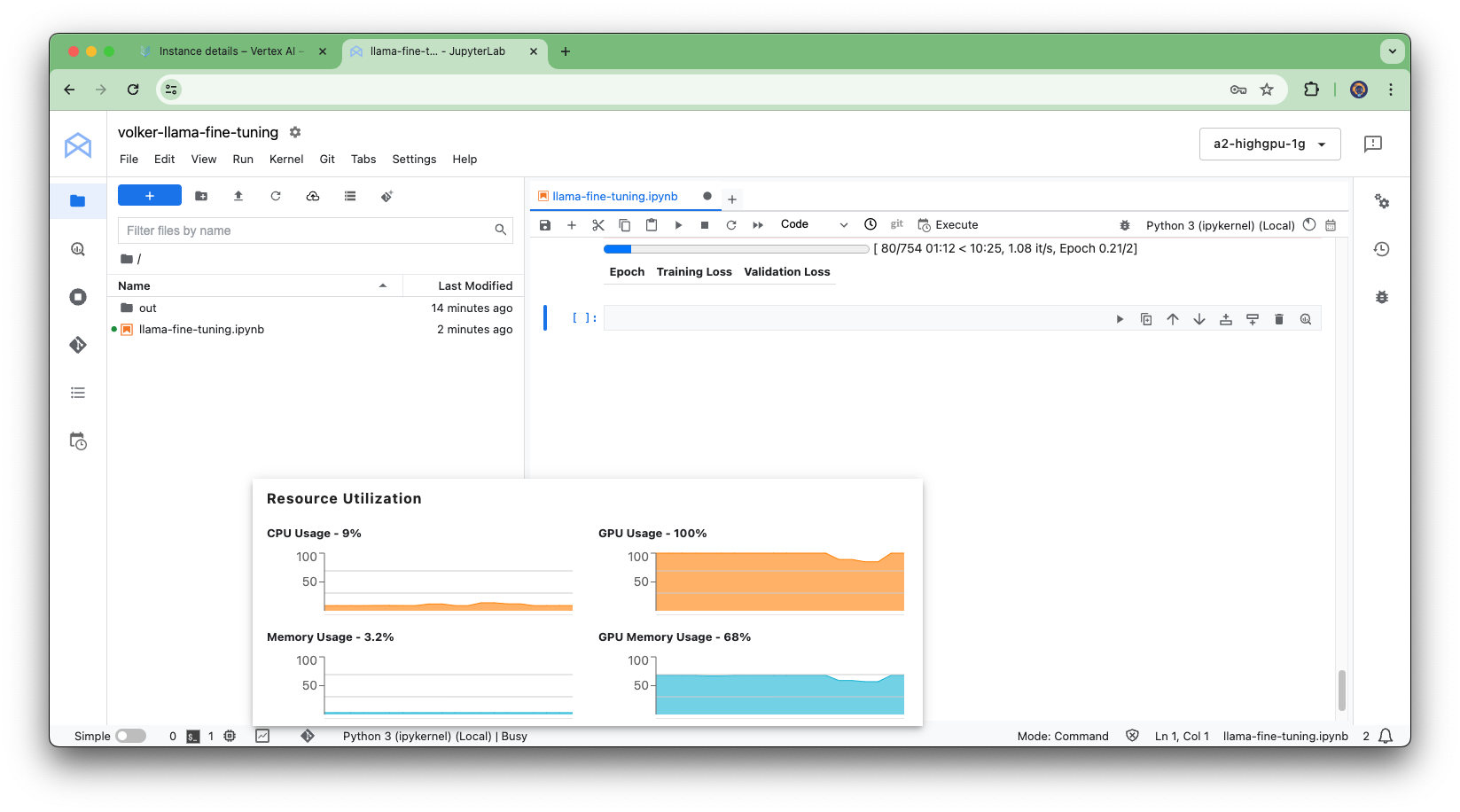 Fine-tuning progress
Fine-tuning progress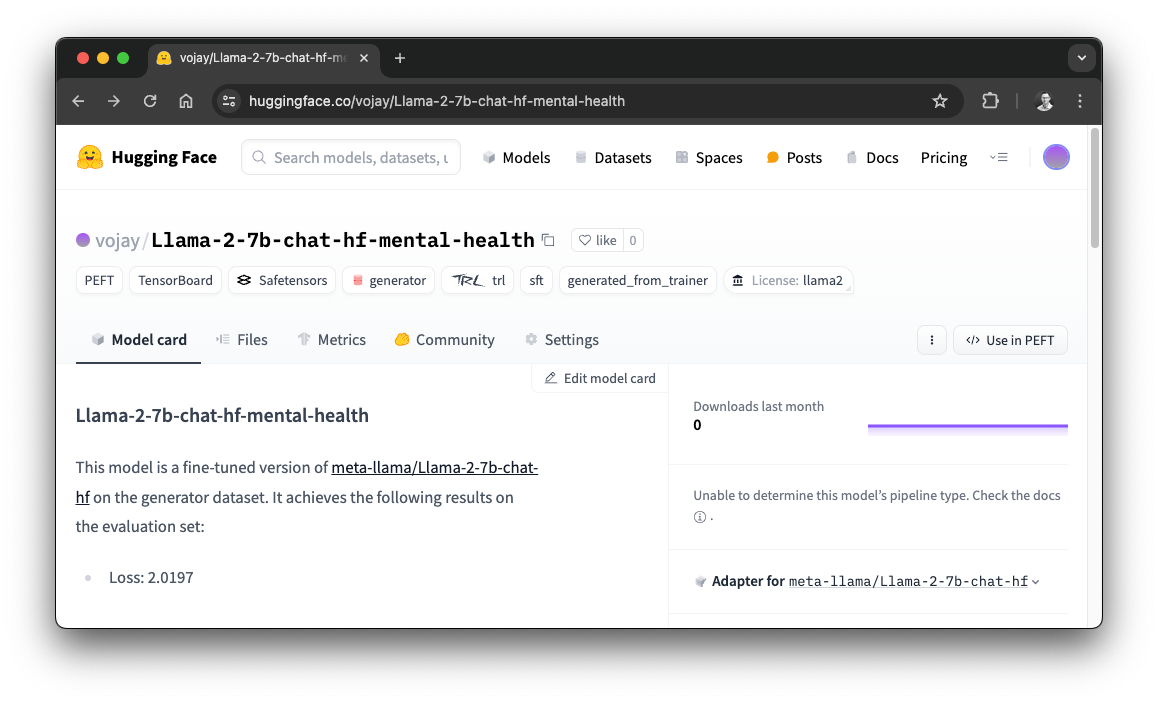 Fine-tuned model on Hugging Face
Fine-tuned model on Hugging Face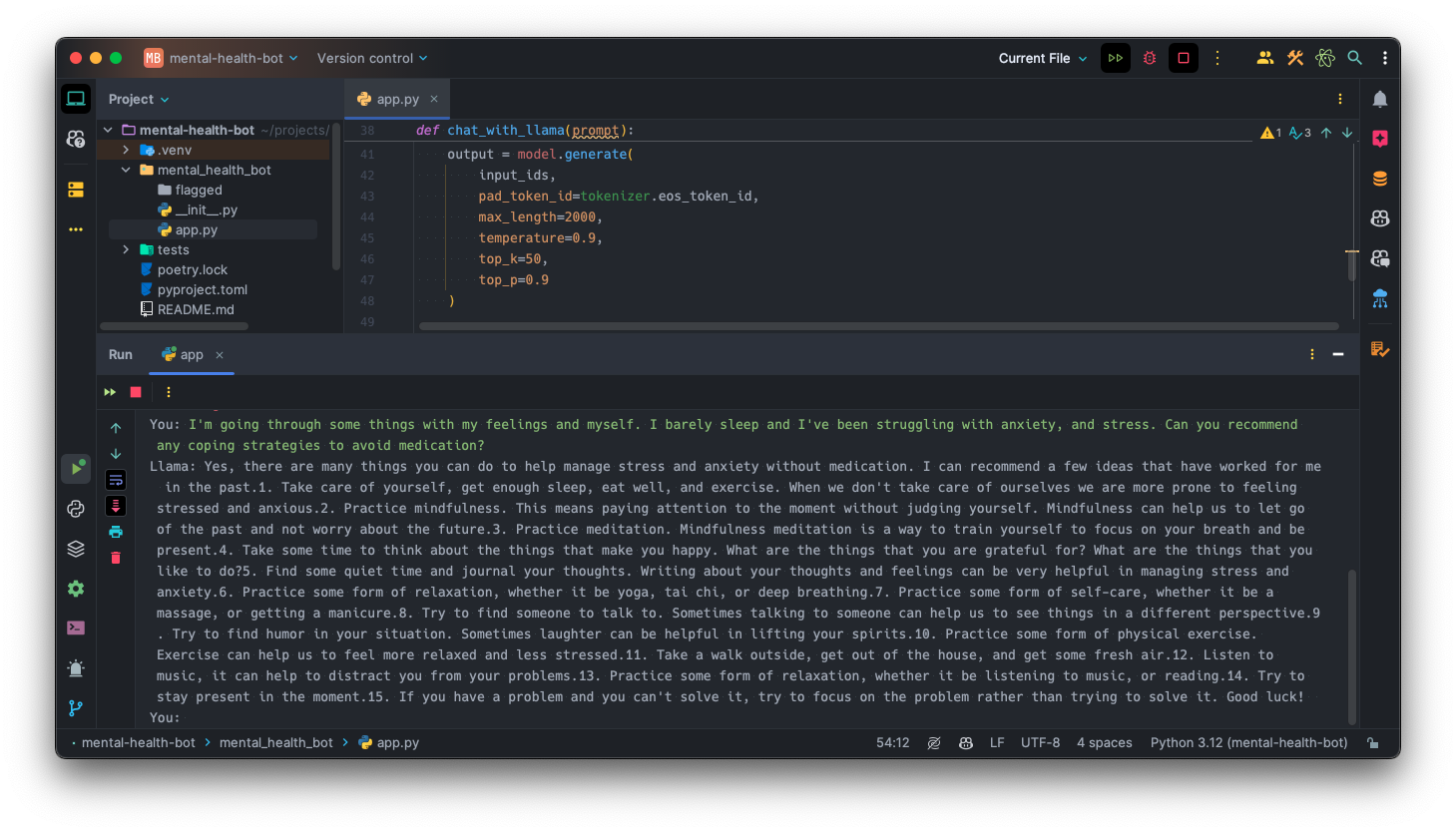 AI-powered mental health chatbot
AI-powered mental health chatbot Hackthon, generated with
Hackthon, generated with 


{kind=link}