In the ever-evolving landscape of Data Engineering, workflow orchestration plays a crucial role in managing complex data pipelines, machine learning processes, and other automated tasks. One of the most well-known solutions for these challenges is Apache Airflow.
Apache Airflow is an open-source platform that allows users to programmatically author, schedule, and monitor workflows using Python. Workflows are represented as Directed Acyclic Graphs (DAGs), where each vertex in the graph corresponds to a unit of work (task).
However, there are alternative solutions available to tackle similar problems, such as Prefect, Dagster, Luigi, and Mage AI, to name just a few.
In some cases, environments and workflows can be efficiently managed with much simpler solutions, like cron on Unix-based operating systems. You’d be surprised how many orchestration problems can be resolved effectively using just cron and Bash scripts.
On the other hand, in environments where workflows grow to a massive scale—like at Netflix—the orchestrator must handle hundreds of thousands of workflows and millions of jobs every day while operating under strict Service Level Agreements (SLAs). This is certainly not a task I would advise tackling with basic cron scheduling.
In this context, Netflix recently open-sourced Maestro, a workflow orchestrator designed to manage and schedule workflows at a massive scale. In this article, we will compare Netflix Maestro and Apache Airflow to determine whether they are competitors or companions in workflow orchestration.
Rather than positioning these tools against one another, we will explore how each addresses the demands of modern data workflows and how they might complement each other in different scenarios. By the end of this article, you will gain a clearer understanding of each tool’s unique strengths, practical use cases, and how to leverage them effectively in your Data Engineering projects.
Disclaimer: this article reflects the current state of the Netflix Maestro project. There are frequent changes to be expected in the future, which can invalidate parts of this article.
I would like to highlight three articles from the Netflix Technology Blog that provide an excellent overview of Maestro and its utilization:
I hope this article complements these by placing Maestro into perspective within the existing orchestration landscape.
Apache Airflow
Apache Airflow represents workflows as Directed Acyclic Graphs (DAGs), where each node is a task and edges define the dependencies between these tasks. This approach allows for flexibility and extensibility, making it a favorite among many Data Engineers.
Often, workflows are so called Extract, Transform, Load (ETL) processes (or ELT), but in fact, Airflow is so flexible that any kind of workflow can be implemented.
Example Airflow DAG for an ETL workflow
Airflow comes with a web interface which allows users to manage and monitor the DAGs. Airflow has four main components:
🌎 Webserver: Serves the Airflow web interface.
⏱️ Scheduler: Schedules DAGs to run at the configured times.
🗄️ Database: Stores all DAG and task metadata.
🚀 Executor: Executes the individual tasks.
When it comes to the database and executor, Airflow is very flexible. The SequentialExecutor for instance can be used for local development and runs one task at a time, while the CeleryExecutor or KubernetesExecutor allows for parallel execution on a cluster of worker nodes.
While typically MySQL or Postgres are used as a database, Airflow also supports SQLite as an embedded database, which makes it possible to run a lightweight setup on your local machine.
Based on Airflow 2.9.3, this is a minimal DAG using the TaskFlow API:
fromairflow.decoratorsimportdag,task@dag(schedule=None)defsimple_dag():"""
Minimal DAG, no start_date needed when schedule is set to None
"""@taskdeftask1()->str:return"Task 1"@taskdeftask2(value:str):print("Task 1")task2(task1())simple_dag()
Run Airflow
Running Airflow locally utilizing Docker is a common approach and very well documented.
To deploy Airflow on Docker Compose, fetch the latest docker-compose.yaml provided by Airflow, which is version 2.9.3 currently. However, concepts presented in this article also apply to future versions.
Usually, Airflow loads example DAGs with the given configuration. To keep our setup clean, let’s disable this within the docker-compose.yaml, by changing this line:
AIRFLOW__CORE__LOAD_EXAMPLES:'true'
to:
AIRFLOW__CORE__LOAD_EXAMPLES:'false'
Next step is to initialize Airflow, which means to apply required database migrations as well as creating the first user account. This procedure is also provided with the docker-compose.yaml, so we can simply execute:
dockercomposeupairflow-init
Finally, let’s start Airflow and all related services with:
dockercomposeup
The webserver is available at: http://localhost:8080. The default account has the login airflow with password airflow.
To summarize all steps in one script:
# create new project foldermkdir my_airflow_project &&cd my_airflow_project
# download Docker Compose definition
curl -LfO'https://airflow.apache.org/docs/apache-airflow/2.9.3/docker-compose.yaml'# setup environmentmkdir-p ./dags ./logs ./plugins ./config
echo-e"AIRFLOW_UID=$(id-u)"> .env
# change yaml to not load examples
perl -i-pe"s/(^\s*AIRFLOW__CORE__LOAD_EXAMPLES:\s*)'true'/\1'false'/" docker-compose.yaml
# init
docker compose up airflow-init
# start
docker compose up
You now have a clean setup to start our Airflow journey.
Even though this is a rather straight forward approach, I would like to also present an alternative way. Astronomer offers the Astro CLI, which hides away the steps above to make the setup even easier.
To illustrate how easy this is, the following three steps install Astro CLI, initialize a new project including all necessary files and folders and finally start Airflow locally:
brew install astro
astro dev init
astro dev start
Initialize Airflow project with Astro CLI
Start Airflow environment with Astro CLI
With the environment up and running, navigate to https://localhost:8080/, log in with user admin and password admin and start orchestrating your first workflow. When you are done, simply shut down the system via:
astro dev stop
Local Airflow UI
Tasks and Operators
Let’s have a look at some core concepts of Airflow workflows, to compare them with the corresponding Maestro component later.
A workflow is represented as a Directed Acyclic Graph (DAG), and contains individual pieces of work called tasks, arranged with dependencies and data flows.
Operators are the building blocks of workflows, containing the logic of how data is processed in a pipeline. Airflow has a very extensive set of operators available.
Once an operator is instantiated, it is referred to as a task and becomes a node in a DAG.
A task instance represents a specific run of a task and is characterized as the combination of a DAG, a task, and a point in time. Task instances also have an indicative state.
There are many more concepts, like dataset and time based scheduling but since the focus of the article is to discover Netflix Maestro while comparing it with Airflow, we keep things top-level for now. However, since I am part of the Astronomer Champions Program, expect more practical, in-depth Airflow articles in the future.
What stands out in Airflow is, that tasks can be very fine-grained and lightweight. Also with dynamic task mapping using partial and expand or projects like dag-factory, which now is part of Astronomer as well, allows for easy generation of highly complex workflows, while individual tasks can be as minimial as a basic Python function call.
fromairflow.decoratorsimportdag,taskfromairflow.operators.pythonimportget_current_context@dag(schedule=None)defdynamic_task_mapping():"""
Simplified expand demo with a custom map index template
"""@taskdeftask1(value:str):print(value)@task(map_index_template="")deftask2(value:str):context=get_current_context()context["index_name"]=valuetask1.expand(value=["hi","my","lovely","readers"])task2.expand(value=["hi","my","lovely","readers"])dynamic_task_mapping()
Airflow also becomes more convenient to use with executing tasks in dedicated environments, for example the task.virtualenv decorator allows to execute individual tasks within dedicated virutal Python environments:
fromairflow.decoratorsimportdag,task# requires requires virtualenv to be installed
@dag(schedule=None)defvenv_demo():"""
Execute tasks in isolated virtual environments
"""@task.virtualenv(python_version="3.10",requirements=["pandas==1.5.1"])deftask1():importpandasaspdimportsysprint(f"The python version in the virtual env is: {sys.version}")print(f"The pandas version in the virtual env is: {pd.__version__}")task1()venv_demo()
The library of operators is endless, and defining your own is easy:
Templating allows you to pass dynamic information into task instances at runtime. For example, you can run the following command to print the day of the week every time you run a task:
In this example, the value in the double curly braces {{ }} is the templated code that is evaluated at runtime.
Here, Airflow leverages the power of Jinja Templating. In addition to what Jinja offers, Airflow also comes with a set of variables, macros and filters, which can be used in templates by default.
From personal experience I can tell, that templating in Airflow can be a very powerful feature, but can also be confusing at times. For example: not all fields are templated, operators must define the templated fields, so that they are evaluated at runtime.
By nature, the templated code is placed within Python strings. However, with the render_template_as_native_obj parameter, which can be enabled on DAG level, you can even get native objects from Jinja templates, which allows magic like the following:
If you now have a look at the Airflow templates reference, it should become clear that this way of dynamic parameterization can allow for very elegant and efficient workflow orchestration.
Netflix Maestro
Netflix Maestro takes a distinctive approach by focusing on step-based workflows and incorporating powerful built-in patterns such as foreach loops, conditional branching, and subworkflows. Engineered to meet Netflix’s extensive data requirements, Maestro offers both horizontal scalability and robustness. Unlike traditional workflow orchestrators that only support Directed Acyclic Graphs (DAGs), Maestro offers acyclic and cyclic workflows, providing various reusable patterns for efficient workflow design.
In its current open-source version, Maestro comes with a REST API to create, run and interact with workflows, the engine component which holds logic to execute and handle different types of workflow steps as well as a powerful Simple Expression Language (SEL) to dynamically evaluate parameters and control workflow execution.
Example Maestro DAG
Maestro comes with an API which allows to manage and monitor the DAGs. Currently, Maestro has four main components, along with a common component:
🚀 Engine: Step execution and DAG engine, task translation, and DAO implementation.
🌎 Server: Spring Boot based Maestro application offering an API to interact with workflows.
📝 SEL: Simple Expression Language which evaluates Maestro parameters to create dynamic workflow execution.
🗄️ Persistence: Provides an implementation of the Conductor DAO interfaces using CockroachDB as the persistent data store.
Maestro provides multiple domain specific languages (DSLs) including YAML, Python, and Java, for end users to define their workflows, which are decoupled from their business logic. Users can also directly talk to Maestro API to create workflows using the JSON data model. In the current open-source release, users are limited to the Maestro API, which is part of the maestro-server Spring Boot application.
But good news: there is an open issue already, to add Maestro DSL and client libraries. Once this is resolved, the value of this project will increase a lot, since usability plays an important role to support different use cases and increase acceptance.
Here is what we need to get Maestro running locally:
Git
Java 21
Gradle
Docker
I am running it within the following environment:
Apple MacBook Pro
CPU: M1 Max
Memory: 64 GB
macOS: Sonoma 14.4.1
To manage my Java installations, I am using Homebrew, which is a package manager for macOS to install a wide range of package, in combination with jenv to manage different Java environments and switching between them easily.
As a first step, let’s ensure to have Java 21 available and activated:
While watching the logs, I was very happy to learn that Maestro is using Testcontainers to start CockroachDB with the necessary configuration.
Testcontainers is an open-source framework for providing throwaway, lightweight instances of databases, message brokers, web browsers, or just about anything that can run in a Docker container. I am using it in various projects, not only for local environments but also within unit and integration test implementations.
Maestro startup
Maestro Docker setup after startup
After the startup is completed, the following services are available:
CockroachDB UI runs on http://localhost:50157/
Maestro API running on http://localhost:8080/api/v3/
to make a cURL request to the API to create the workflow:
curl -s-X POST \--header"user: tester"'http://127.0.0.1:8080/api/v3/workflows'\-H"Content-Type: application/json"\-d @maestro-server/src/test/resources/samples/sample-dag-test-1.json | jq .
Create workflow
Thanks to Testcontainers and Gradle, getting Maestro up and running locally is rather easy. However, I would argue that with the ecosystem of Airflow, using Docker Compose or the Astro CLI tool it is even easier to get started with Airflow. But of course, this is comparing a very early open-source project with the most sophisticated open-source orchestrator.
Steps and Step Runtimes
Workflows have a list of steps, while a step has an ID, name, description, params, tags, timeout duration, type, an optional subtype, failure mode, transition, retry policy, dependencies and outputs.
In addition to logical workflow control steps like foreach and subworkflow, two notable step types in Maestro are Notebook and Titus. Titus is Netflix’s container management platform that offers scalable and reliable container execution, along with cloud-native integration with Amazon AWS. It can run images packaged as Docker containers while enhancing security and reliability during container execution. It should be mentioned, that the Titus repo has been archived and is no longer in active development.
It is also worth noting that some step types mentioned in previous articles, such as Spark, are currently missing from Maestro’s offerings.
Steps are executed within step runtimes, they hold the execution logic. It is expected to be stateless and thread safe. The execution offers at-least-once guarantee. Therefore, the logic implemented in runtimes should be idempotent.
What I personally like is, that even though the ecosystem is made for a complex architecture of high scale, implementing step types including the runtime is straight forward. I can clearly see how the library of step types will increase over time, now with Maestro being open-sourced.
Currently, there are the following implementations of StepRuntime as part of the open-source project:
ForeachStepRuntime
NoOpStepRuntime
SleepStepRuntime
SubworkflowStepRuntime
StepRuntime implementations
The step runtimes and step types are configured in java/com/netflix/maestro/server/config/MaestroWorkflowConfiguration.java. For example:
@BeanpublicSleepStepRuntimesleep(@Qualifier(STEP_RUNTIME_QUALIFIER)Map<StepType,StepRuntime>stepRuntimeMap){LOG.info("Creating Sleep step within Spring boot...");SleepStepRuntimestep=newSleepStepRuntime();stepRuntimeMap.put(StepType.SLEEP,step);returnstep;}
As you can see, the stepRuntimeMap maintains the mapping between step types and their respective runtimes.
The start function of the StepRuntimeManager is then calling the start function of the step runtime, however, it will fail if no runtime is configured for a given step.
privateStepRuntimegetStepRuntime(StepTypetype){returnChecks.notNull(stepRuntimeMap.get(type),"Cannot found the step type %s",type);}
During my testing, I encountered limitations while testing different workflow definitions, as the provided number of runtimes is limited.
The steps and step runtimes in Maestro can be compared to Apache Airflow’s operators and task instances. At this stage, however, Maestro appears somewhat limited due to its early open-source state compared to Airflow, which has a more mature ecosystem. As Maestro transitions from a high-value internal system to a public open-source project, this limitation is understandable but should be carefully considered before deciding to switch workflow orchestration solutions.
Dynamic Parameterization with SEL
Netflix Maestro includes a powerful Simple Expression Language (SEL) to dynamically evaluate parameters and control workflow execution. SEL is designed to be simple, secure, and safe, supporting a subset of Java Language Specifications (JLS) for scheduler use cases.
Key SEL Features:
Supports essential data types and operators.
Includes comprehensive statements like if, for, while, break, continue, return, and throw.
Provides access to math functions, UUID generation, and date/time manipulations.
Here is a simple example for Java String manipulation using SEL:
"workflow":{"id":"sel_demo","name":"SEL Demo Workflow","description":"Demonstration of SEL within Maestro","params":{"greeting":{"type":"STRING","expression":"String.join(' ', 'Hello', 'Maestro!')"}},
Coming from a Software Development background, being able to use subset of Java classes and functions to handle dynamic parameters feels powerful and natural. This feature can be compared to how Airflow leverages the power of Jinja Templating. As mentioned earlier, Airflow also comes with a set of variables, macros and filters, which can be used in templates by default. This includes useful macros, such as:
{{ ds }}: The logical date of the DAG run.
{{ ti }}: The current TaskInstance.
ds: A filter that operates on datetime objects to format it as YYYY-MM-DD.
macros.datetime: A variable to access datetime.datetime within templates.
Especially the variables to get quick access to DAG related data can be very powerful in workflow orchestration. I hope that Maestro will draw inspiration from Airflow and include more of such convenient functionality in future releases, to make SEL even more powerful.
One thing that stood out for me when checking the code of the current open-source release of Maestro is, that date functionality in SEL is realized by access to the Joda DateTime class. I am rather sure that this will be replaced with java.time soon.
Maestro’s Incremental Processing and Airflow’s Data-Aware Scheduling
Netflix leverages Maestro not only for traditional workflows but also for efficiently processing data updates using incremental processing techniques. Maestro’s Incremental Processing Solution (IPS), as detailed in the Netflix Technology Blog, utilizes Apache Iceberg to achieve data accuracy, freshness, and simplified backfills, especially when dealing with massive datasets.
Data workflows, particularly at scale, often encounter three significant challenges:
Data Freshness: Ensuring that large datasets are processed quickly and accurately for timely insights and decision-making.
Data Accuracy: Addressing late-arriving data, which can render previously processed datasets incomplete and inaccurate.
Backfills: Efficiently repopulating data for historical periods, often required due to changes in business logic or data pipelines.
Traditional approaches like using lookback windows or custom foreach patterns for backfills can be resource-intensive and cumbersome.
Netflix’s Incremental Processing Solution (IPS) tackles these challenges with a combination of Maestro and Apache Iceberg:
Micro-Batch Scheduling: Enables frequent processing of data updates (e.g., every 15 minutes) with state tracking for accurate monitoring.
Late-Arriving Data Handling: Efficiently processes late-arriving data without requiring full dataset reprocessing, significantly improving performance and reducing costs.
Simplified Backfills: Provides managed backfill support with automatic propagation of changes across multi-stage pipelines, improving engineering productivity.
A key component of IPS is the use of Incremental Change Data Capture (ICDC) tables. These lightweight Iceberg tables act as efficient change logs, capturing only the new or updated data from the source tables, along with relevant metadata. Maestro workflows can then query these ICDC tables, eliminating the need to reprocess the entire dataset and drastically reducing processing time and resource consumption. Maestro leverages SQL MERGE INTO or INSERT INTO commands to seamlessly merge these changes into the target tables, preserving data accuracy and preventing duplicates.
IPS basic overview
This approach offers numerous advantages. Beyond the cost savings achieved by processing only the necessary data, IPS ensures data accuracy by effectively handling late-arriving data. It also significantly improves engineering productivity by simplifying backfills and reducing the complexity of data pipelines. Most importantly, Maestro’s IPS integrates seamlessly with its existing workflow capabilities, facilitating easy adoption and minimizing disruption to existing pipelines.
IPS is built upon Maestro as an extension by adding two building blocks, i.e. a new trigger mechanism and step type, to enable incremental processing for all workflows. When combining these with Maestro features such as foreach patterns. Even though I could not try this approach yet with the current open-source version of Maestro, this can be a game-changer to optimize data-centric workflows.
Netflix continues to enhance IPS, focusing on supporting more complex update scenarios, tracking change progress, and further improving backfill management. This ongoing development underscores Netflix’s commitment to leveraging Maestro to build a robust and scalable platform for handling data workflows of all sizes and complexities.
Looking at Airflow, incremental data changes are mostly implemented on a different layer. For example, I recently worked on a Google BigQuery based warehouse, where data changes are stored in temporary staging tables while data is then being integrated with the BigQuery MERGE INTO statement.
However, if we focus on how well this is integrated into the orchestrator, from my perspective the relevant feature in Airflow is data-aware scheduling, which has been introduced with version 2.4.
Beyond time-based scheduling, Airflow allows DAGs to be triggered based on dataset updates. This feature is deeply integrated into the ecosystem and is nicely visualized in the Airflow UI. Each operator instance/task can define an optional outlets parameter, accepting a list of datasets produced or changed by that task.
DAGs can listen for changes to specific datasets. Airflow 2.9.3 introduced the DatasetOrTimeSchedule, enabling DAG scheduling based on either time or dataset changes. This powerful feature allows, for example, a daily data processing DAG that runs nightly to also catch up on changes if a related dataset is reprocessed during the day.
Both data-aware scheduling in Airflow and IPS in Maestro address similar challenges. However, IPS focuses on incrementally processing data within a workflow, potentially only executing relevant parts. Airflow’s scheduling is bound to the entire DAG, not individual tasks. However, with careful design, Airflow can achieve similar results by breaking down workflows into smaller, data-aware DAGs and combining them using elements like the TriggerDagRunOperator.
Maestro’s approach holds immense potential and could inspire innovations in other orchestrators. Emerging incremental processing patterns and features like IPS will empower Data Engineers to create more efficient and responsive workflows.
Comparing Maestro and Airflow
Initially, I envisioned this article as a head-to-head “Maestro vs. Airflow” comparison. However, as I delved deeper, I realized that both solutions cater to distinct use cases and shouldn’t be directly compared against each other—at least not in their current stages of development. While a direct comparison might not be entirely appropriate, I understand that readers appreciate a concise overview. So, for those who prefer a tl;dr, here’s a brief comparison just for you 💝:
Feature
Apache Airflow
Netflix Maestro
Workflow Definition
Python-based DAGs
Steps within DAGs defined as JSON via API, DSLs and UI are coming
General-purpose or data-centric workflow orchestration, diverse integrations
Large-scale data processing, ML pipelines, environments with existing Netflix infrastructure
Conclusion - Competitors or Companions
The introduction of Netflix Maestro to the open-source community opens up exciting possibilities for large-scale workflow orchestration. Its advanced features, such as Incremental Processing and the Simple Expression Language (SEL), offer innovative paradigms for efficiently managing data workflows. Meanwhile, Apache Airflow continues to be a reliable and flexible solution for a wide array of use cases, benefiting from its extensive documentation and vibrant community-driven ecosystem.
As Data Engineers, understanding the specific requirements of your workflows and aligning them with the strengths of these tools is crucial for making informed decisions. By leveraging Airflow’s flexibility alongside Maestro’s robust scalability, you can optimize your workflow orchestration strategies to meet the increasing demands of today’s data-driven environments.
From my perspective, Netflix Maestro and Apache Airflow are companions rather than competitors in the realm of workflow orchestration.
There are exciting opportunities to combine the strengths of both solutions to enhance your data workflows. For instance, you can use Airflow as the primary orchestrator to trigger complex machine learning workflows managed by Maestro, similar to how Google Vertex AI Pipelines orchestrate ML workflows. This approach allows you to offload heavy processing pipelines to Maestro while maintaining Airflow’s flexibility, especially when working with its diverse ecosystem of operators.
I believe it is only a matter of time before we see a NetflixMaestroOperator in Airflow, so that we can create something like the following:
@dag(schedule=None)defairflow_maestro():@taskdefprepare():print("preparing data")# some data pre-processing
ml_workflow=MaestroOperator(workflow_id="some-dag")prepare()>>ml_workflowairflow_maestro()
By leveraging the synergies between Apache Airflow and Netflix Maestro, you can build a highly scalable and efficient data orchestration system. This not only optimizes workflow management but also future-proofs your data infrastructure to handle growing complexity and scale.
Airflow’s maturity and comprehensive documentation make it an excellent choice for many scenarios, while Maestro presents exciting opportunities for large-scale operations, particularly as its open-source community continues to grow. Looking forward to see the evolution of this project, with important extensions like DSLs, more steps and runtimes as well as the Maestro UI.
The coexistence of these tools within the open-source realm promises ongoing innovation in workflow orchestration, benefiting Data Engineers and organizations tackling increasingly intricate data ecosystems.
Special thanks to Netflix and the Maestro team for enhancing workflow orchestration and sharing this remarkable project with the open-source community. Sharing is caring, and together, as a data community, we can elevate our workflows and create outstanding solutions.
Effective AI implementation relies not only on the quantity of data but also on technical expertise. Let's explore the significance of having a skilled data team for AI projects, learn about the Small Data movement and examine how far we can go with no-code or low-code AI platforms.
Minds and Machines - AI for Mental Health Support, Fine-Tuning LLMs with LoRA in Practice
Explore the potential of Large Language Models (LLMs) changing the future of mental healthcare and learn about how to apply Parameter-Efficient Fine-Tuning (PEFT) to create an AI-powered mental health support chatbot by example

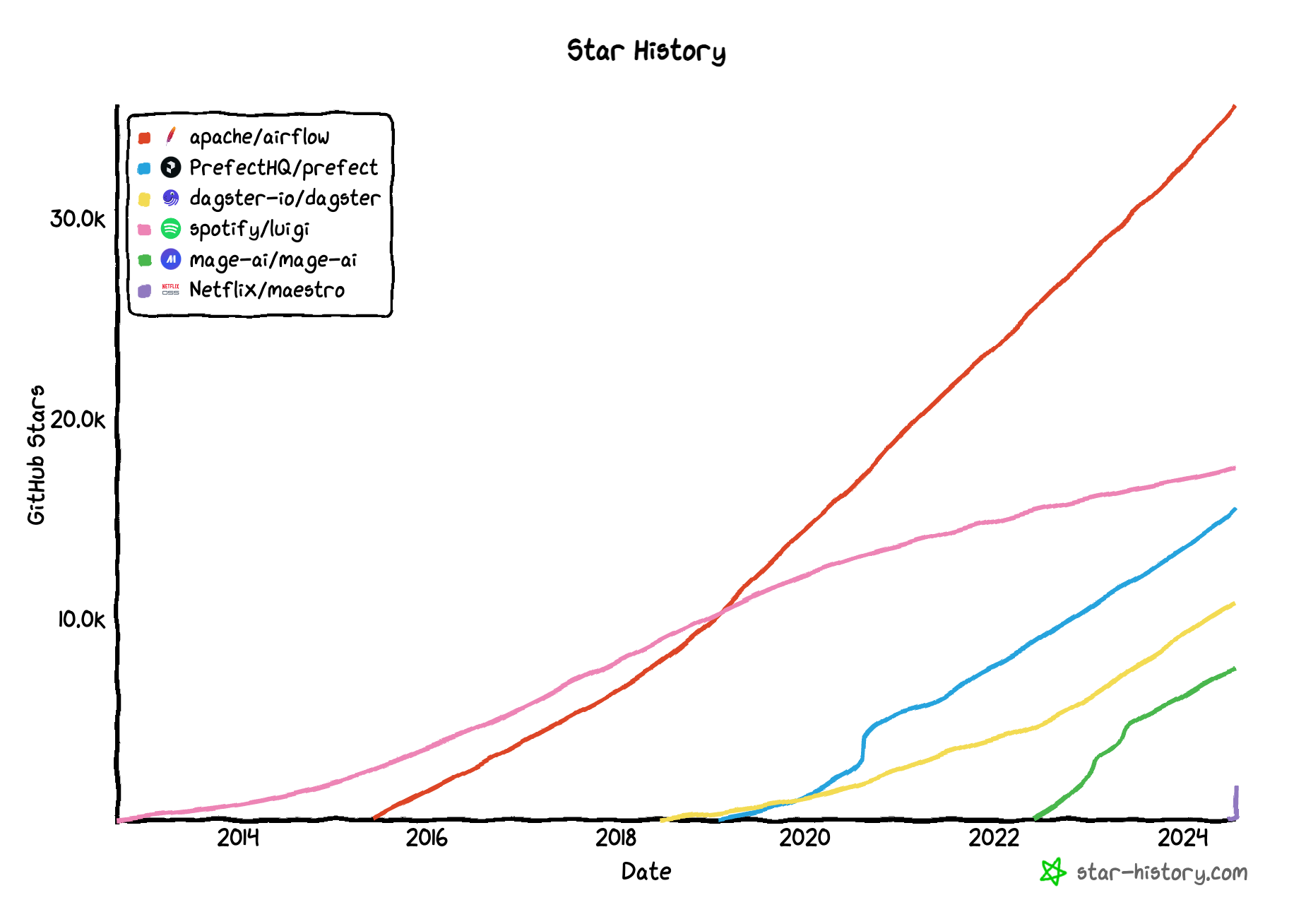 Comparing popularity of workflow orchestrators, source:
Comparing popularity of workflow orchestrators, source: 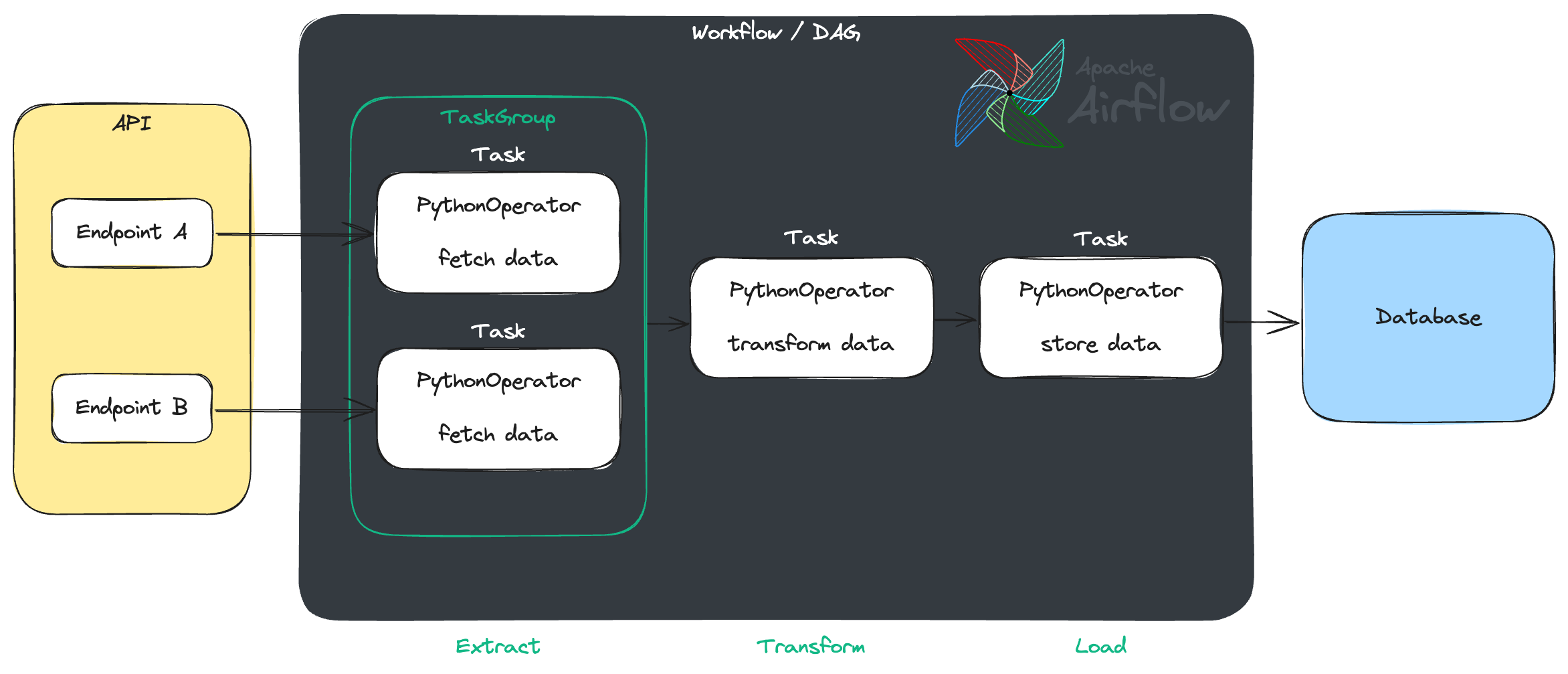 Example Airflow DAG for an ETL workflow
Example Airflow DAG for an ETL workflow Initialize Airflow project with Astro CLI
Initialize Airflow project with Astro CLI Start Airflow environment with Astro CLI
Start Airflow environment with Astro CLI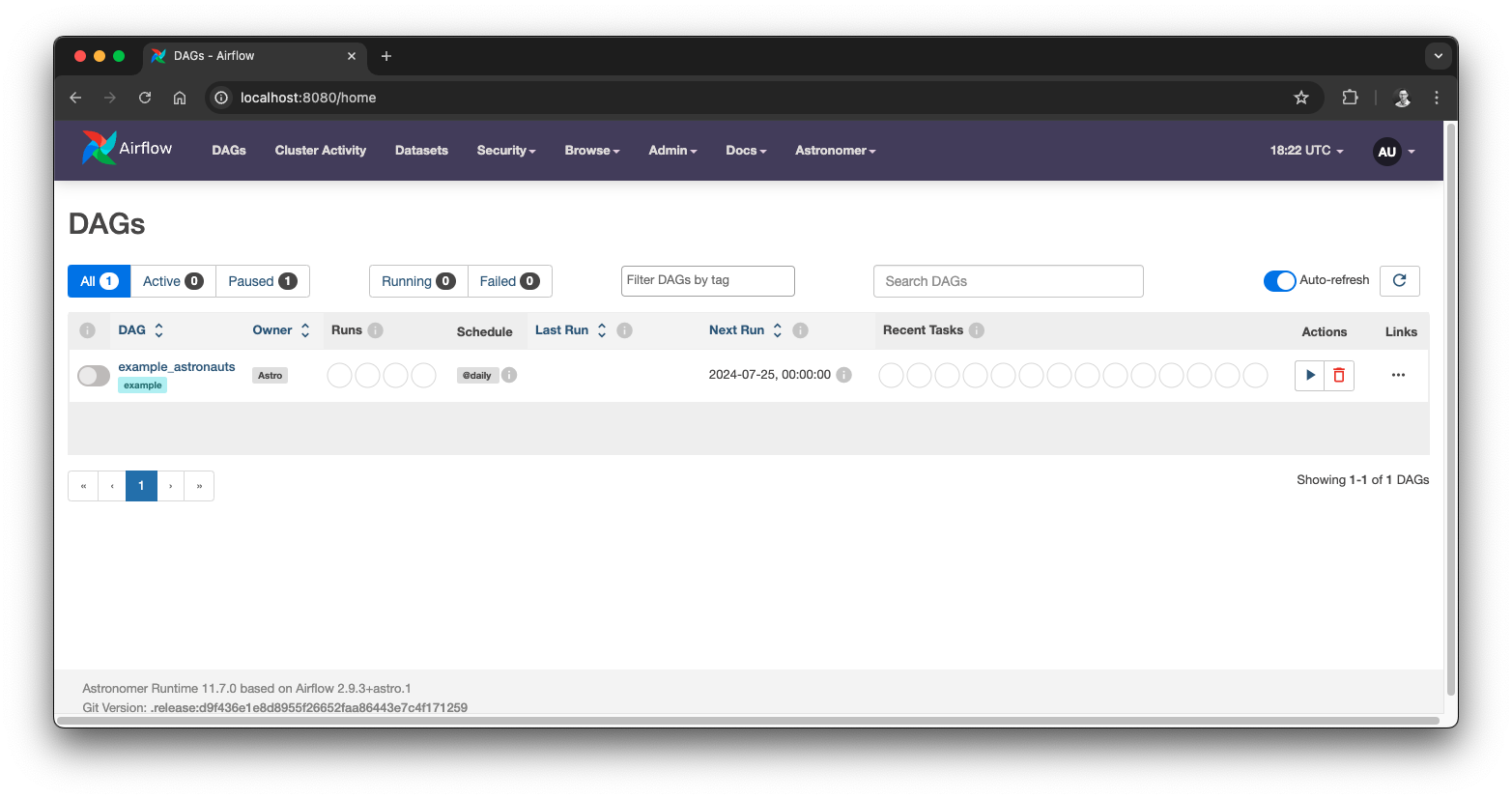 Local Airflow UI
Local Airflow UI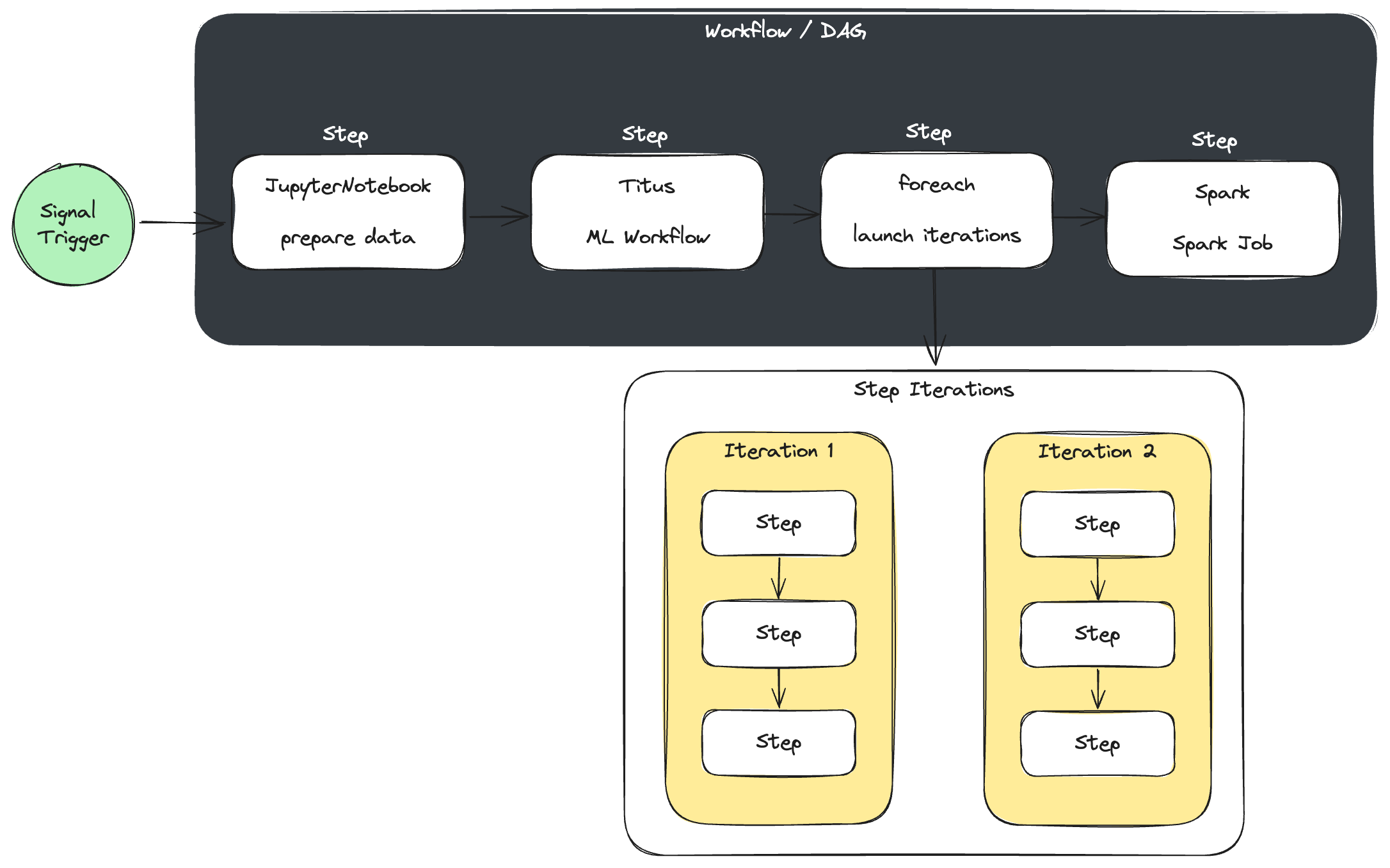 Example Maestro DAG
Example Maestro DAG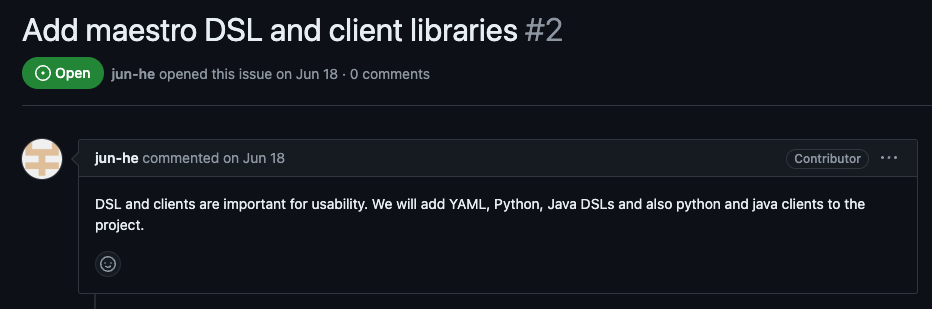 Add Maestro DSL, source:
Add Maestro DSL, source: 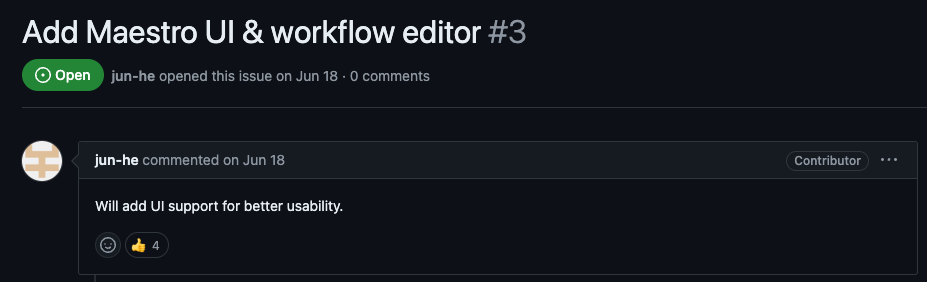 Add Maestro UI, source:
Add Maestro UI, source:  Maestro runs on Java 21
Maestro runs on Java 21 Maestro startup
Maestro startup Maestro Docker setup after startup
Maestro Docker setup after startup CockroachDB UI
CockroachDB UI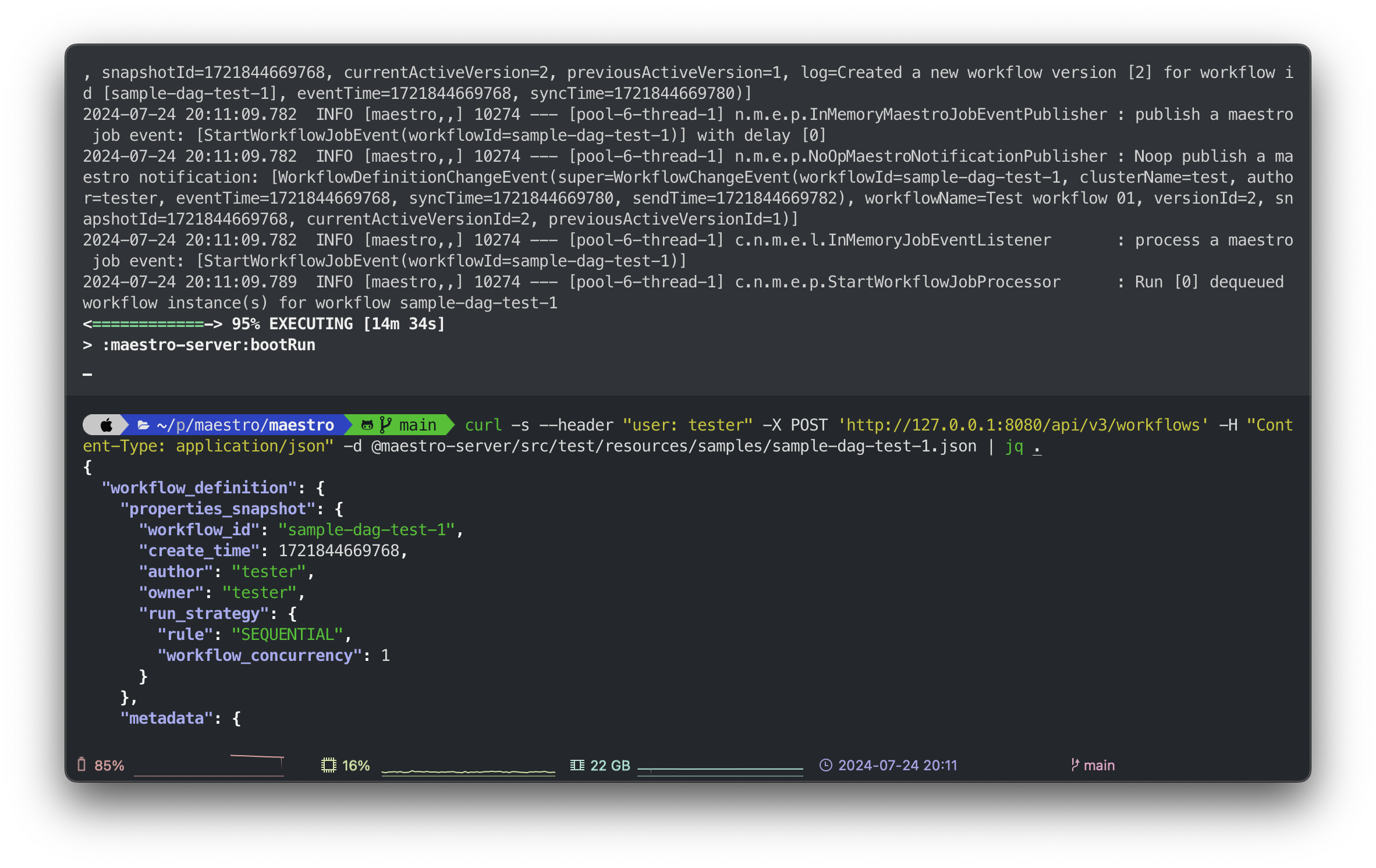 Create workflow
Create workflow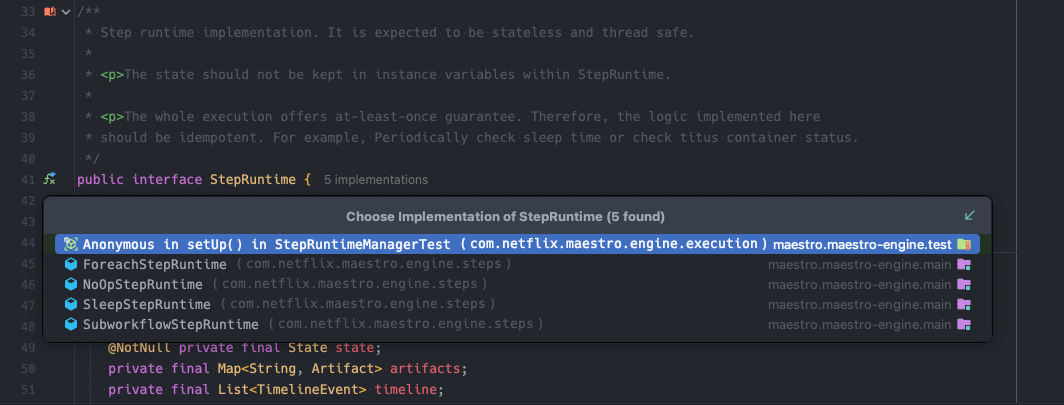 StepRuntime implementations
StepRuntime implementations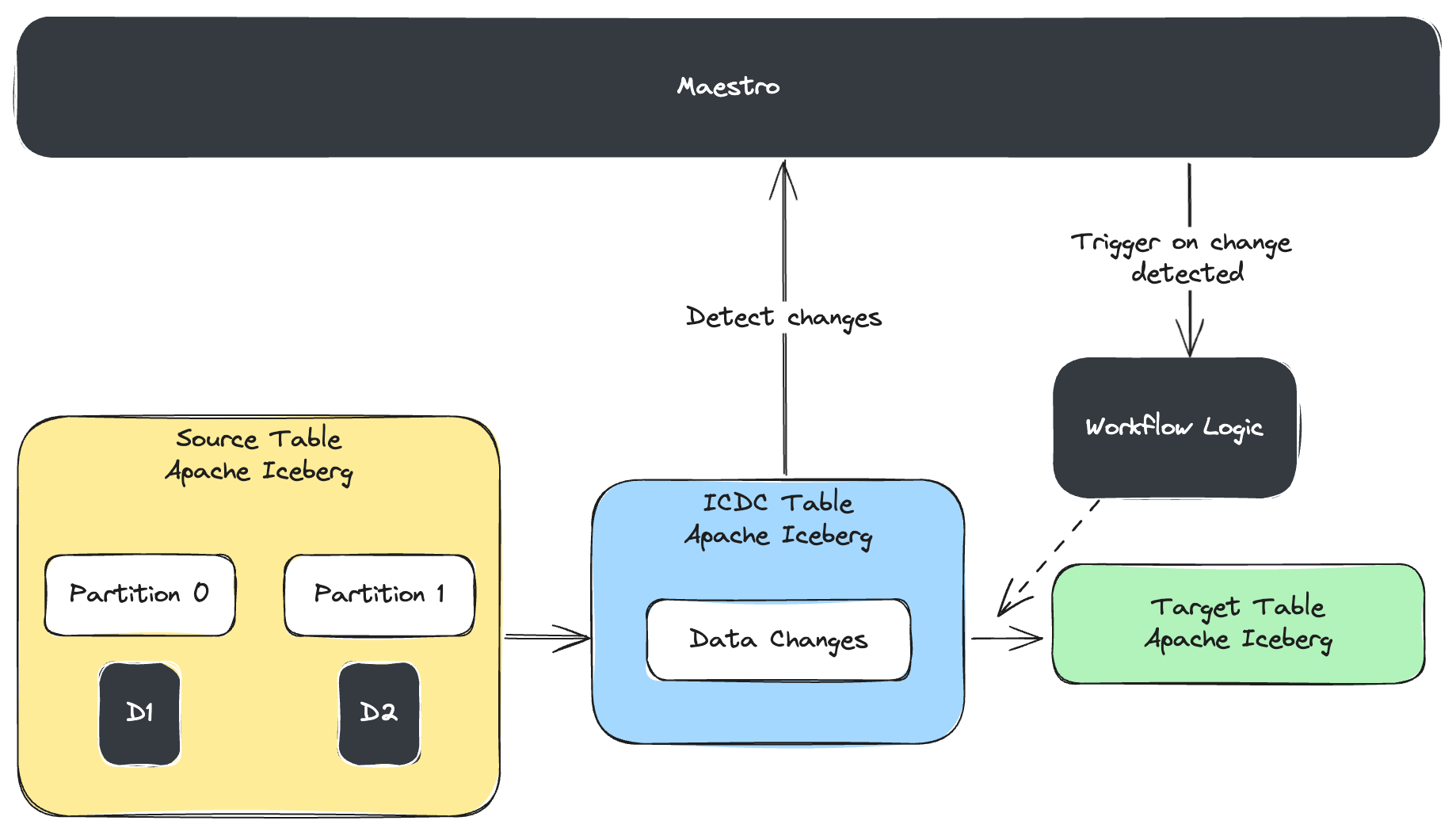 IPS basic overview
IPS basic overview


{kind=link}