I was chatting with a founder about their data capabilities. The conversation brought up, “Do I have enough data to use AI?” Yes, she does. However, my perspective is that human capital is the limitation. Am I wrong? Are there AI tools which have drag-and-drop functionality?
This question highlights a common misconception in the field of AI: that data volume is the primary barrier to realize AI projects. While data is essential, the true bottleneck often lies elsewhere. So, what’s the real hurdle? It’s human expertise, so the technical skills necessary to effectively make use of AI technologies.
The Misconception of Data Quantity
Many businesses operate under the assumption that massive amounts of data are essential for successful AI projects. The belief that more data equals better AI is widespread, but often misleading. In many cases, the quality and relevance of data outweigh quantity.
There’s a movement known as Small Data that emphasizes the use of well-curated, relevant datasets over large volumes of data. This approach recognizes that:
Modern computing power allows for efficient local-first development. Computers are now one hundred times more powerful than when the early hype of the Big Data movement was in full swing.
More data doesn’t automatically translate to better results. Recent and relevant data often holds the most value.
Large-scale Machine Learning can be expensive. Smaller, focused models can deliver significant impact, proving that sometimes, less is more.
To delve deeper into the principles of Small Data, I highly recommend exploring the Small Data manifesto at https://www.smalldatasf.com.
In the realm of medical image analysis, acquiring large labeled datasets is often challenging due to privacy concerns, the need for expert annotations, and the rarity of certain conditions. The paper Not-so-supervised: a survey of semi-supervised, multi-instance, and transfer learning in medical image analysis, highlights this challenge and explores alternative learning strategies that thrive on smaller datasets, underlining that less is sometimes more:
Semi-Supervised Learning (SSL): SSL leverages both labeled and unlabelled data. In medical imaging, where expert annotation is time-consuming and expensive, SSL can significantly improve model performance by incorporating readily available unlabelled images.
Multiple Instance Learning (MIL): MIL deals with situations where labels are available for groups of instances (e.g., a whole image) but not for individual instances (e.g., pixels or patches within the image). This is common in medical diagnoses where a doctor might label a scan as positive for a condition but not pinpoint the exact location.
Transfer Learning (TL): TL leverages knowledge gained from one domain or task to improve learning in a related but different domain or task. For instance, a model trained on a large dataset of general medical images can be fine-tuned with a smaller, specialized dataset for a specific condition, achieving high accuracy with limited data.
The paper underscores how these techniques, combined with expert knowledge in data curation and annotation, enable effective AI models even with limited data. Their work demonstrates that focusing on highly relevant, carefully annotated examples can lead to better performance than simply amassing vast quantities of less pertinent data. This is particularly relevant in medical imaging, where the small data approach empowers AI to detect rare diseases, segment anatomical structures, and perform various diagnostic tasks with remarkable accuracy, even with limited labeled samples. This reinforces the idea that with strategic data selection and appropriate techniques, smaller can indeed be better.
Example: Procedural Level Generation in Gaming
The gaming industry provides another interesting example of how small, carefully curated datasets can drive significant advancements in AI. Generating engaging and playable game levels is a complex task, traditionally requiring extensive manual design. However, recent research demonstrates how AI, trained on relatively small datasets, can automate this process effectively.
The paper Level Generation for Angry Birds with Sequential VAE and Latent Variable Evolution tackles the challenge of procedurally generating levels for the popular game Angry Birds. Generating levels for physics-based puzzle games like Angry Birds presents unique difficulties. The levels must be structurally stable, playable, and offer a balanced challenge. Slight errors in object placement can lead to unstable structures, destroyed by the physics engine or trivial solutions, ruining the gameplay experience.
For the paper an approach using a sequential Variational Autoencoder (VAE) and a relatively small dataset of only 200 levels were used. Here’s how their approach with small data achieved good results:
Sequential Encoding: Instead of representing levels as images (which is common for tile-based games), they encoded them as sequences of words, where each word represents a combination of object type, position, and rotation. This sequential representation is crucial for capturing the physics of the game and ensuring stable level generation.
Word Embedding: To handle the high dimensionality of the sequential data, they employed word embedding techniques, similar to those used in natural language processing. This compressed the data into a more manageable format, allowing the VAE to learn effectively from the smaller dataset.
Latent Variable Evolution (LVE): After training the VAE, they used LVE to fine-tune the generated levels. This optimization technique allowed them to control specific features of the levels, such as the number of certain objects or the overall difficulty, while ensuring the levels remained stable and playable.
Remarkably, their generator, trained on a dataset significantly smaller than those typically used for deep generative models, achieved a 96% success rate in generating stable levels. This demonstrates that by carefully choosing the right data representation and training techniques, even small datasets can empower AI to perform complex tasks in game development.
So again, not the amount of data was the hurdle but human expertise, to carefully choose and implement the right approach.
The Complexity of AI Solutions
AI isn’t a monolithic field. It includes a wide range of topics—from traditional Machine Learning models like decision trees and random forests to advanced architectures such as Generative Adversarial Networks (GANs) and Large Language Models (LLMs).
AI is more than LLMs, source: by author
Selecting the right tool for a specific task requires more than just access to data; it demands the technical expertise to understand the nuances of different models and their applicability. The Angry Birds level generation example showcased this perfectly, where success was driven by a clever approach to data representation and model selection.
A crucial, often overlooked, aspect of AI solutions is data preparation. Machine Learning algorithms learn from the data they are fed. For effective learning, this data must be clean, complete, and appropriately formatted. Data preparation for AI involves collecting, cleaning, transforming, and organizing raw data into a format suitable for Machine Learning algorithms. This is not a one-time task but a continuous process. As models evolve or new data becomes available, data preparation steps often need revisiting and refinement.
Furthermore, the entire AI pipeline, from data preparation and model training to prediction and monitoring, requires careful orchestration. As illustrated in the paper Hidden Technical Debt in Machine Learning Systems, the actual Machine Learning code represents only a small fraction of a real-world AI system.
This complexity underscores why technical expertise is essential throughout the AI lifecycle. Effective implementation involves several critical steps:
Data Preparation: Cleaning, transforming, and ensuring data quality is foundational. Errors here can lead to flawed models and misleading insights.
Model Development and Selection: Choosing and tuning the right model requires a deep understanding of Machine Learning algorithms and their suitability for the problem.
Deployment and Monitoring: Post-deployment, models need to be integrated into existing systems and monitored continuously to maintain performance.
Without the necessary technical expertise, businesses risk deploying AI solutions that are not only ineffective but potentially harm their objectives.
Low-Code AI Platforms
The demand for AI expertise is often outpaces creating a significant hurdle for businesses seeking to implement AI solutions. As Yaakov mentioned, human capital is the limitation. To address this gap, a variety of low-code and no-code AI platforms have emerged, offering varying degrees of simplification. Some provide intuitive drag-and-drop interfaces, while others still require some level of Python knowledge. To illustrate the spectrum of these platforms, let’s explore representative examples from major cloud providers—Google Cloud Platform (GCP), Amazon Web Services (AWS), and Microsoft Azure—as well as some notable independent solutions.
GCP: Vertex AI and AutoML
Google Cloud Platform (GCP) offers a comprehensive suite of AI/ML tools under the Vertex AI umbrella, for a wide range of use cases. Vertex AI itself is a unified platform for building, deploying, and managing Machine Learning models. It encompasses various services, including:
Vertex AI Notebooks: A managed JupyterLab environment for interactive data exploration, model development, and experimentation. This provides users with the tools they need for custom model building and training.
Vertex AI Model Registry: The Vertex AI Model Registry is a central repository where you can manage the lifecycle of your ML models. From the Model Registry, you have an overview of your models so you can better organize, track, and train new versions.
Vertex AI Feature Store: A centralized repository for storing, serving, and managing Machine Learning features. This promotes consistency and reusability across different models and projects.
Vertex AI Pipelines: This service orchestrates the entire ML workflow, automating tasks like data preprocessing, model training, evaluation, and deployment. Pipelines enable reproducible and scalable ML operations, crucial for production-level AI solutions.
One advantage of Vertex AI Pipelines compared with other cloud provider is, that it embraces open-source technologies, supporting pipeline formats from Kubeflow and TensorFlow Extended (TFX).
Focusing on Kubeflow Pipelines, these are constructed from individual components that can have inputs and outputs, linked together using Python code. These components can be pre-built container images or simply Python functions. Kubeflow automates the execution of Python functions within a containerized environment, eliminating the need for users to write Dockerfiles. This simplifies the development process and allows for greater flexibility in building and deploying machine learning pipelines.
Hello world component with the Kubeflow Pipelines (KFP) SDK:
After the workflow of your pipeline is defined, you can proceed to compile the pipeline into YAML format. The YAML file includes all the information for executing your pipeline on Vertex AI Pipelines.
Simple Vertex AI pipeline, source: by author
Another AI service is AutoML, GCP’s low-code offering. AutoML empowers users with limited Machine Learning expertise to train high-quality models for various data types (image, text, tabular, video, etc.). Its interface helps automating tasks like feature engineering, model selection, and hyperparameter tuning. This reduces development time and effort, making AI accessible to a broader audience.
Recently, the Vertex AI Agent Builder has emerged as a powerful tool for building conversational AI applications, allowing for easy integration with Large Language Models (LLMs) and backend services via a declarative no-code approach. Agents provide features like conversation history management, context awareness, and integration with other GCP services.
While AutoML offers a streamlined, no-code experience, Vertex AI in general provides the flexibility for custom model development and more intricate AI workflows, such as with Pipelines. Choosing the right approach depends on the project’s specific requirements, the available technical expertise, and the desired level of control over the model.
AWS: SageMaker Canvas
Amazon Web Services (AWS) provides SageMaker Canvas, a visual, no-code Machine Learning tool. It allows business analysts and other non-technical users to generate accurate predictions without writing any code. Users can access and combine data from various sources, automatically clean and prepare the data, and build, train, and deploy models — all through a user-friendly interface.
SageMaker Canvas tackles the entire Machine Learning workflow with a no-code approach: data access and preparation, model building, training, and deployment. It also simplifies the evaluation process with explainable AI insights into model behavior and predictions, promoting transparency and trust. While highly accessible, SageMaker Canvas might have limitations regarding customization and integration with more complex AI workflows. Its primary strength lies in empowering non-technical users to leverage Machine Learning for generating predictions and insights without needing coding skills. For more advanced AI development and deployment, AWS offers other SageMaker tools.
Azure: Machine Learning Designer
Microsoft Azure offers the Machine Learning Designer, a drag-and-drop interface for building and deploying Machine Learning models. This low-code environment enables users to visually create data pipelines, experiment with different algorithms, and deploy models without extensive coding. The Designer supports a wide range of algorithms and data sources, providing flexibility for various Machine Learning tasks.
Similar to other low-code/no-code platforms, Azure Machine Learning Designer simplifies the AI development process, lowering the barrier to entry for users with limited coding experience. Its visual interface promotes experimentation and collaboration, allowing teams to iterate quickly on their AI solutions.
Azure Machine Learning Designer offers a flexible approach to building ML pipelines, supporting both classic prebuilt components (v1) and newer custom components (v2). While these component types aren’t interchangeable within a single pipeline, custom components (v2) provide significant advantages for new projects. They enable encapsulating your own code for seamless sharing and collaboration across workspaces.
With this change, the flexibility for this platform increased a lot, so it is worth taking a look for companies utilizing Azure already.
Independent Solutions
Beyond the major cloud platforms, more and more open-source and proprietary solutions emerge to address various AI needs. These tools offer diverse functionalities and levels of abstraction. Here are a few noteworthy examples, to give you some inspiration:
Apple Create ML: The Create ML app lets you quickly build and train basic ML models right on your Mac with no code and an easy-to-use app interface. Also highly recommend for learning purposes, if you are a Mac user.
Graphite Note: This no-code platform focuses on building, visualizing, and explaining Machine Learning models, emphasizing transparency and interpretability.
Obviously AI: Targeting businesses without dedicated data science teams, Obviously AI offers a no-code platform for creating AI solutions and even provides access to data scientist support.
LangFlow: As a graphical user interface for LangChain, LangFlow simplifies the development of Retrieval Augmented Generation (RAG) and multi-agent AI applications, lowering the coding barrier for these advanced techniques.
Basic prompting flow in LangFlow, source: by author
BrainBranch: Drag-and-drop AI solutions, in closed beta by the time I am writing this article.
FlowiseAI: This open-source, low-code tool empowers developers to build custom Large Language Model (LLM) orchestration workflows and AI agents, providing more flexibility and control than fully no-code platforms.
SQL Integrations
Another fast evolving area of low-code AI solutions are SQL integrations.
Snowflake ML Functions: These powerful analysis functions give you automated predictions and insights into your data using Machine Learning using SQL in Snowflake.
Example:
-- Train your modelCREATESNOWFLAKE.ML.FORECASTmy_model(INPUT_DATA=>TABLE(my_view),TIMESTAMP_COLNAME=>'my_timestamps',TARGET_COLNAME=>'my_metric');-- Generate forecasts using your modelSELECT*FROMTABLE(my_model!FORECAST(FORECASTING_PERIODS=>7));
BigQuery ML: BigQuery ML lets you create and run Machine Learning models by using BigQuery. It also lets you access Vertex AI models and Cloud AI APIs to perform AI tasks like text generation or machine translation.
Example:
-- Create remote model for Gemini 1.5 FlashCREATEORREPLACEMODEL`gemini_demo.gemini_1_5_flash`REMOTEWITHCONNECTION`us.gemini_conn`OPTIONS(endpoint='gemini-1.5-flash')-- Use ML.GENERATE_TEXT to perform text generationSELECT*FROMML.GENERATE_TEXT(MODEL`gemini_demo.gemini_1_5_flash`,(SELECT'Why is Data Engineering so awesome?'ASprompt));
Honorable Mentions
Hugging Face: The Hugging Face Hub provides a vast repository of pre-trained models and datasets, making it easy to access and experiment with state-of-the-art models without needing to train them from scratch. This simplifies one of the most resource-intensive aspects of AI development.
Hugging Face Spaces: Spaces allows for quick and easy deployment of Machine Learning models, including LLMs, as interactive web applications. With minimal coding, users can create demos and share their models with a wider audience.
Gradio and Streamlit: These Python libraries provide user-friendly frameworks for building interactive interfaces for Machine Learning models. They empower developers to quickly create custom interfaces for LLMs, enabling users to experiment with different inputs and visualize the model’s outputs without needing to write complex front-end code.
OpenAI: OpenAI caters to diverse AI development needs by combining user-friendly tools with powerful APIs. Custom GPTs empower anyone to build tailored ChatGPT assistants without coding, while the platform’s APIs unlock deeper customization and integration possibilities for more complex AI projects. These APIs can be integrated with previously mentioned solutions like LangFlow. Note: Since OpenAI and ChatGPT are well known through public media, I am not further discussing these solutions within this article.
OpenAI offers a suite of tools that cater to a range of AI development needs. For low-code development, custom GPTs provide a user-friendly way to build tailored versions of ChatGPT for specific tasks without writing code. While custom GPTs simplify interaction with the model, OpenAI also provides APIs and tools for more advanced development and customization. This combination of low-code options and robust APIs makes OpenAI’s platform suitable for a diverse user base, from those seeking quick solutions to developers building complex AI applications.
These tools, along with frameworks like LangChain for building LLM-powered applications, represent the rapid evolution of the low-code AI landscape. They empower also smaller data teams, to create sophisticated AI solutions.
However, there are things to keep in mind, no matter which tool you choose:
🏞️ Big picture: Low-code/no-code tools often focus on specific aspects of the AI workflow. It’s essential to consider the entire process, from data collection and preparation to model selection, deployment, maintenance, and translating outputs into business value. These platforms may not address every stage comprehensively.
⚙️ Hidden complexity: User-friendly interfaces can obscure the complexity of the underlying models. Troubleshooting and optimization can become challenging without a deeper understanding of how these models work.
🔧 Customization limits: No-code/low-code platforms might lack the flexibility required for specialized or highly customized applications. Extending their functionality or integrating them with existing systems may require coding skills.
📈 Interpreting results: Understanding why a model makes certain predictions is crucial, especially in regulated industries where explainability and transparency are important. Some no-code/low-code tools may not provide sufficient insights into model behavior.
🔒 Vendor lock-in: Vendor lock-in is a risk with AI platforms because migrating trained models, data, and integrated workflows to a different provider can be complex, costly, and time-consuming, potentially hindering flexibility and innovation in the long run.
🎯 Loosing focus on the why: The ease of use offered by drag-and-drop solutions can sometimes lead to implementing AI for its own sake, rather than focusing on solving a specific business problem. Maintaining a clear understanding of the objectives and desired outcomes is essential.
The AI bottleneck is not data, it’s people. The question shouldn’t be “Do I have enough data to use AI?” but rather “Do I have the necessary expertise to use AI effectively?” While data is a fundamental component, human capital is the key to unlocking AI’s full potential.
tl;dr:
🧠 Invest in human capital: Hire skilled professionals or invest in training existing staff. Consider partnerships with academic institutions or specialized firms to bridge skill gaps.
💡 Focus on relevant data: Prioritize collecting high-quality, relevant data. Implement robust data management practices to maintain data integrity. Keep the Small Data movement in mind: less is often more.
⚙️ Utilize low-code solutions wisely: Leverage these platforms to accelerate development, but recognize their limitations. Use them as complementary tools rather than complete solutions.
📚 Cultivate a learning culture: Encourage continuous learning and development to keep pace with the rapidly evolving AI landscape.
By acknowledging and addressing the human expertise bottleneck, businesses can more effectively use AI, driving innovation and achieving meaningful outcomes.
Netflix Maestro and Apache Airflow - Competitors or Companions in Workflow Orchestration?
Explore how Netflix Maestro and Apache Airflow, two powerful workflow orchestration tools, can complement each other. Delve into their features, strengths, and use cases to uncover whether they are companions or competitors.
Minds and Machines - AI for Mental Health Support, Fine-Tuning LLMs with LoRA in Practice
Explore the potential of Large Language Models (LLMs) changing the future of mental healthcare and learn about how to apply Parameter-Efficient Fine-Tuning (PEFT) to create an AI-powered mental health support chatbot by example

 Source:
Source:  Small Data, source:
Small Data, source:  Angry Birds logo, source:
Angry Birds logo, source:  Levels generated by different generators, source:
Levels generated by different generators, source: 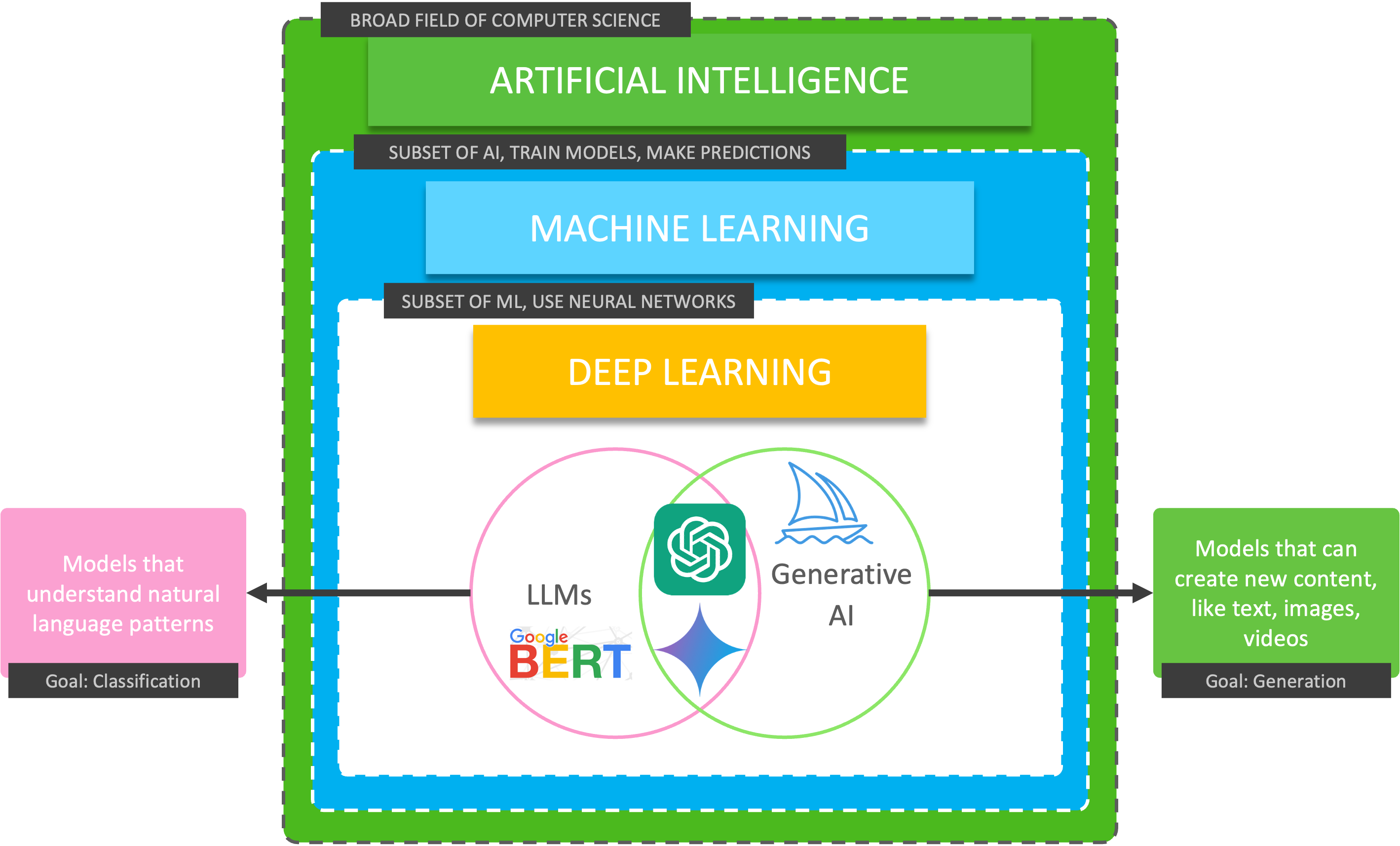 AI is more than LLMs, source: by author
AI is more than LLMs, source: by author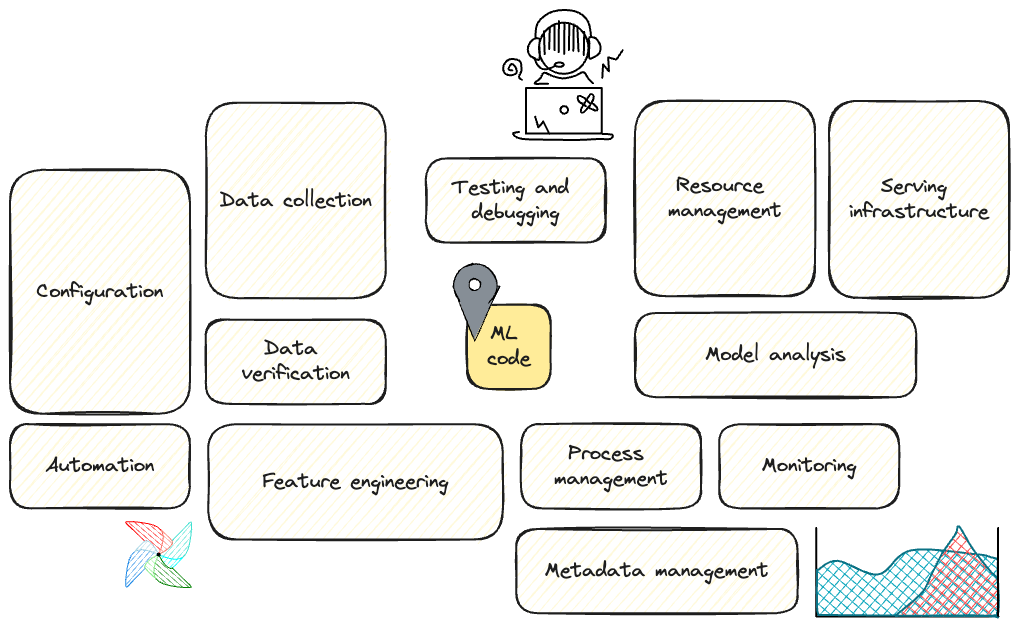 By author, adapted from:
By author, adapted from: 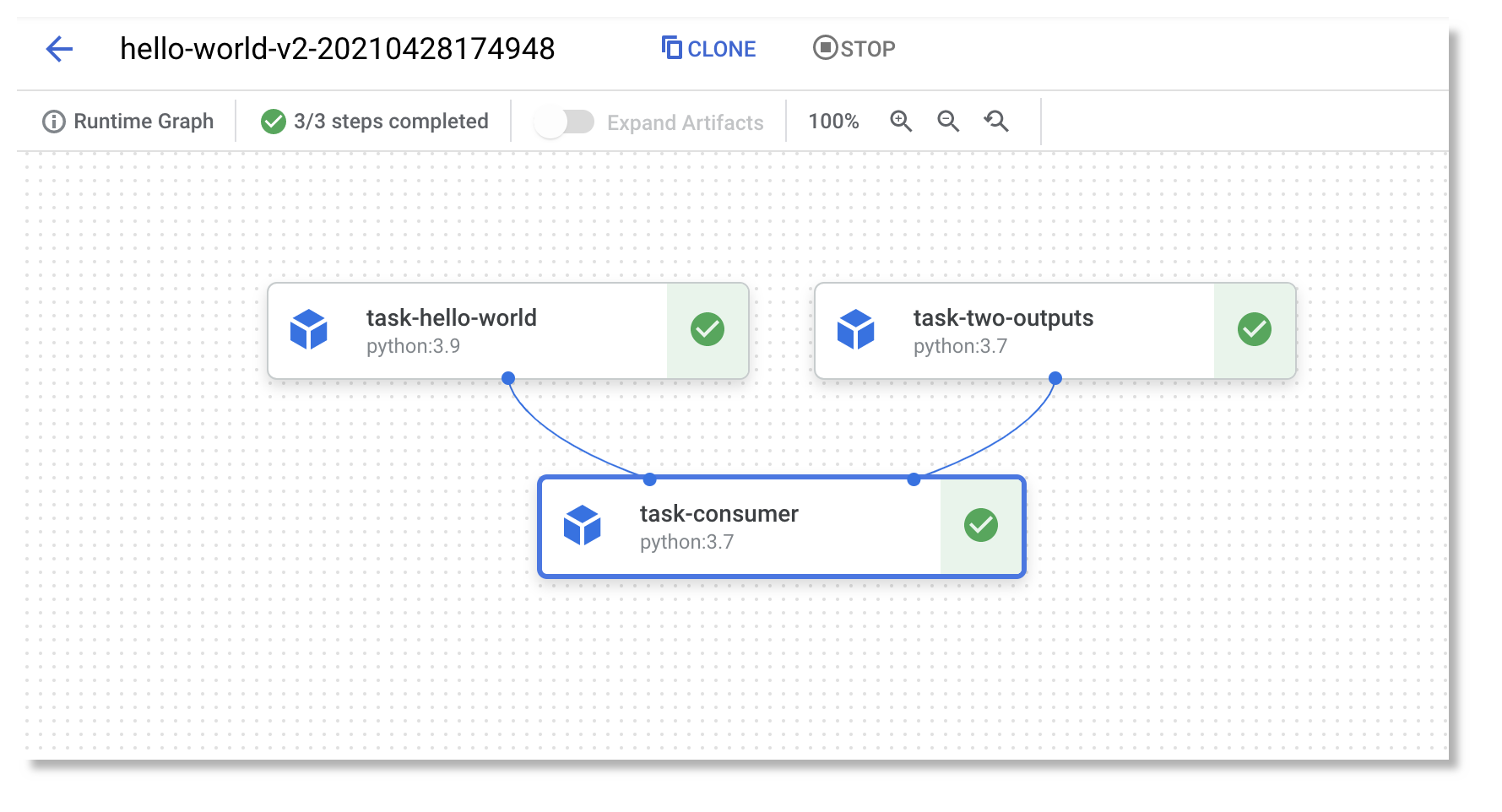 Simple Vertex AI pipeline, source: by author
Simple Vertex AI pipeline, source: by author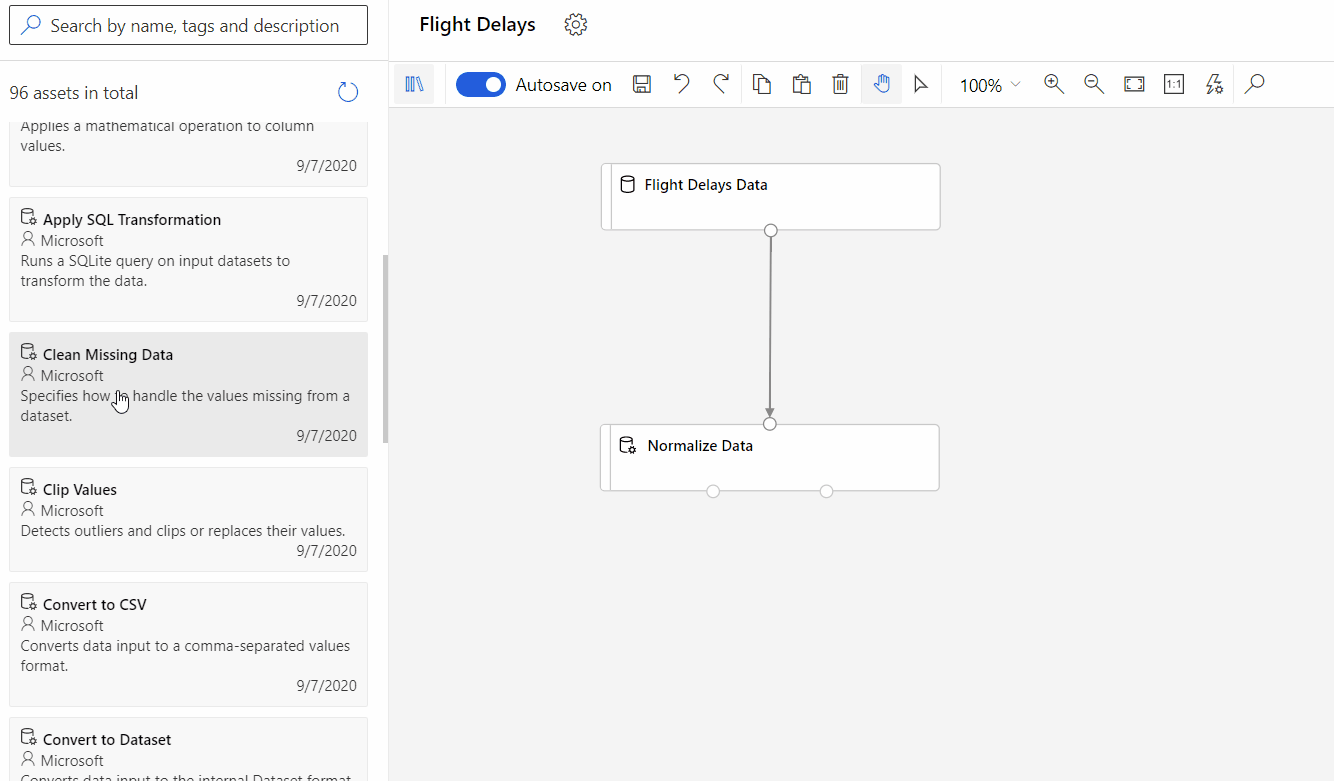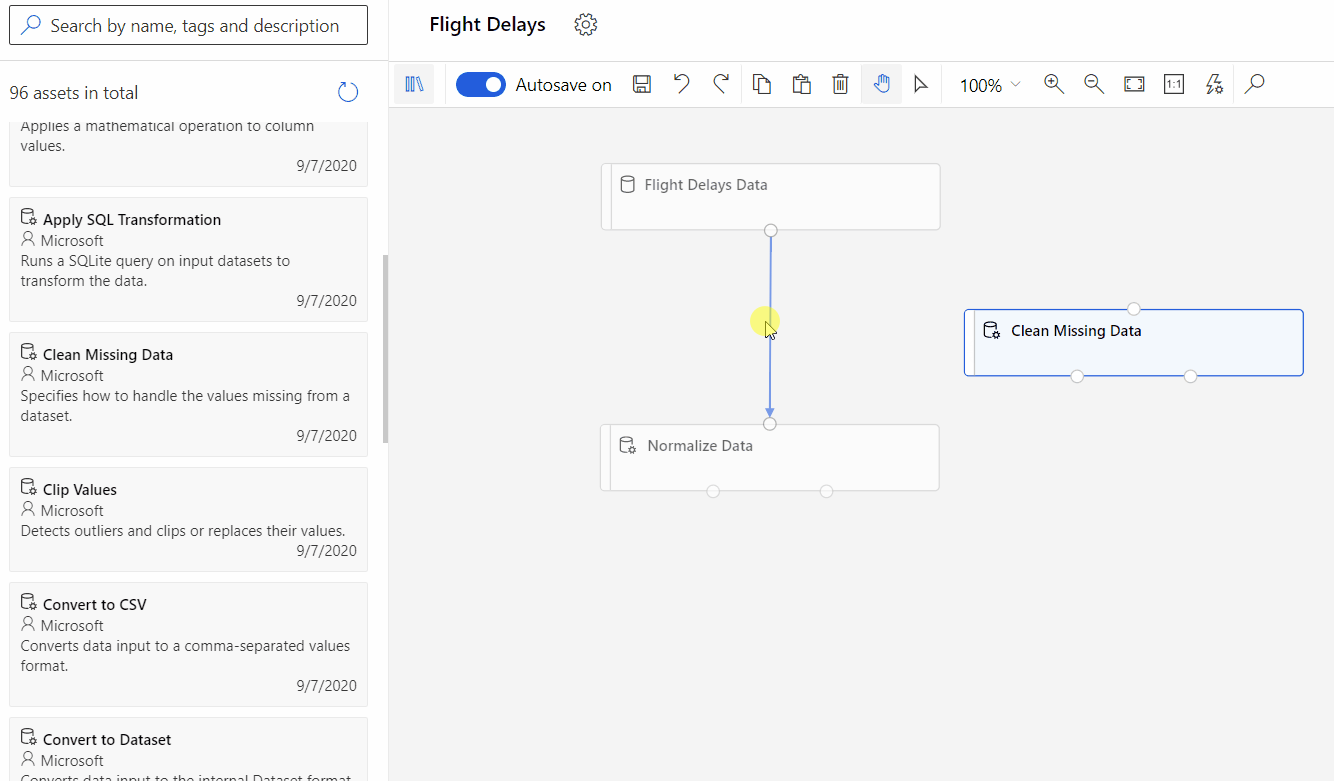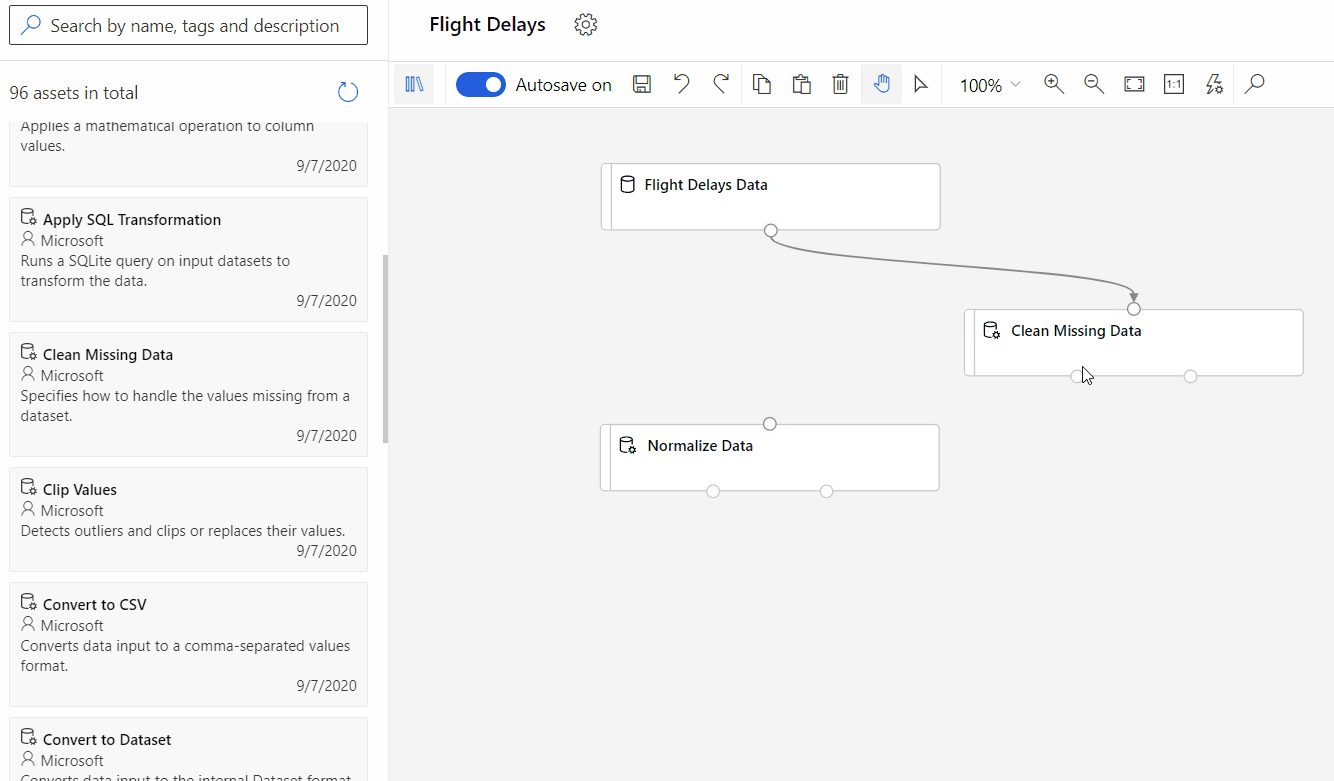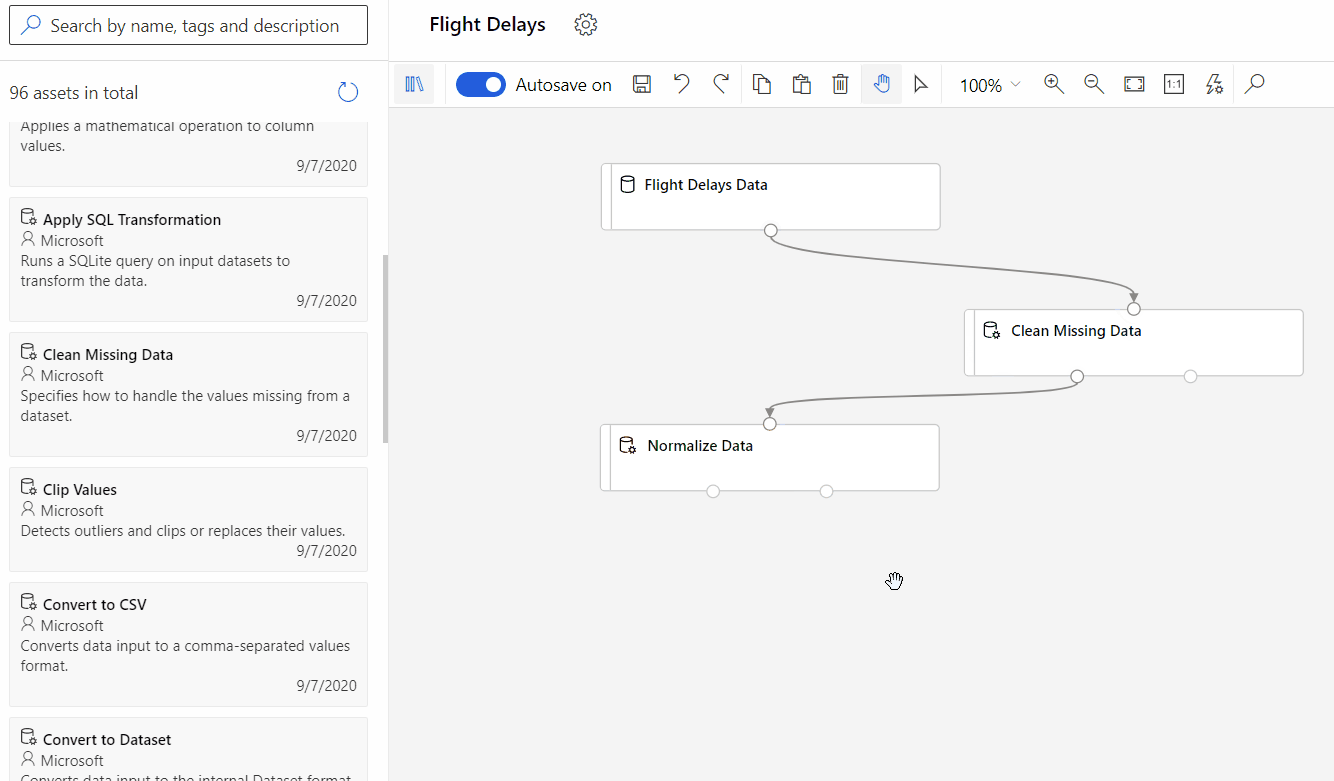 Designer drag and drop, source:
Designer drag and drop, source: 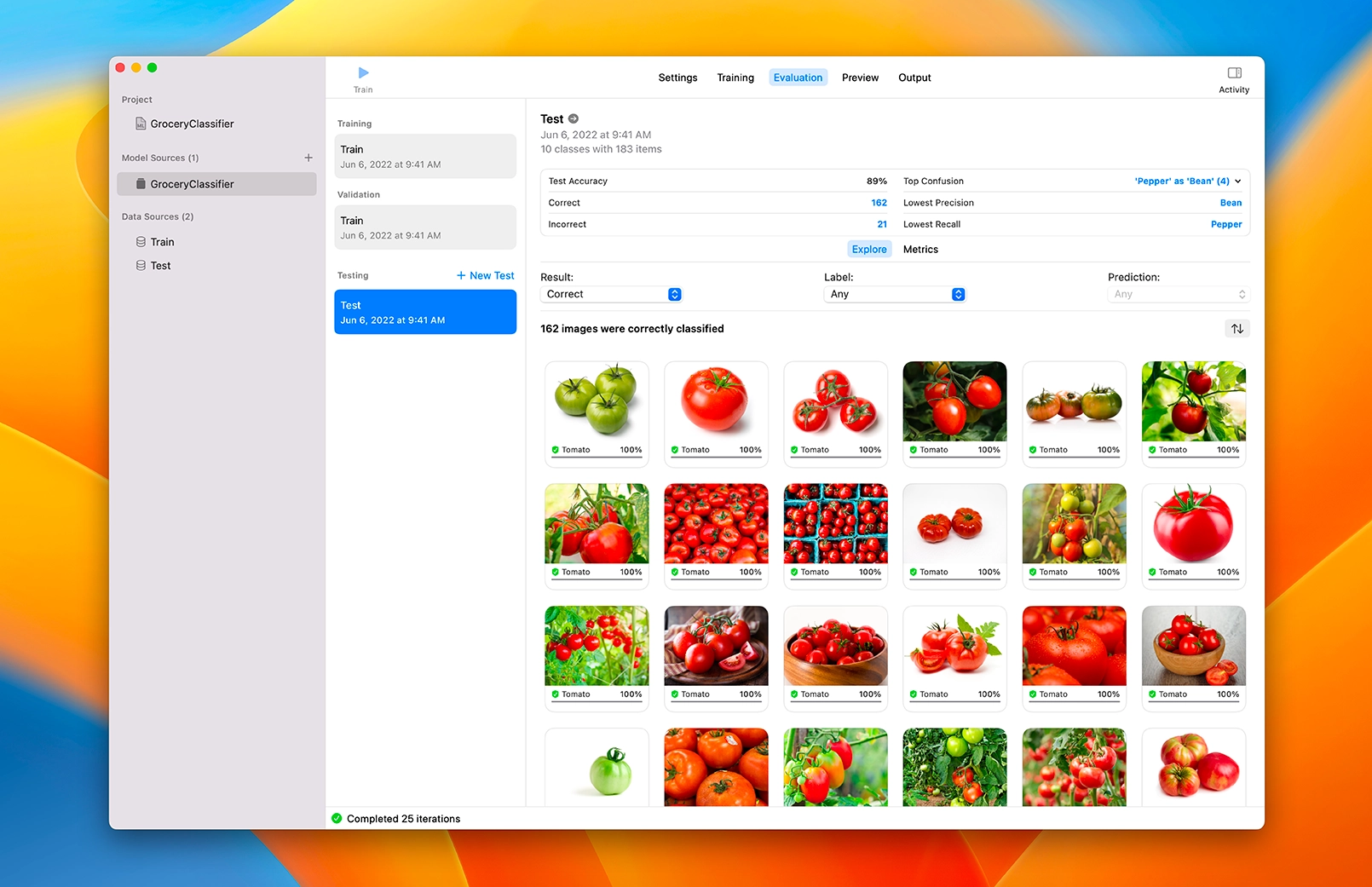 Create ML, source:
Create ML, source: 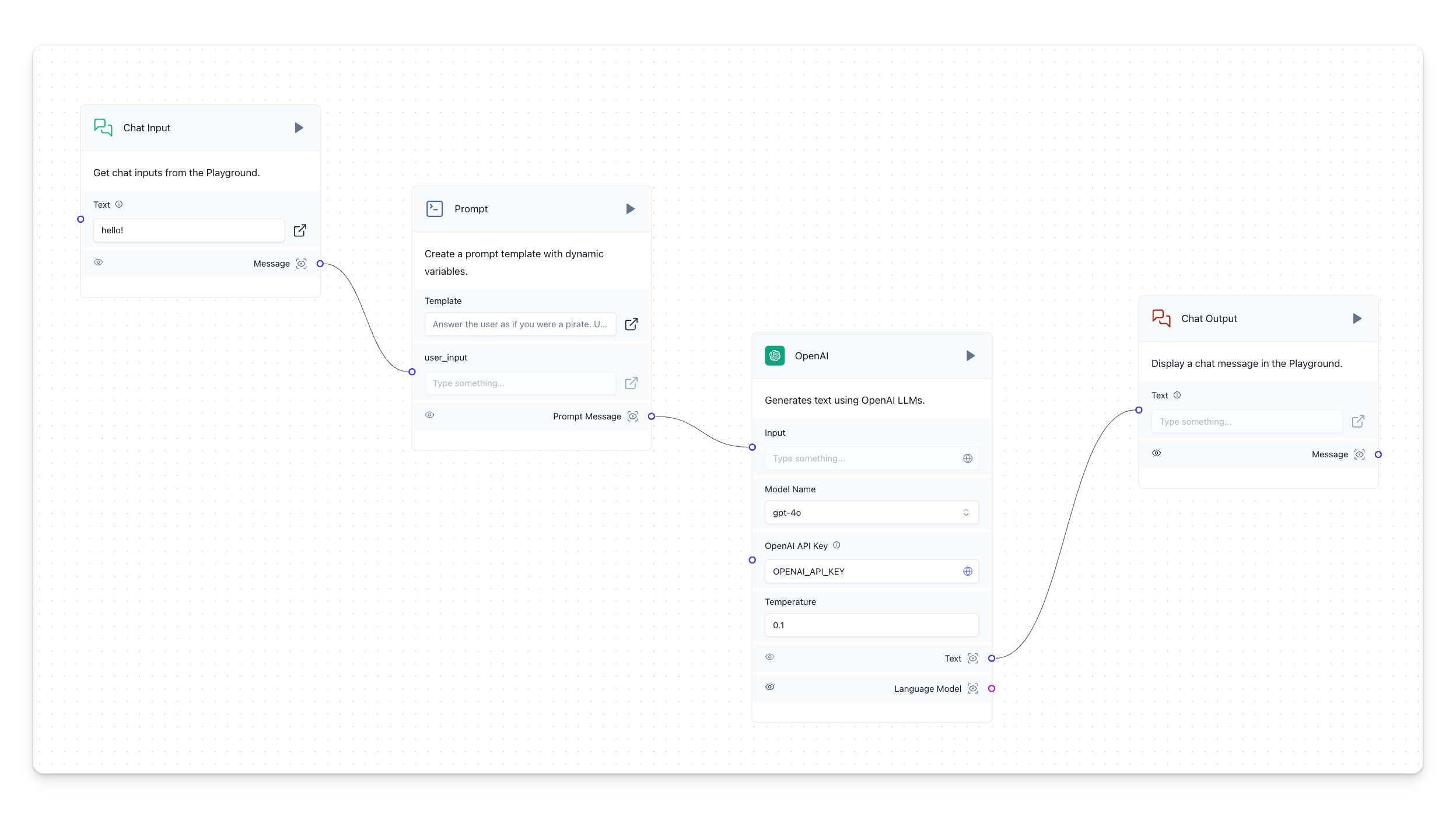 Basic prompting flow in LangFlow, source: by author
Basic prompting flow in LangFlow, source: by author


{kind=link}