


From Scrolls to Similarity Search - Building a Movie Recommender with DuckDB VSS
Learn how to use DuckDB's Vector Similarity Search extension to create a recommendation engine using semantic search and Gemini embeddings
In this article, we’ll tackle a common challenge in Airflow development: the proliferation of nearly identical DAGs for handling different data processing scenarios, especially those involving partitioned tables and historical reloads. You’ll learn how to build a single, flexible DAG that leverages Dynamic Task Mapping to process partitions in parallel, handling both daily operations and custom date range reloads with ease.
 Dynamic Task Mapping demo, source: by author
Dynamic Task Mapping demo, source: by author
🚀 Note: I published the final Airflow project on Github: https://github.com/vojay-dev/airflow-dynamic-task-mapping
Recently, I stumbled upon a common Data Engineering challenge on Reddit: “How to Leverage Data Partitions for Parallelizing ETL Workflows in Airflow?” The user, like many of us, wanted to process partitioned data in parallel for increased efficiency. This sparks a crucial question: How can we achieve true parallel processing while maintaining a clean and manageable codebase?
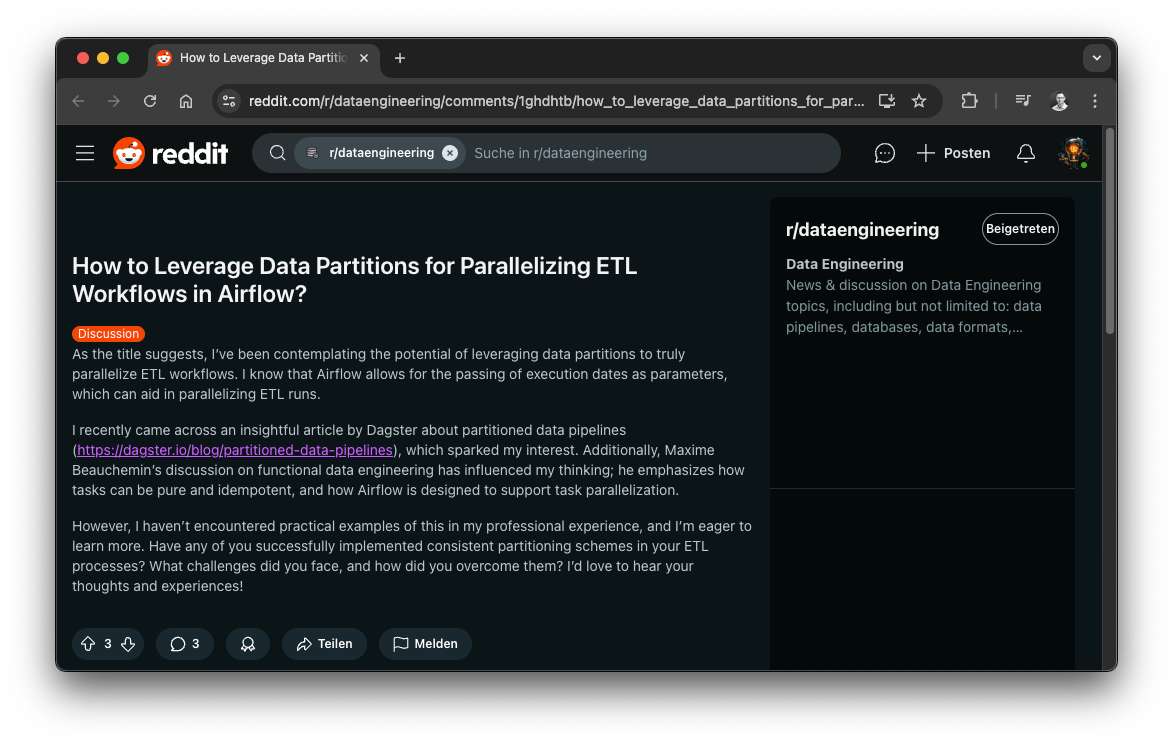 Data Engineering Reddit, source: Reddit
Data Engineering Reddit, source: Reddit
Partitioned tables are common in data warehousing. Partitions divide a table into smaller physical segments. This segmentation improves query performance. We define partitions by specifying one or more partition columns. Apache Hive, for example, supports multiple partition columns. BigQuery, on the other hand, supports only one. Here are two examples:
-- Hive (multiple partition columns)
CREATE TABLE some_schema.some_partitioned_table (
user_id INT,
event_name STRING,
created_at TIMESTAMP
)
PARTITIONED BY (country STRING, day STRING)
STORED AS PARQUET;
-- BigQuery (single partition column)
CREATE TABLE some_dataset.some_partitioned_table (
user_id INT64,
country STRING,
event_name STRING,
created_at TIMESTAMP,
day DATE
)
PARTITION BY day;While partitioning improves query performance, it also presents an opportunity: parallel write operations. The Reddit user’s question highlights this opportunity within Airflow. How can Airflow leverage table partitions for parallel processing?
Airflow offers catchup and backfill features for processing historical data. Catchup automatically creates DAG runs for past schedules. Backfill allows users to manually trigger DAG runs for a specified date range.
airflow dags backfill \
--start-date START_DATE \
--end-date END_DATE \
dag_idYou can combine these features with max_active_runs to parallelize historical loads. These built-in tools offer convenient features, like clear separation of runs in the Airflow UI. However, they also come with drawbacks:
The biggest limitation? These features lack flexibility for complex partitioning schemes. For instance, how can we efficiently parallelize across both date and country?
This limitation frequently leads to an Airflow anti-pattern: copy-pasted DAGs for different processing scenarios. Let’s explore an example:
# daily_process.py
@dag(schedule="@daily")
def process_daily_partition():
@task
def process():
# Single day, all countries
date = '{{ yesterday_ds }}'
for country in get_countries():
process_partition(date=date, country=country)
# historical_reload.py
@dag(schedule=None)
def reprocess_date_range():
@task
def process():
start_date = '{{ params.start_date }}'
end_date = '{{ params.end_date }}'
countries = '{{ params.countries }}'.split(',')
# Nested loops - even worse!
current = datetime.strptime(start_date, '%Y-%m-%d')
end = datetime.strptime(end_date, '%Y-%m-%d')
while current <= end:
for country in countries:
# Sequential processing of date-country combinations
process_partition(
date=current.strftime('%Y-%m-%d'),
country=country
)
current += timedelta(days=1)
# country_specific_reload.py
@dag(schedule=None)
def reload_single_country():
@task
def process():
country = '{{ params.country }}'
# Another sequential loop, different parameter
for date in get_all_historical_dates():
process_partition(date=date, country=country)This proliferation of DAGs leads to two major problems:
Consequences? Consider these maintenance nightmares:
Code Smell Alert: Do you see multiple DAGs with nearly identical processing logic? Do these DAGs vary primarily by schedule or parameters? It’s time for modernization!
What we really need is:
Dynamic Task Mapping in modern Airflow delivers this solution. Let’s see how.
Dynamic Task Mapping in Airflow offers a powerful way to create tasks dynamically at runtime. This dynamic creation allows your data pipelines to adapt to varying data volumes and processing needs. Unlike manually defining tasks for each partition or scenario, Dynamic Task Mapping generates tasks based on the output of an upstream task. Think of it as a “for loop” orchestrated by the scheduler, where each iteration becomes a separate task instance.
When Airflow encounters a mapped task, it dynamically generates multiple task instances. These instances are then eligible for parallel execution, depending on available worker slots and your configured concurrency settings.
Here’s how these settings interact:
parallelism setting defines the absolute upper limit.concurrency setting limits parallel tasks within that DAG.max_active_tis_per_dag further restricts parallelism for a specific task across all DAG runs.In its simplest form, Dynamic Task Mapping iterates over a list or dictionary defined directly in your DAG. The expand() function is key here. It replaces the typical direct task call and dynamically generates task instances for each item in the iterable.
@task
def process_item(item):
print(f"Processing: {item}")
items = ["apple", "banana", "cherry"]
process_item.expand(item=items)The real power of Dynamic Task Mapping shines when an upstream task generates the list of items. This pattern enables your DAG to adapt to changing data:
@task
def generate_items():
return ["dynamic_apple", "dynamic_banana"]
@task
def process_item(item):
print(f"Processing: {item}")
items = generate_items()
process_item.expand(item=items)Often, you’ll need to pass constant parameters alongside your dynamic inputs. The partial() function complements expand(), allowing you to define constant values for specific parameters:
@task
def process_item(item, connection_id):
print(f"Processing: {item} with {connection_id}")
items = ["data1", "data2"]
process_item.partial(connection_id="my_database").expand(item=items)This example efficiently passes the same connection_id to all dynamically generated process_item tasks. This shared parameter prevents unnecessary repetition and improves readability.
For scenarios involving multiple dimensions (like our date and country example), you can expand over multiple parameters simultaneously:
@task
def process_partition(date, country):
print(f"Processing partition: {date}, {country}")
dates = ["2024-11-20", "2024-11-21"]
countries = ["US", "CA"]
process_partition.expand(date=dates, country=countries)expand() for Mapping: Use the expand() function to iterate over lists or dictionaries, generating multiple task instances dynamically.partial() for Constants: Pass constant parameters to your mapped tasks using partial(), avoiding code duplication and improving readability.parallelism, DAG concurrency, task max_active_tis_per_dag, and Pools allow fine-grained control over concurrent execution.With the DAG proliferation nightmare and Dynamic Task Mapping in mind, let’s see how to apply this in a real-world scenario combined with some other modern Airflow features.
This example demonstrates how modern Airflow features, especially Dynamic Task Mapping, address the Reddit user’s question: “How to Leverage Data Partitions for Parallelizing ETL Workflows in Airflow?” Our goal? A single, efficient DAG that handles both daily operations and custom date range reloads.
Tech stack:
We’ll use DuckDB to write partitioned Parquet files, simulating a typical data partitioning scenario. The data is partitioned by day. Our DAG will implement two modes:
In addition to Dynamic Task Mapping, the example showcases these modern Airflow features:
You can quickly set up a local Airflow environment using the Astro CLI:
mkdir airflow-dynamic-task-mapping
astro dev init
astro dev start Initialize local environment, source: by author
Initialize local environment, source: by author
 Start local environment, source: by author
Start local environment, source: by author
 Local Airflow UI, source: by author
Local Airflow UI, source: by author
First, we’ll create a parameterized DAG with the following parameters:
mode: Determines whether to process a single day (daily) or a custom range (custom). Defaults to daily.start_date, end_date: Define the date range for custom reloads.events_per_partition: Specifies the number of random data rows generated per partition.from datetime import datetime, timedelta
from typing import List, Any
from airflow.decorators import dag, task
from airflow.models.param import Param
@dag(
schedule=None, # no start_date needed when schedule is set to None
dag_display_name='🚀 Dynamic Task Mapping Demo 💚',
params={
'mode': Param(
default='daily',
enum=['daily', 'custom'],
description='Execution mode'
),
'start_date': Param(
default='2024-01-01',
format='date',
description='Start date for the date range (only for custom)'
),
'end_date': Param(
default='2024-01-03',
format='date',
description='End date for the date range (only for custom)'
),
'events_per_partition': Param(
default=10,
type='integer',
description='Random events per partition'
)
}
)
def dynamic_task_mapping_demo():
pass
dynamic_task_mapping_demo()With this, we already learn about three modern Airflow features:
schedule is set to None, the start_date for a DAG is not required.dag_display_name attribute, we can set a custom name which is displayed in the Airflow UI instead of the DAG ID (supports emojis 😉).params we can define DAG parameters, which are nicely rendered in the Airflow UI when triggering a DAG.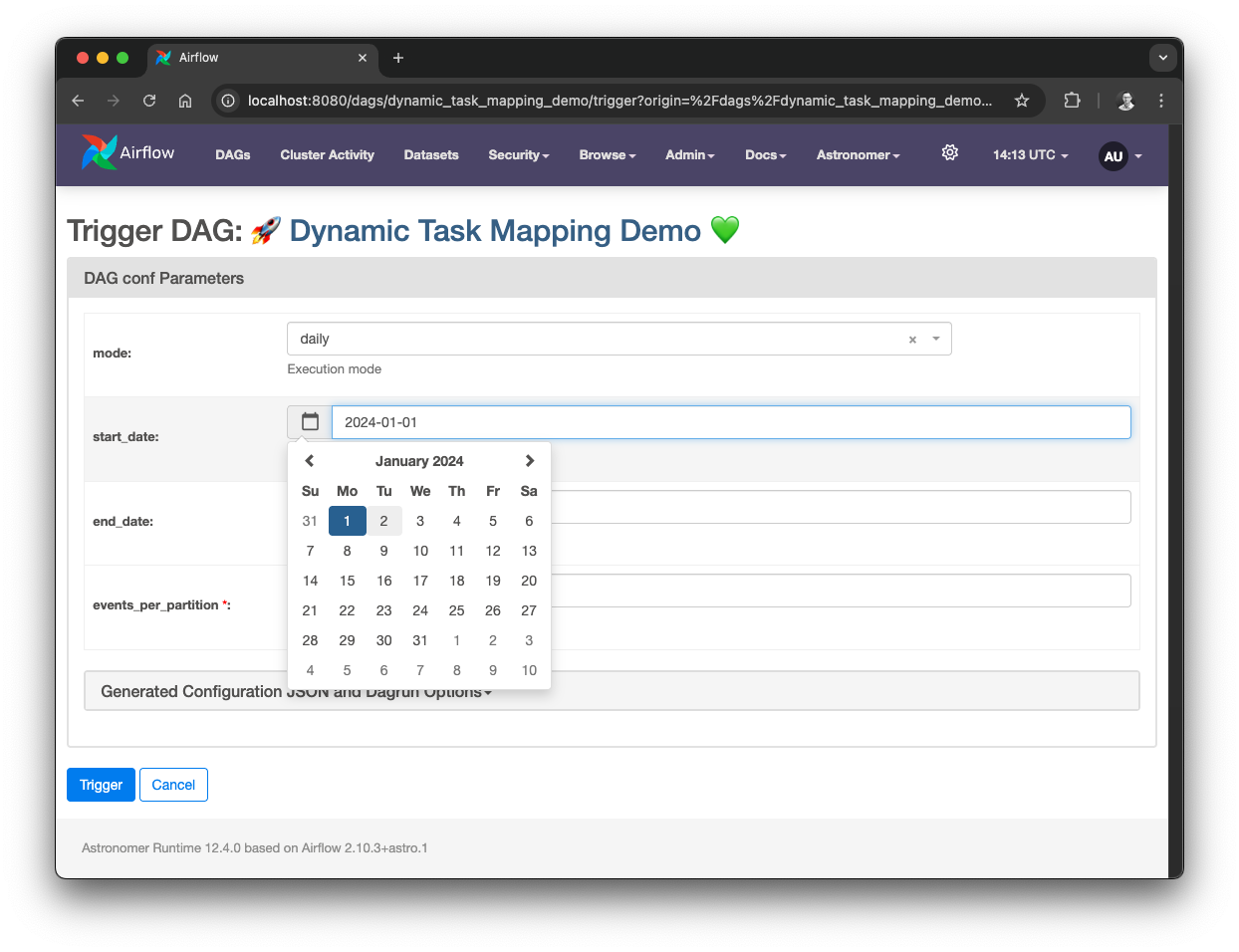 Parameterized DAG, source: by author
Parameterized DAG, source: by author
For this scenario, we’ll use an upstream task to generate the list of partitions based on the given start and end date.
@task(task_display_name='📆 Generate Dates')
def get_date_range(
start_date: str,
end_date: str,
params: dict[str, Any],
ds: str
) -> List[str]:
"""
You can access Airflow context variables by adding them as keyword arguments,
like params and ds
"""
if params['mode'] == 'daily':
return [ds]
start = datetime.strptime(start_date, '%Y-%m-%d')
end = datetime.strptime(end_date, '%Y-%m-%d')
return [
(start + timedelta(days=i)).strftime('%Y-%m-%d')
for i in range((end - start).days + 1)
]This task highlights two more modern features:
task_display_name attribute, we can set a custom name which is displayed in the Airflow UI instead of the Task ID (again: supports emojis 😱).params or ds. Airflow will automagically inject these. See Airflow template references for variables that can be injected.For writing data to partitions, we’ll use DuckDB since it allows to write partitioned Parquet files. The task generates random data for each partition, controlled by the events_per_partition parameter.
To showcase another modern Airflow feature, we’ll use a decorated task and let it run in a Python virtual environment. This allows to encapsulate additional dependencies, just like DuckDB, and keep the Airflow environment itself clean.
@task.virtualenv(
task_display_name='🔥 Process Partitions',
requirements=['duckdb>=0.9.0'],
python_version='3.12',
map_index_template='{{ "Partition: " ~ task.op_kwargs["date_str"] }}'
)
def process_partition(date_str: str, events_per_partition: int):
import duckdb
# write sample data for this partition
with duckdb.connect(':memory:') as conn:
conn.execute(f"""
COPY (
SELECT
strftime(DATE '{date_str}', '%Y-%m-%d') AS event_date,
(random() * 1000)::INTEGER AS some_value
FROM range({events_per_partition})
) TO 'out' (
FORMAT PARQUET,
PARTITION_BY (event_date),
OVERWRITE_OR_IGNORE
)
""")This example demonstrates:
@task.virtualenv decorator, the task is executed within a customizable Python virtual environment.requirements attribute.python_version.map_index_template can be used to set a custom name for each individual task. This allows us to identify which partition was calculated by which task in the Airflow UI.COPY (...) TO (...) DuckDB allows to write data to output files, supporting partitioned writes and the Parquet file format (among others).Want to learn more about DuckDB? Feel free to read my article Gotta process ‘em all - DuckDB masters your data like a Pokémon trainer.
With the tasks prepared, we can setup the Dynamic Task Mapping in our DAG. The goal is to have a task per partition, each calculating a different date. For this purpose, we’ll use the expand() function. The number of random rows / events per partition remains the same for each task, consequently we’ll use partial() to set this attribute.
dates = get_date_range(
start_date='{{ params.start_date }}',
end_date='{{ params.end_date }}'
)
# partial: same for all task instances
# expand: different for each instance (list of values, one for each instance)
process_partition.partial(
events_per_partition='{{ params.events_per_partition }}'
).expand(
date_str=dates
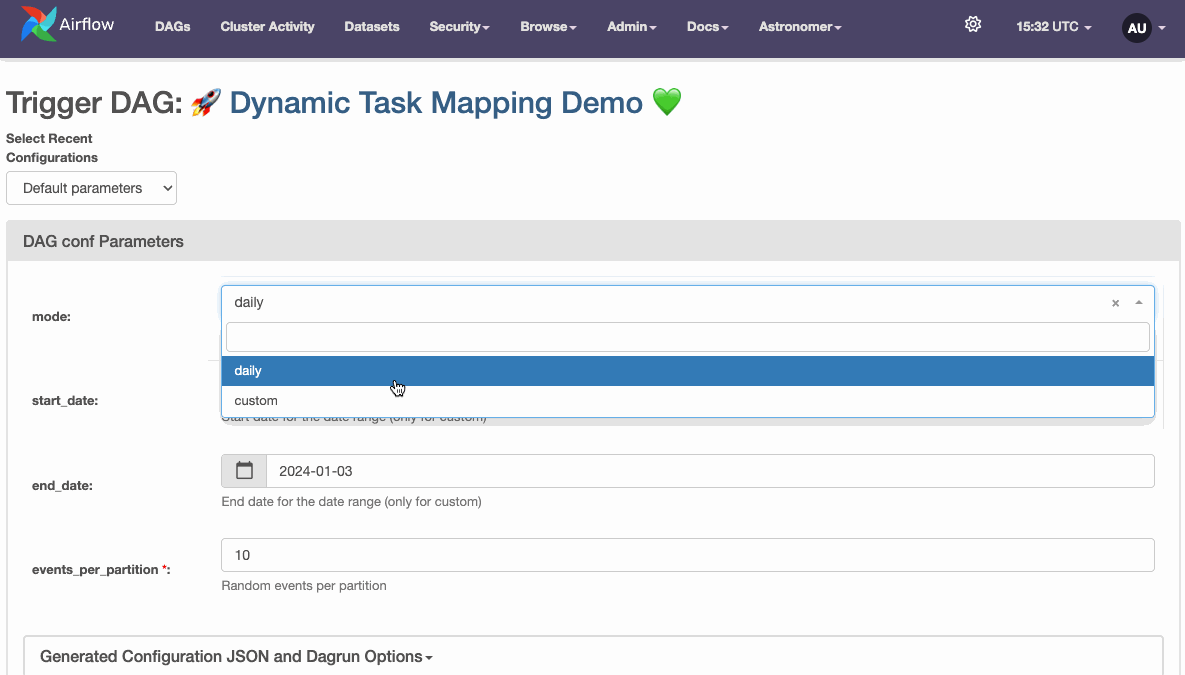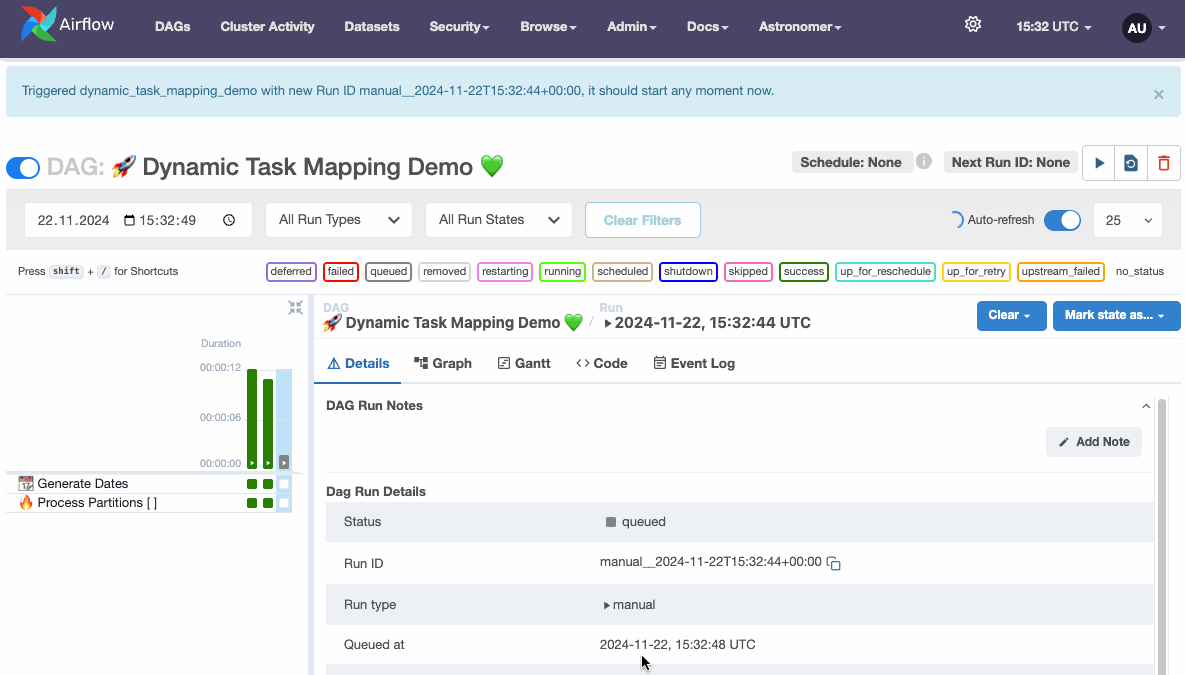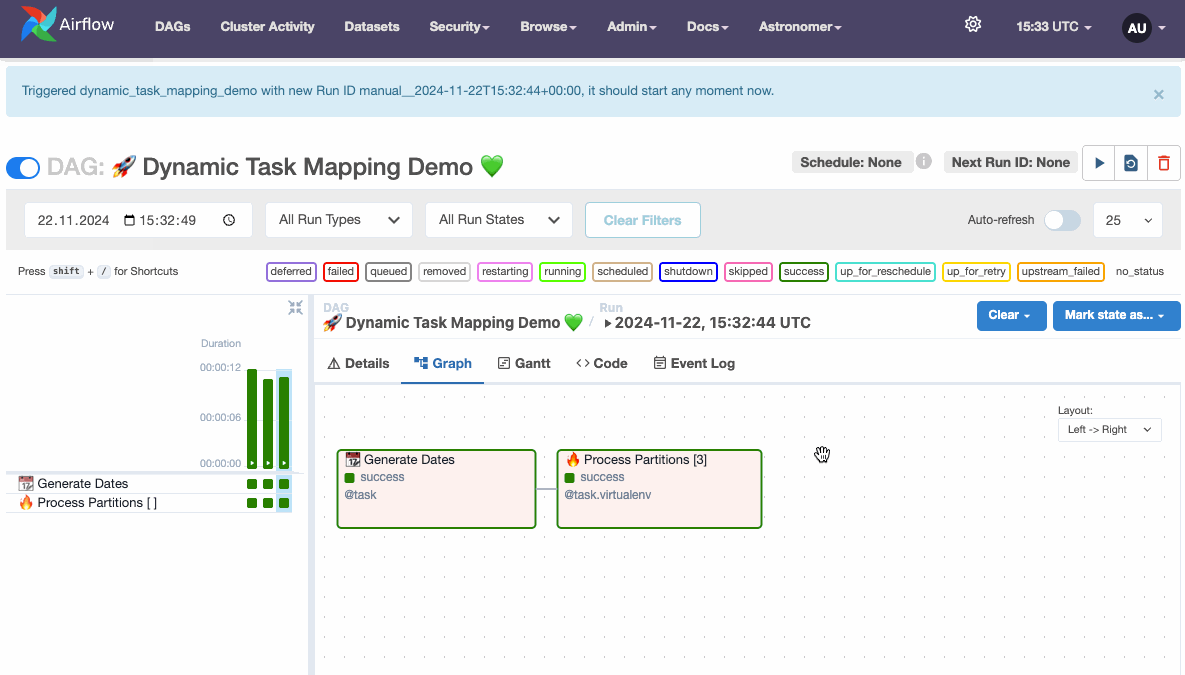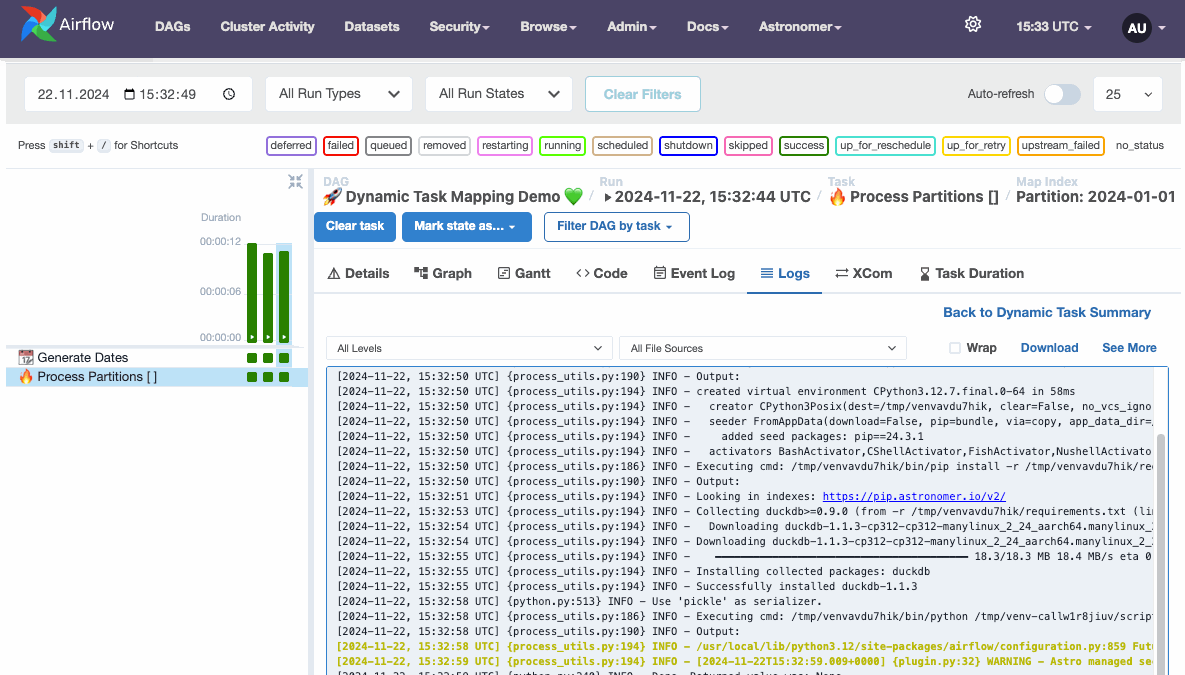
)If we now run the DAG in custom mode with a date range of 3 days for example, we can see the Dynamic Task Mapping in the Airflow UI, showing the number of parallel tasks in square brackets.
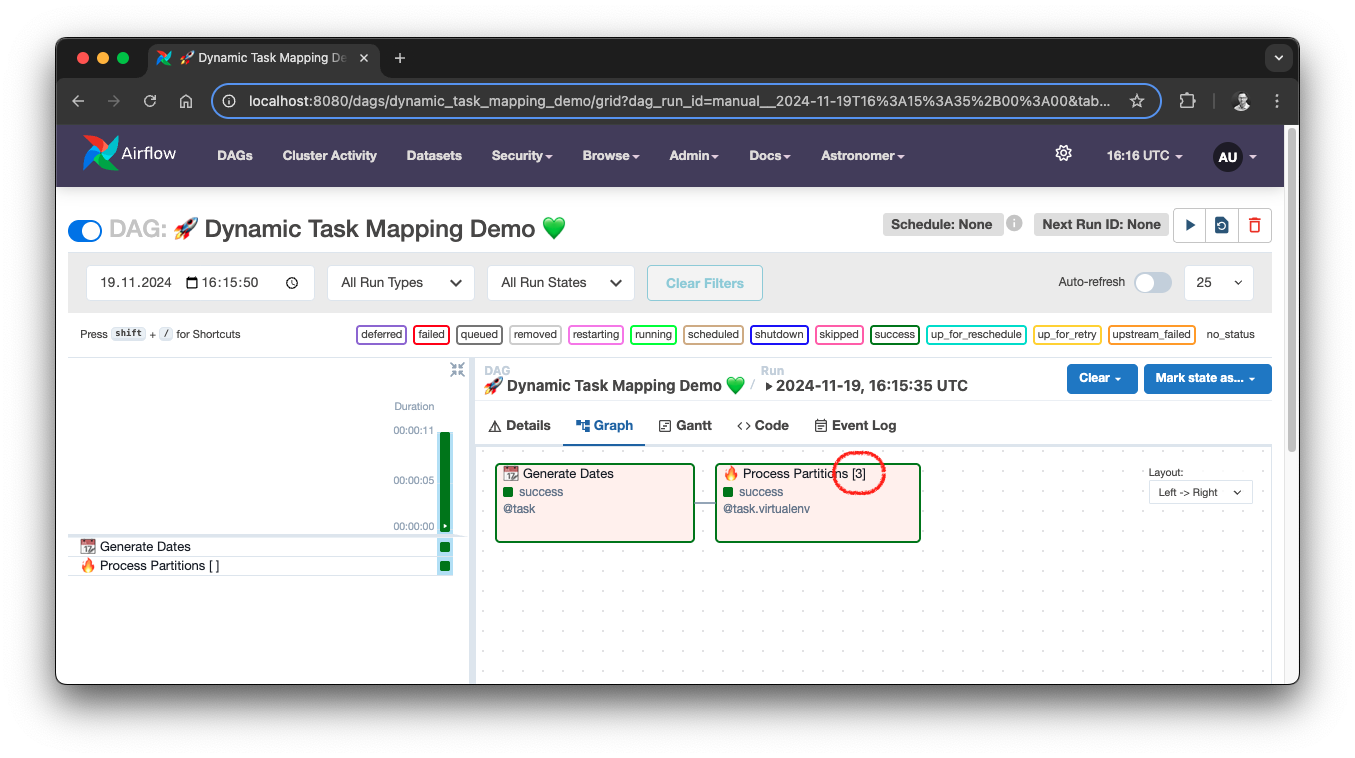 Dynamic Task Mapping demo, source: by author
Dynamic Task Mapping demo, source: by author
By selecting the task and navigating to Mapped Tasks we can see a list of task instances. Since we used a custom map_index_template, we can easily see which task calculated which partition. That way, you can also access the individual logs.
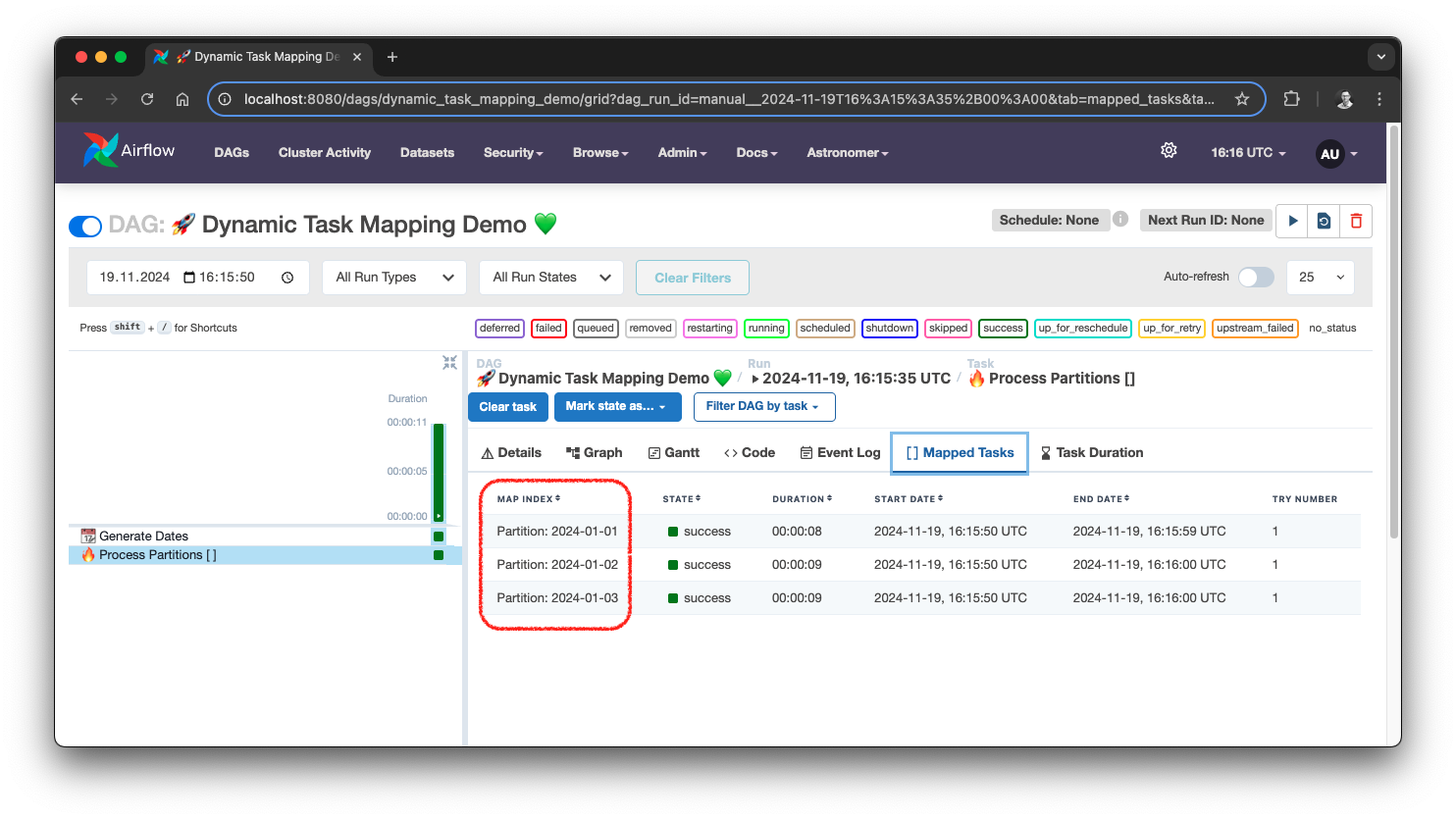 Dynamic Task Mapping task list, source: by author
Dynamic Task Mapping task list, source: by author
Finally, let’s check the output of our DAG run.
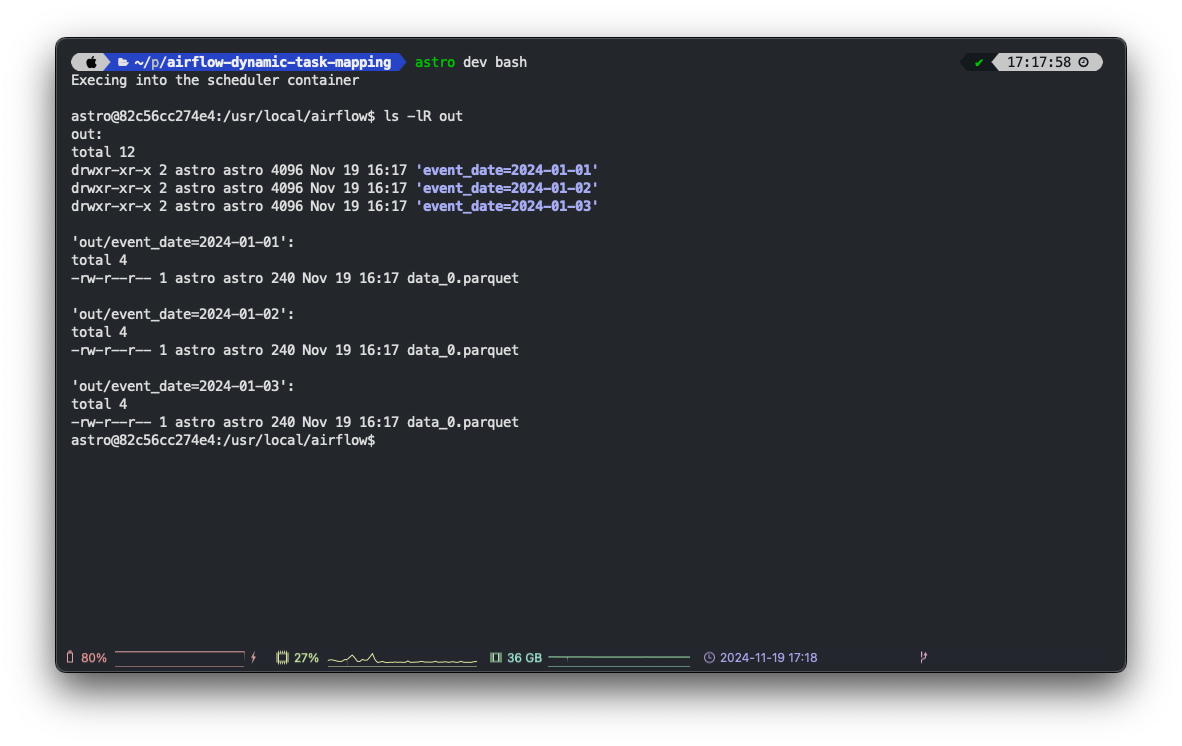 Dynamic Task Mapping output, source: by author
Dynamic Task Mapping output, source: by author
And with that we answered the initial question: “How to Leverage Data Partitions for Parallelizing ETL Workflows in Airflow?” by using Dynamic Task Mapping.
For reference, here is the full DAG:
from datetime import datetime, timedelta
from typing import List, Any
from airflow.decorators import dag, task
from airflow.models.param import Param
@dag(
schedule=None, # no start_date needed when schedule is set to None
dag_display_name='🚀 Dynamic Task Mapping Demo 💚',
params={
'mode': Param(
default='daily',
enum=['daily', 'custom'],
description='Execution mode'
),
'start_date': Param(
default='2024-01-01',
format='date',
description='Start date for the date range (only for custom)'
),
'end_date': Param(
default='2024-01-03',
format='date',
description='End date for the date range (only for custom)'
),
'events_per_partition': Param(
default=10,
type='integer',
description='Random events per partition'
)
}
)
def dynamic_task_mapping_demo():
@task(task_display_name='📆 Generate Dates')
def get_date_range(
start_date: str,
end_date: str,
params: dict[str, Any],
ds: str
) -> List[str]:
"""
You can access Airflow context variables by adding them as keyword arguments,
like params and ds
"""
if params['mode'] == 'daily':
return [ds]
start = datetime.strptime(start_date, '%Y-%m-%d')
end = datetime.strptime(end_date, '%Y-%m-%d')
return [
(start + timedelta(days=i)).strftime('%Y-%m-%d')
for i in range((end - start).days + 1)
]
@task.virtualenv(
task_display_name='🔥 Process Partitions',
requirements=['duckdb>=0.9.0'],
python_version='3.12',
map_index_template='{{ "Partition: " ~ task.op_kwargs["date_str"] }}'
)
def process_partition(date_str: str, events_per_partition: int):
import duckdb
# write sample data for this partition
with duckdb.connect(':memory:') as conn:
conn.execute(f"""
COPY (
SELECT
strftime(DATE '{date_str}', '%Y-%m-%d') AS event_date,
(random() * 1000)::INTEGER AS some_value
FROM range({events_per_partition})
) TO 'out' (
FORMAT PARQUET,
PARTITION_BY (event_date),
OVERWRITE_OR_IGNORE
)
""")
dates = get_date_range(
start_date='{{ params.start_date }}',
end_date='{{ params.end_date }}'
)
# partial: same for all task instances
# expand: different for each instance (list of values, one for each instance)
process_partition.partial(
events_per_partition='{{ params.events_per_partition }}'
).expand(
date_str=dates
)
dynamic_task_mapping_demo()Let’s recap the key takeaways from our journey into Dynamic Task Mapping:
catchup and backfill can be used for processing historical data, but these come with limitations.expand() for mapping and partial() for constants.@task.virtualenv decorator or DAG parameters.Our DuckDB example demonstrates the practical application of these concepts. We built a DAG that not only answers the Reddit user’s question about leveraging partitions but also showcases modern Airflow features.
This isn’t just about writing less code; it’s about writing better code. Dynamic Task Mapping empowers you to:
Ready to break free from the DAG proliferation nightmare? What is your favorite modern Airflow feature?
Learn how to use DuckDB's Vector Similarity Search extension to create a recommendation engine using semantic search and Gemini embeddings
Effective AI implementation relies not only on the quantity of data but also on technical expertise. Let's explore the significance of having a skilled data team for AI projects, learn about the Small Data movement and examine how far we can go with no-code or low-code AI platforms.
Explore how Netflix Maestro and Apache Airflow, two powerful workflow orchestration tools, can complement each other. Delve into their features, strengths, and use cases to uncover whether they are companions or competitors.

{kind=link}