



Airflow 3 and Airflow AI SDK in Action - Analyzing League of Legends
Learn Key Airflow 3 and AI Features Through a Practical League of Legends Data Project
Have you ever dreamt of being a Pokémon trainer, exploring the Kanto region to capture and train incredible creatures? I did for sure, when I first enjoyed the Pokémon Red and Pokémon Blue version on my Game Boy in the 90s.
It is absolutely amazing how popular the Pokémon video game series became over time and still is, like a rising star in the video game industry. Talking about rising stars: DuckDB, an in-process SQL analytics engine, became a rising star in the Data Engineering community in the past years.
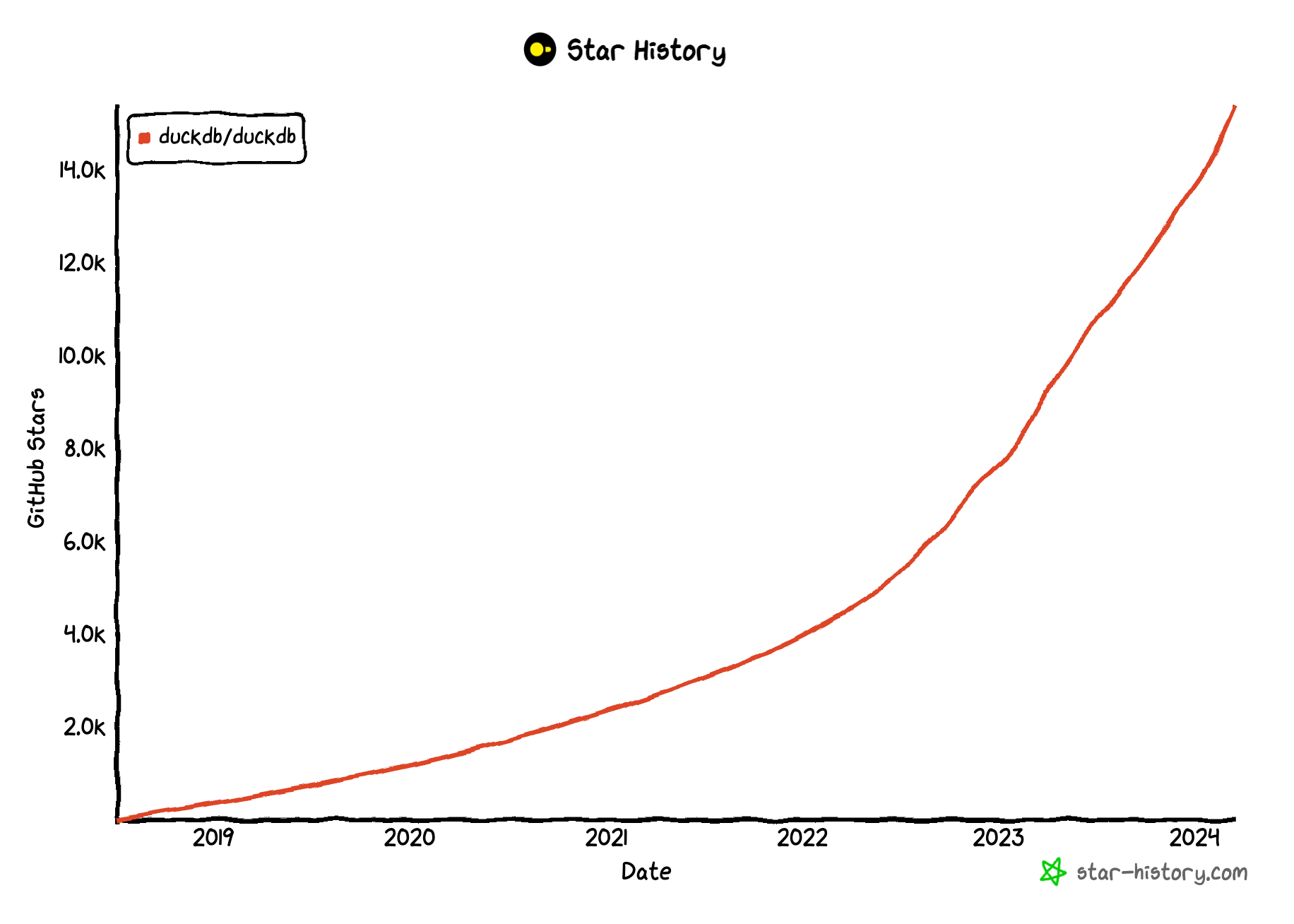 Source: star-history.com
Source: star-history.com
Just as a Pokémon trainer selects the perfect team for battles, an experiences Data Engineer knows the importance of choosing the right tool for the job. With this article, I would like to show you why DuckDB will make a perfect tool in your toolbox.
DuckDB seamlessly integrates with larger databases, facilitating smooth transitions between in-memory and persistent storage solutions. It’s like having a versatile Pokémon that adapts to any challenge thrown its way. Need to analyze a small dataset quickly? DuckDB is your Machoke, ready to tackle the task with ease. Working with a larger dataset that requires more muscle? DuckDB can transform into a Machamp, seamlessly connecting to external databases for heavy-duty analysis.
DuckDB is easy to install, portable and open-source. It is feature rich regarding its SQL dialect and you can import and export data based on different formats like CSV, Parquest and JSON. Also, it integrates seamlessly with Pandas dataframes, which makes it also a powerful data manipulation tool in your data wrangling scripts.
In the following chapters, we will use the Pokémon API to exemplary process data using DuckDB showcasing some powerful features.
 Source: Pokémon API
Source: Pokémon API
The Pokémon API provides a RESTful API interface to JSON data related to the Pokémon video game franchise. Using this API, you can consume information on Pokémon, their moves, abilities, types, and more.
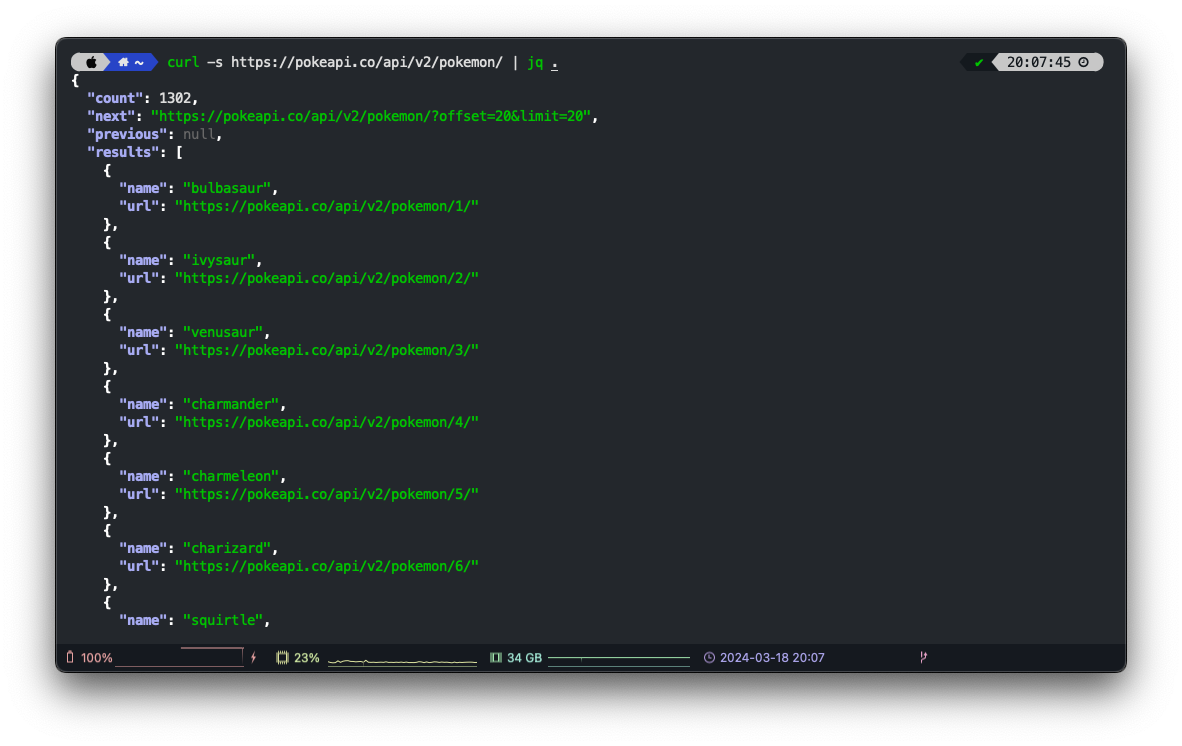
Since this article should primarily focus on DuckDB features, we will only use a subset of endpoints. To get an overview, let’s explore the relevant endpoints using curl and jq. If you are not familiar with jq, it is a lightweight CLI JSON processor with a lot features to filter, modify or simply format JSON in your terminal. jq can be installed via brew install jq if you are using macOS and Homebrew.
curl -s https://pokeapi.co/api/v2/pokemon/ | jq .{
"count": 1302,
"next": "https://pokeapi.co/api/v2/pokemon/?offset=20&limit=20",
"previous": null,
"results": [
{
"name": "bulbasaur",
"url": "https://pokeapi.co/api/v2/pokemon/1/"
},
{
"name": "ivysaur",
"url": "https://pokeapi.co/api/v2/pokemon/2/"
},
...
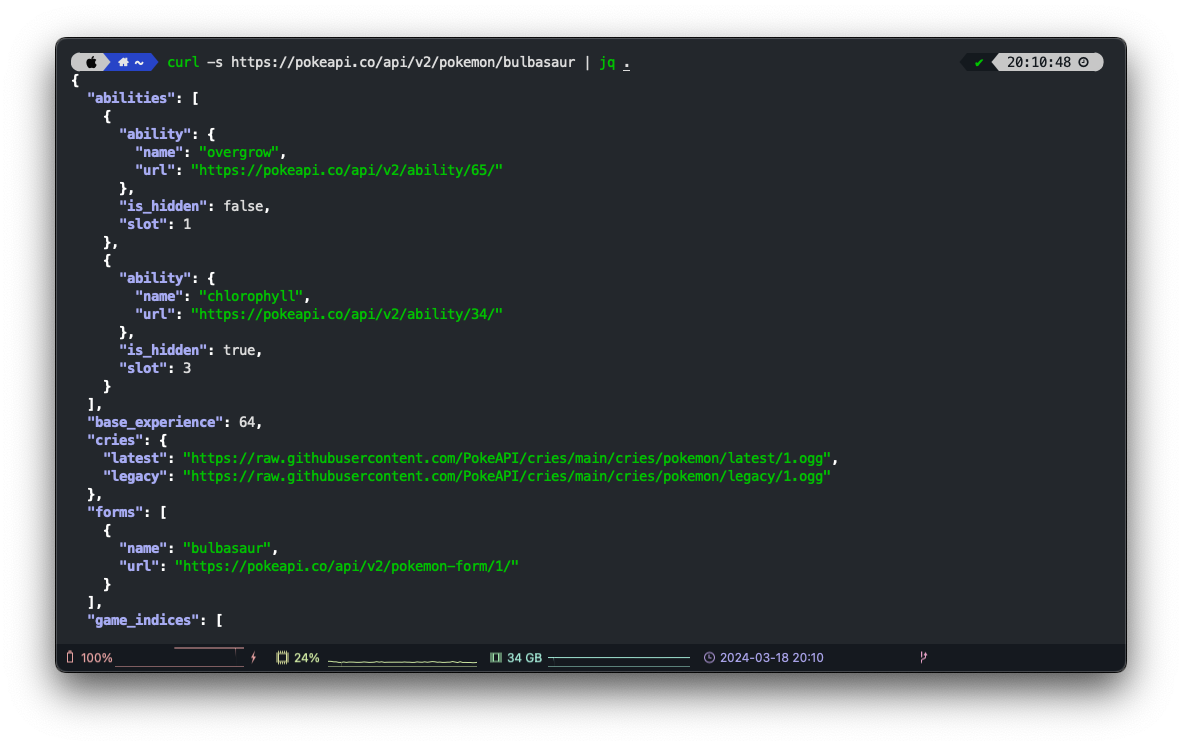
curl -s https://pokeapi.co/api/v2/pokemon/bulbasaur | jq .{
"abilities": [
{
"ability": {
"name": "overgrow",
"url": "https://pokeapi.co/api/v2/ability/65/"
},
"is_hidden": false,
"slot": 1
},
...
],
"base_experience": 64,
...
We start by creating a new Python project. For this, we create a new folder. Within this folder, we create a virtual environment with the the built-in venv module:
mkdir duckdb-pokemon
cd duckdb-pokemon
python -m venv .venv
source .venv/bin/activateWith the last command, we also activated the virtual environment, means: everything you execute in that terminal session will use the virtual Python rather than your system wide Python. This is crucial, as we want to keep the dependencies we will install next isolated within the project. The next step is to install all requirements:
pip install duckdb
pip install pandas
pip install requestsFrom here we are ready to go. In the next chapters, we will look at some of the DuckDB features utilizing the Pokémon API. You can simply copy the code into a Python file in your project and execute it there.
The first demo shows how simple it is to get started. After installing DuckDB with pip install duckdb you can directly import it and run SQL statements. No complicated database setup or other requirements. Like advertised, this is your fast in-process analytical database.
import duckdb
duckdb.sql("SELECT 42").show()Running this code, we get the expected output, a table with one column and one row containg the value 42, the answer to the ultimate question of life, the universe, and everything.
┌───────┐
│ 42 │
│ int32 │
├───────┤
│ 42 │
└───────┘Things will escalate quickly now, so ensure you have your Pokéball ready. Usually when fetching JSON data from an API, we would start with requests.get implementing some client logic to finally load the data to a database or use another framework for data wrangling like Pandas. The next example will for sure surprise you with its pragmatism, we will use SQL to fetch the data and make it directly available as a table in SQL.
import duckdb
duckdb.sql("""
CREATE TABLE pokemon AS
SELECT *
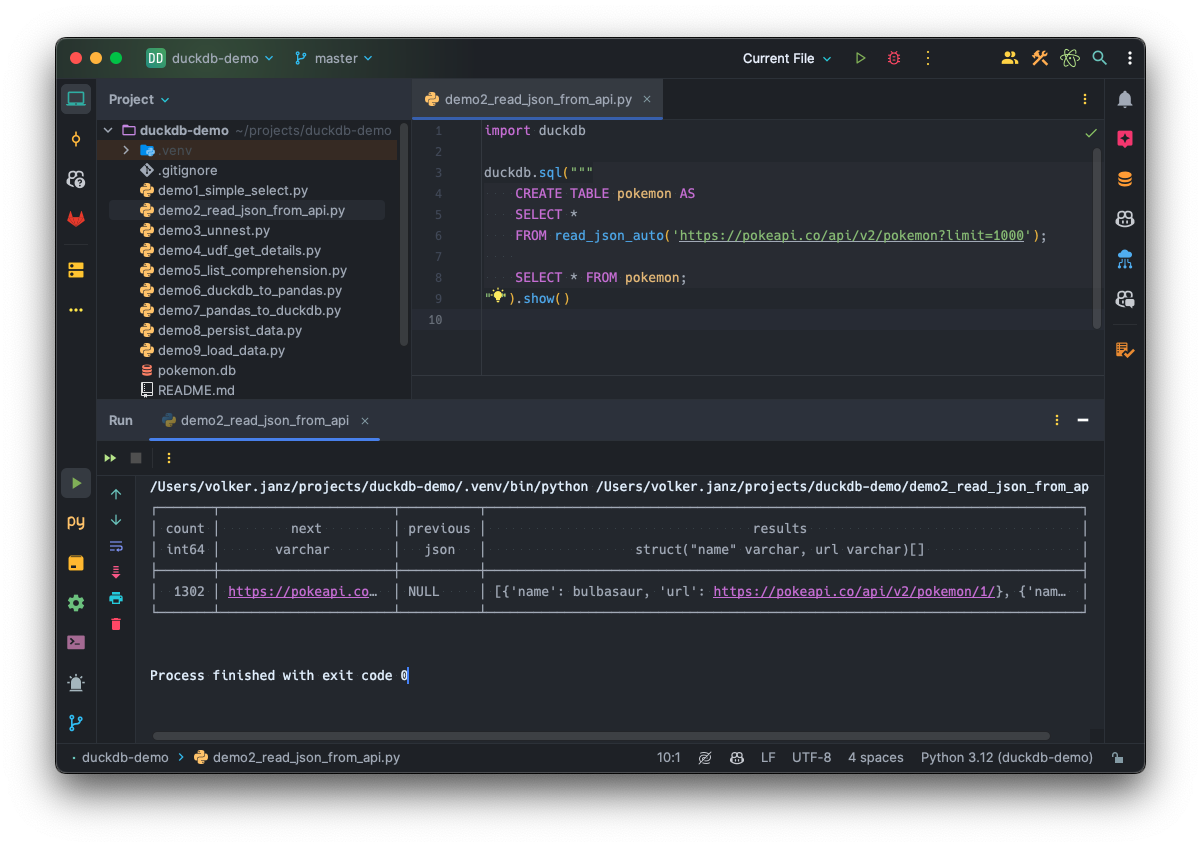
FROM read_json_auto('https://pokeapi.co/api/v2/pokemon?limit=1000');
SELECT * FROM pokemon;
""").show()With read_json_auto we use the simplest method of loading JSON data. It automatically configures the JSON reader and derives the column types from the data.
The code above gives us a table with four columns, according to the respective response from the API, namely: count, next, previous and results, whereas results is a list of structs and each struct is a Pokémon with its name and URL to fetch further details.
Flexibility is where DuckDB truly shines. DuckDB is your zippy Pikachu - and loading JSON data is just one example. You can also read data from CSV files or even Parquet files with Hive partitioning:
SELECT *
FROM read_parquet("some_table/*/*/*.parquet", hive_partitioning = true);Or directly read data from a Pandas dataframe:
import pandas as pd
import duckdb
df = pd.DataFrame({"some_values" : [42, 7411, 4]})
print(duckdb.query("SELECT SUM(some_values) FROM df").to_df())But let’s stick with Pokémon for now.
With the previous example, the results, so the actual Pokémon, are all within one row and column in form of a list of structs. However, we want to have a row per Pokémon for furhter processing. We can use the unnest function for this purpose.
import duckdb
duckdb.sql("""
CREATE TABLE pokemon AS
SELECT unnest(results) AS pokemon
FROM read_json_auto('https://pokeapi.co/api/v2/pokemon?limit=1000');
SELECT
pokemon.name,
pokemon.url
FROM pokemon;
""").show()Which gives us one row per Pokémon with its name and URL to fetch further details.
┌──────────────┬─────────────────────────────────────────┐
│ name │ url │
│ varchar │ varchar │
├──────────────┼─────────────────────────────────────────┤
│ bulbasaur │ https://pokeapi.co/api/v2/pokemon/1/ │
│ ivysaur │ https://pokeapi.co/api/v2/pokemon/2/ │
│ venusaur │ https://pokeapi.co/api/v2/pokemon/3/ │
│ · │ · │
│ · │ · │
│ baxcalibur │ https://pokeapi.co/api/v2/pokemon/998/ │
│ gimmighoul │ https://pokeapi.co/api/v2/pokemon/999/ │
│ gholdengo │ https://pokeapi.co/api/v2/pokemon/1000/ │
├──────────────┴─────────────────────────────────────────┤
│ 1000 rows (20 shown) 2 columns │
└────────────────────────────────────────────────────────┘Can we level up our Pikachu so that it evolves into Raichu? Sure thing! With the result from the previous example, we now have a column called url that holds a URL for each Pokémon which we have to request in order to get more details. Functions like read_json_auto are table level functions, so we can’t apply them to each row unfortunately.
DuckDB integrates seamlessly into Python, which means, there is a way to simply call a Python function for each of our url values in the column. This is similar to User Defined Functions (UDFs) that you might now from other database systems.
In order to fetch the data from the API, we define a Python function:
import requests
def get(url):
return requests.get(url).textAnd then register it with DuckDB:
from duckdb.typing import VARCHAR
duckdb.create_function("get", get, [VARCHAR], VARCHAR)When using create_function we need to give the UDF a name to reference it in our SQL script. Also, we need to pass the actual Python function to be called together with a list of parameter types and the return type.
We can then use it in SQL:
json(get(pokemon.url)) AS detailsIn other words: we call the Python function get for each pokemon.url form our unnested list of Pokémon. What we get is the JSON response as text and we parse that with the json function to get a properly typed result.
This is the final code to try yourself:
import duckdb
import requests
from duckdb.typing import VARCHAR
def get(url):
return requests.get(url).text
duckdb.create_function("get", get, [VARCHAR], VARCHAR)
duckdb.sql("""
CREATE TABLE pokemon AS
SELECT unnest(results) AS pokemon
FROM read_json_auto('https://pokeapi.co/api/v2/pokemon?limit=10');
WITH base AS (
SELECT
pokemon.name AS name,
json(get(pokemon.url)) AS details
FROM pokemon
)
SELECT *
FROM base;
""").show()The execution might take a few seconds as we call the API for each of the Pokémon. The result is a table with the name and all details as JSON.
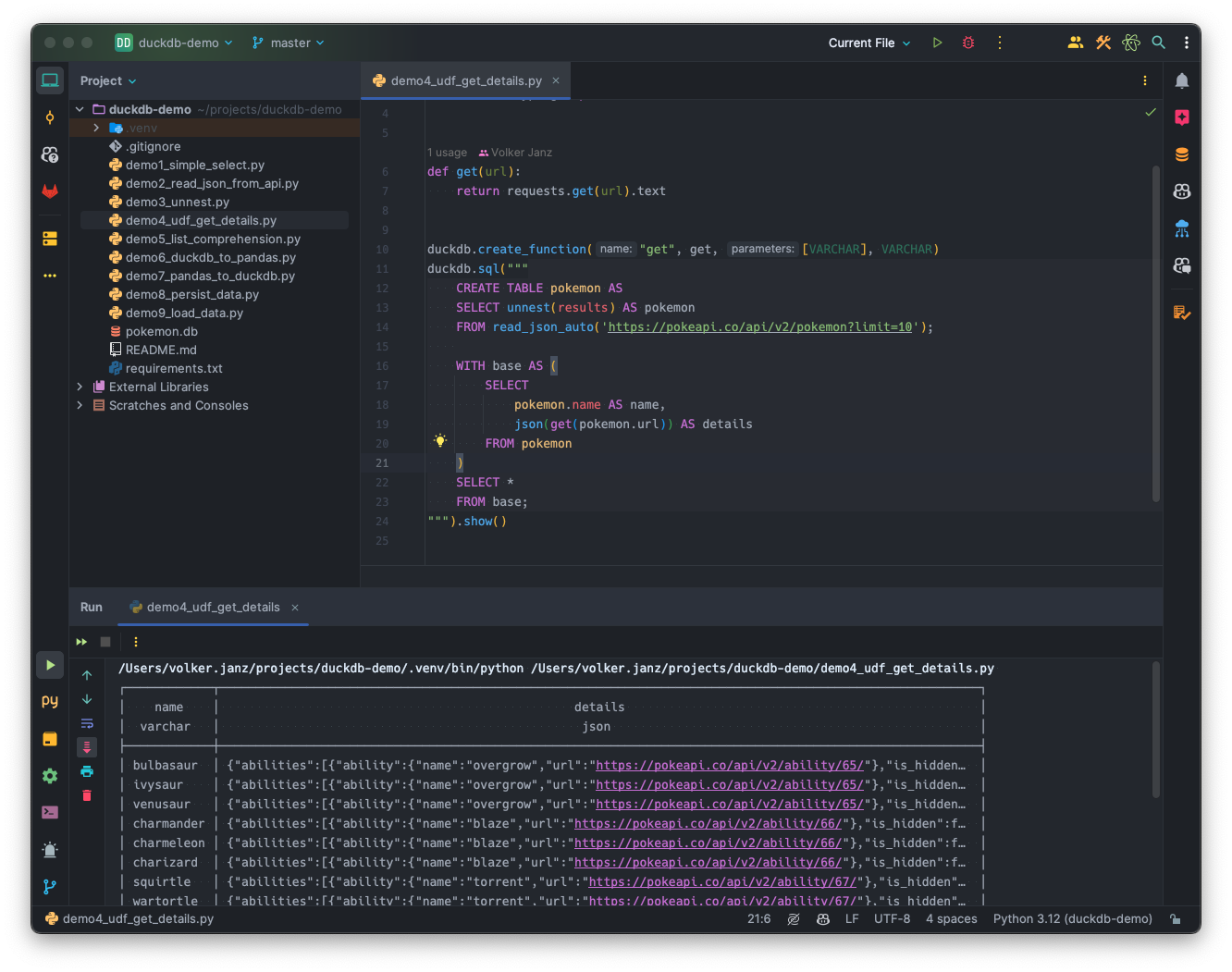
List comprehension in Python is one of my favourite features. You can also use list comprehension in DuckDB! Our goal is to further process the details, by extracting them into individual columns. But not all details, just the ID, the name, the height and the weight of the Pokémon.
We also want to reduce the abilities to a simple list with the ability names that the Pokémon can use in another column.
To make the SQL more readable, we will also use common table expressions (CTEs).
import duckdb
import requests
from duckdb.typing import VARCHAR
def get(url):
return requests.get(url).text
duckdb.create_function("get", get, [VARCHAR], VARCHAR)
duckdb.sql("""
CREATE TABLE pokemon AS
SELECT unnest(results) AS pokemon
FROM read_json_auto('https://pokeapi.co/api/v2/pokemon?limit=10');
WITH base AS (
SELECT
pokemon.name AS name,
json(get(pokemon.url)) AS details
FROM pokemon
), pokemon_details AS (
SELECT
details.id,
name,
details.abilities::STRUCT(ability STRUCT(name VARCHAR, url VARCHAR), is_hidden BOOLEAN, slot INTEGER)[] AS abilities,
details.height,
details.weight
FROM base
)
SELECT
id,
name,
[x.ability.name FOR x IN abilities] AS abilities,
height,
weight
FROM pokemon_details;
""").show()As you can see, the CTE pokemon_details extracts the reuqired details. But there is one more hidden feature in it: So far, abilities as part of the details column is of type JSON but list comprehension requires to have an actual list type. With the following statement:
details.abilities::STRUCT(ability STRUCT(name VARCHAR, url VARCHAR), is_hidden BOOLEAN, slot INTEGER)[] AS abilities,we essentially convert the type of abilities to a list of structs. And each struct contains another struct with the ability name and url for more details, as well as the is_hidden flag and the slot number.
Now that abilities is a list, we can apply list comprehension in SQL. This basically works the same as list comprehension in Python, so with the following SQL code:
[x.ability.name FOR x IN abilities] AS abilities,we create a new list containing only the name of each ability that the Pokémon can use.
┌──────┬────────────┬─────────────────────────┬────────┬────────┐
│ id │ name │ abilities │ height │ weight │
│ json │ varchar │ varchar[] │ json │ json │
├──────┼────────────┼─────────────────────────┼────────┼────────┤
│ 1 │ bulbasaur │ [overgrow, chlorophyll] │ 7 │ 69 │
│ 2 │ ivysaur │ [overgrow, chlorophyll] │ 10 │ 130 │
│ 3 │ venusaur │ [overgrow, chlorophyll] │ 20 │ 1000 │
│ 4 │ charmander │ [blaze, solar-power] │ 6 │ 85 │
│ 5 │ charmeleon │ [blaze, solar-power] │ 11 │ 190 │
│ 6 │ charizard │ [blaze, solar-power] │ 17 │ 905 │
│ 7 │ squirtle │ [torrent, rain-dish] │ 5 │ 90 │
│ 8 │ wartortle │ [torrent, rain-dish] │ 10 │ 225 │
│ 9 │ blastoise │ [torrent, rain-dish] │ 16 │ 855 │
│ 10 │ caterpie │ [shield-dust, run-away] │ 3 │ 29 │
├──────┴────────────┴─────────────────────────┴────────┴────────┤
│ 10 rows 5 columns │
└───────────────────────────────────────────────────────────────┘By now it is clear that DuckDB is not only a portable analytical database but a versatile data manipulation tool.
At its core, DuckDB offers a seamless integration between SQL-based operations and other data processing tools like Pandas. This unique feature allows you to effortlessly switch between different technologies within your data processing scripts.
Instead of implementing data wrangling fully in SQL or within your Python script using typical libraries like Pandas or NumPy, you switch between these environments without the need to setup a complex database integration.
With our example so far, let’s assume we would like to perform further processing using Pandas. With DuckDB you can easily export the result of your SQL queries to a dataframe using the .df() function.
It also works the other way around, with DuckDB you can directly query data from a Pandas dataframe!
import duckdb
import requests
from duckdb.typing import VARCHAR
def get(url):
return requests.get(url).text
duckdb.create_function("get", get, [VARCHAR], VARCHAR)
# Start working in DuckDB
df = duckdb.sql("""
CREATE TABLE pokemon AS
SELECT unnest(results) AS pokemon
FROM read_json_auto('https://pokeapi.co/api/v2/pokemon?limit=10');
WITH base AS (
SELECT
pokemon.name AS name,
json(get(pokemon.url)) AS details
FROM pokemon
), pokemon_details AS (
SELECT
details.id,
name,
details.abilities::STRUCT(ability STRUCT(name VARCHAR, url VARCHAR), is_hidden BOOLEAN, slot INTEGER)[] AS abilities,
details.height,
details.weight
FROM base
)
SELECT
id,
name,
[x.ability.name FOR x IN abilities] AS abilities,
height,
weight
FROM pokemon_details;
""").df()
# Continue data wrangling in Pandas
df_agg = df.explode("abilities").groupby("abilities", as_index=False).agg(count=("id", "count"))
# Back to DuckDB
duckdb.sql("""
SELECT abilities AS ability, count
FROM df_agg
ORDER BY count DESC
LIMIT 8;
""").show()The code above produces the following result:
┌─────────────┬───────┐
│ ability │ count │
│ varchar │ int64 │
├─────────────┼───────┤
│ blaze │ 3 │
│ chlorophyll │ 3 │
│ overgrow │ 3 │
│ rain-dish │ 3 │
│ solar-power │ 3 │
│ torrent │ 3 │
│ run-away │ 1 │
│ shield-dust │ 1 │
└─────────────┴───────┘As mentioned before, with .df() we get the SQL result as a Pandas dataframe. We can than apply further transformation like:
df_agg = df.explode("abilities").groupby("abilities", as_index=False).agg(count=("id", "count"))And with the dataframe stored in the df_agg variable, you can just use it in SQL, which surprised me a lot when I saw it the first time.
SELECT abilities AS ability, count
FROM df_agg
ORDER BY count DESC
LIMIT 8;That makes DuckDB a great tool in your data wrangling toolbox, since it does not add any glue code.
Calling the API on every run is not the most efficient solution. Sure, it gives you the opportunity to grab a nice cup of coffee while waiting for results, but DuckDB can also persist data, for example by serializing it into a file on your filesystem.
Let’s extend the example above with the following code:
# Continue data wrangling in Pandas
df_agg = df.explode("abilities").groupby("abilities", as_index=False).agg(count=("id", "count"))
# Persist data
with duckdb.connect(database="pokemon.db") as conn:
conn.sql("""
DROP TABLE IF EXISTS pokemon_abilities;
CREATE TABLE pokemon_abilities AS
SELECT abilities AS ability, count
FROM df_agg
ORDER BY count DESC;
""")We open a connection to a file called pokemon.db and persist the data.
In another script, you can then load the data and access the pre-processed data:
import duckdb
# Load data
with duckdb.connect(database="pokemon.db") as conn:
conn.sql("""
SELECT * FROM pokemon_abilities;
""").show()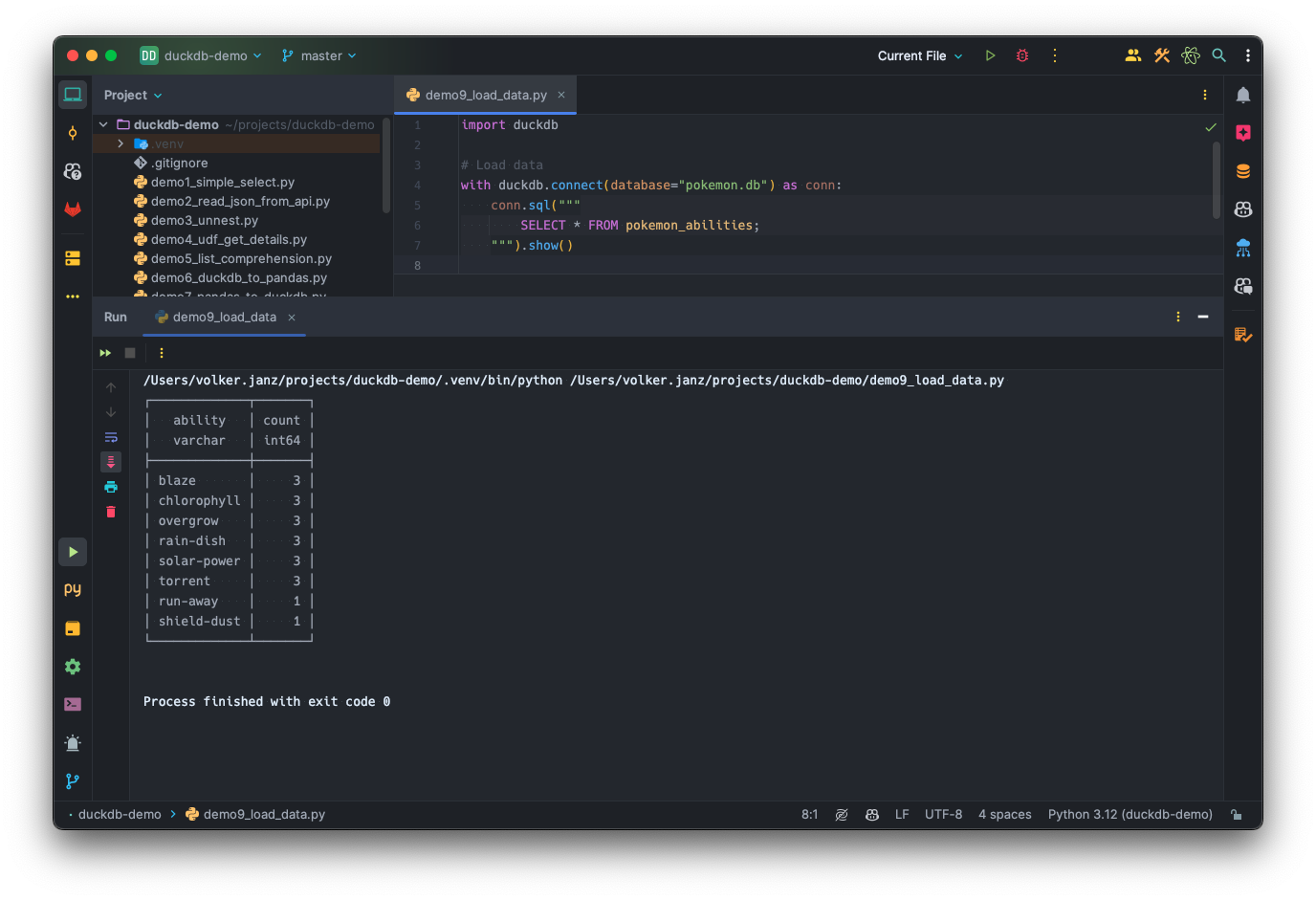
DuckDB emerged as a robust companion in data wrangling challenges, offering seamless integration with Pandas dataframes and advanced analytical SQL capabilities. Its lightweight nature and efficient performance underscored its suitability for analytical workloads in resource-constrained environments.
You can find all demos also on Github 🪄: https://github.com/vojay-dev/duckdb-pokemon
With DuckDB by your side, you’ll become a successful Pokémon trainer in no time.
Because in the world of data, you truly gotta catch ‘em all!
Feel free to share your experiences and enjoy reading!
Learn Key Airflow 3 and AI Features Through a Practical League of Legends Data Project
A personal journey and practical guide from Hamburg to Hollywood
Create an AI agent with PydanticAI to interact with Airflow DAGs


{kind=link}