

The American Dream ETL - A Data Engineer's O-1A Journey
A personal journey and practical guide from Hamburg to Hollywood
The world of data orchestration is evolving at lightning speed. Are your Airflow patterns keeping up, or are they holding you back? In this article, we will cover an end-to-end Airflow 3 data pipeline. We will extract data from the Riot Games API and use the Airflow AI SDK, a modern SDK for working with LLMs from Apache Airflow based on PydanticAI, to generate a League of Legends report featuring a champion tier list. The project highlights modern Airflow 3 and AI features, and
by the end of this article you will be inspired to rethink deprecated DAG orchestration patterns.
 Airflow 3 based League of Legends DAG, source: by author
Airflow 3 based League of Legends DAG, source: by author
Note: I published the final Airflow project on GitHub: https://github.com/vojay-dev/airflow-riot
You are Kha’Zix, an apex predator, crouching unseen within the dense, pulsating shadows of the jungle, senses sharp, every fiber of your being thrumming with anticipation. Your four teammates move with calculated precision across the lanes. The air is thick with the scent of unseen prey—jungle monsters that fuel your growth, champions from the enemy team venturing too close. Your objective: dismantle their defenses, to shatter their Nexus. But with every step, every clash of steel and surge of arcane energy, you are doing more than just fighting for victory. You are generating data—an invisible digital echo of your every action on the battleground. This is the essence of a game called League of Legends.
 League of Legends champions, source: https://www.leagueoflegends.com/en-us/champions
League of Legends champions, source: https://www.leagueoflegends.com/en-us/champions
League of Legends (LoL) is more than a team-based strategy game where two teams of five powerful champions face off to destroy the other’s base; it’s a global cultural phenomenon. With more than 130 million monthly active players, LoL generates a relentless, high-velocity torrent of data. Its impact is so profound that it inspired Arcane, the award-winning animated series by French studio Fortiche, produced under Riot Games’ supervision and successfully distributed by Netflix, captivating audiences worldwide. Each in-game match is a complex interplay of over 140 unique champions, hundreds of items, and countless strategic decisions, all unfolding in real-time. For a Data Engineer, this ecosystem isn’t just player activity; it’s a boundless source of high-dimensional, interconnected information, pulsating with potential insights.
Ekko, the young inventor from Zaun, captures the essence of technological progress in Arcane when he reflects:
Sometimes taking a leap forward means leaving a few things behind
Ekko’s insight mirrors a common struggle in Data Engineering: clinging to familiar methods even as new, more powerful tools emerge. Apache Airflow 3 isn’t just a major update; it’s a direct response to the limitations of older approaches. It demands a conceptual leap, urging us to forget verbose, cumbersome operator patterns that can no longer keep pace with today’s data complexities. We see a more profound emphasis on dataset-driven scheduling, allowing DAGs to react organically to data events rather than being tethered solely to rigid timelines—a clear and powerful step away from some traditional scheduling mindsets. The continued refinement of the TaskFlow API further streamlines Python-native DAG authoring, empowering developers to craft elegant pipelines and inspiring us to leave behind more verbose, older operator patterns for many tasks. This leap forward is about embracing more reactive and data-aware approaches, even if it means rethinking some familiar Airflow concepts to unlock greater efficiency and clarity.
New in Airflow 3: Airflow 3 was released on April 2025. It’s the biggest release since 2.0 (2020) and marks years of evolution, now with 30M+ monthly downloads and 80K+ organizations.
Silently accompanying these flagship advancements are tools like the Airflow AI SDK—a potent, if still somewhat under-the-radar, framework based on PydanticAI. This SDK allows to embed the usage of Large Language Models (LLMs), such as Google’s Gemini, directly within your DAGs, unlocking untapped potential for insight and automation.
To demonstrate this synergy of advanced data orchestration and AI-driven insight, this article provides a comprehensive blueprint for constructing an end-to-end data analysis pipeline. We will learn about the essentials of the Riot Games API to acquire League of Legends data, make use of the power of Dynamic Task Mapping within Airflow—showcasing its modern capabilities—and then deploy the Airflow AI SDK. This will empower Google’s Gemini to distill raw match data into a sophisticated, AI-generated champion performance tier list. We will not only build a functional system but also discover and highlight key advancements introduced in Airflow 3, showcasing how they redefine what’s possible in intelligent data processing. With this article, you will be inspired to leave a few things behind.
For simplicity, we are using a local Airflow environment with Docker and Astro CLI (install via brew install astro), which is an effective way to start Airflow projects.
New in Airflow 3: With the release of Airflow 3, the Astro CLI will start an Airflow 3 environment by default, which makes exploring the new major release easy and convenient.
First, let’s set up the project using the Astro CLI and start the local environment.
brew install astro
mkdir airflow-riot && cd airflow-riot
astro dev init
astro dev start Astro CLI project setup, source: by author
Astro CLI project setup, source: by author
You can now access the UI of your Docker-based Airflow 3 environment at http://localhost:8080. When checking the running container instances, you will see all the basic Airflow components featuring the new Airflow 3 architecture, which introduces a dedicated API server to prevent direct metadata database access from workers.
 The new Airflow 3 UI, source: by author
The new Airflow 3 UI, source: by author
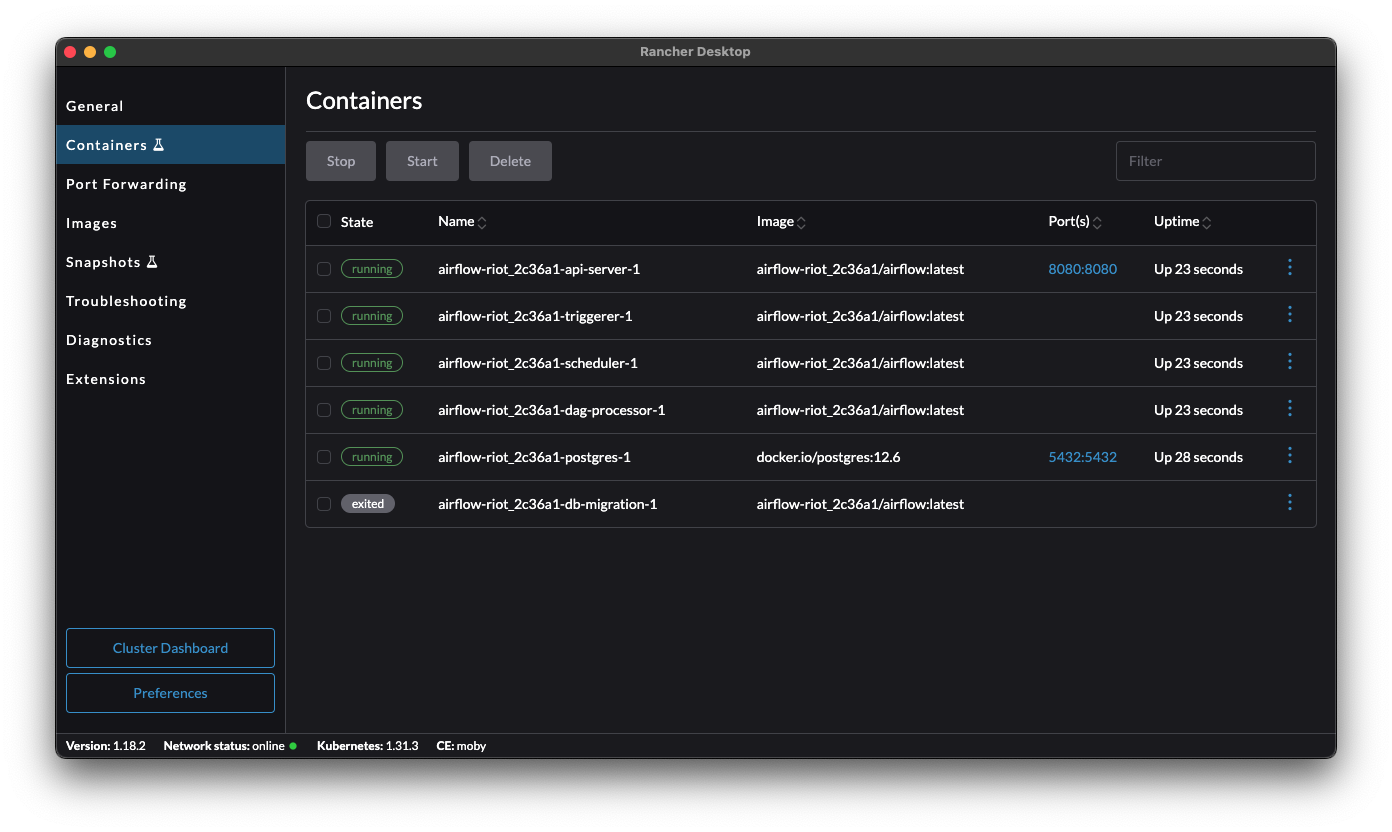 Airflow 3 component containers, source: by author
Airflow 3 component containers, source: by author
Here we can discover one of the most significant and foundational changes in Airflow 3: its new distributed architecture. In previous Airflow versions, major components like workers often had direct access to the metadata database. This created several issues, including security risks, the inability to upgrade components independently, scalability challenges, and a lack of remote task execution.
Airflow 3 fundamentally addresses these issues by decoupling task execution from direct metadata database connections. The centerpiece of this evolution is the introduction of a new API Server. Instead of worker processes writing directly to the Airflow metadata database, tasks (or the processes managing them) now communicate with this API Server to receive instructions and report their statuses (e.g., success, failure, heartbeats). The key benefits and details of this architectural shift include:
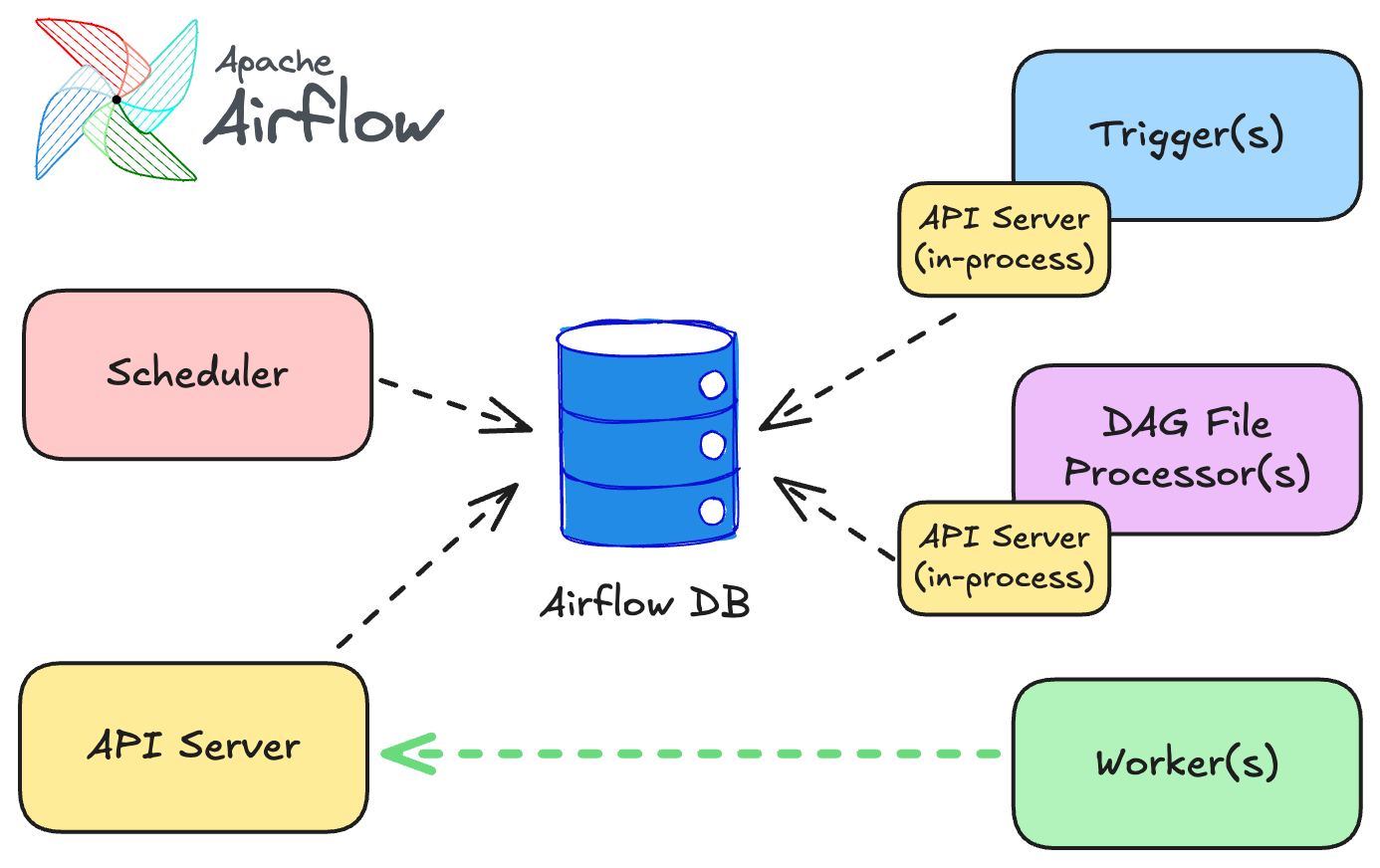 Airflow 3 distributed architecture, source: by author
Airflow 3 distributed architecture, source: by author
In essence, the introduction of the API Server and the move towards a more distributed architecture in Airflow 3 represent a significant modernization, improving security, enabling flexible execution models, and preparing Airflow for the next generation of data orchestration challenges, especially in the AI era.
New in Airflow 3: The new architecture features a distributed model with an API Server, leading to stronger security, remote task execution, and improved operational agility.
The next step is to set up the project in PyCharm. The Docker environment includes a Python setup with all the essential Airflow dependencies pre-installed. Instead of creating another local virtual environment for development, the cleanest solution is to utilize this Docker-based environment. This ensures that we always develop in the same environment as our production system is executed.
After opening the project in PyCharm, access the settings window and navigate to: Project –> Python Interpreter –> Add Interpreter –> On Docker. Make sure the Docker Server is properly configured. The Dockerfile generated by Astro CLI is automatically pre-selected.
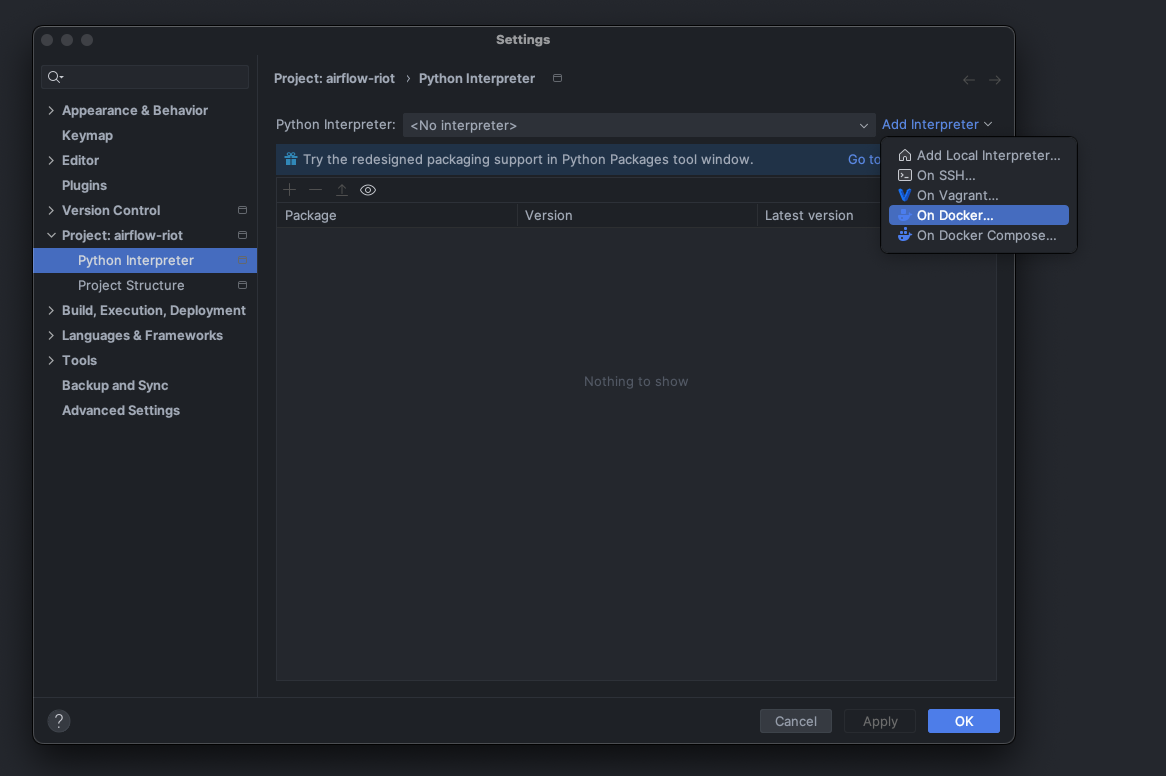 Add Python interpreter on Docker in PyCharm, source: by author
Add Python interpreter on Docker in PyCharm, source: by author
Proceed through the dialogs and select System Interpreter in the final step before clicking Create.
The Python Interpreter window in PyCharm will now display as Remote Python, with all Airflow packages and dependencies listed. You now have a fully functional PyCharm development environment, complete with auto-completion and more, without needing to set up another local virtual environment.
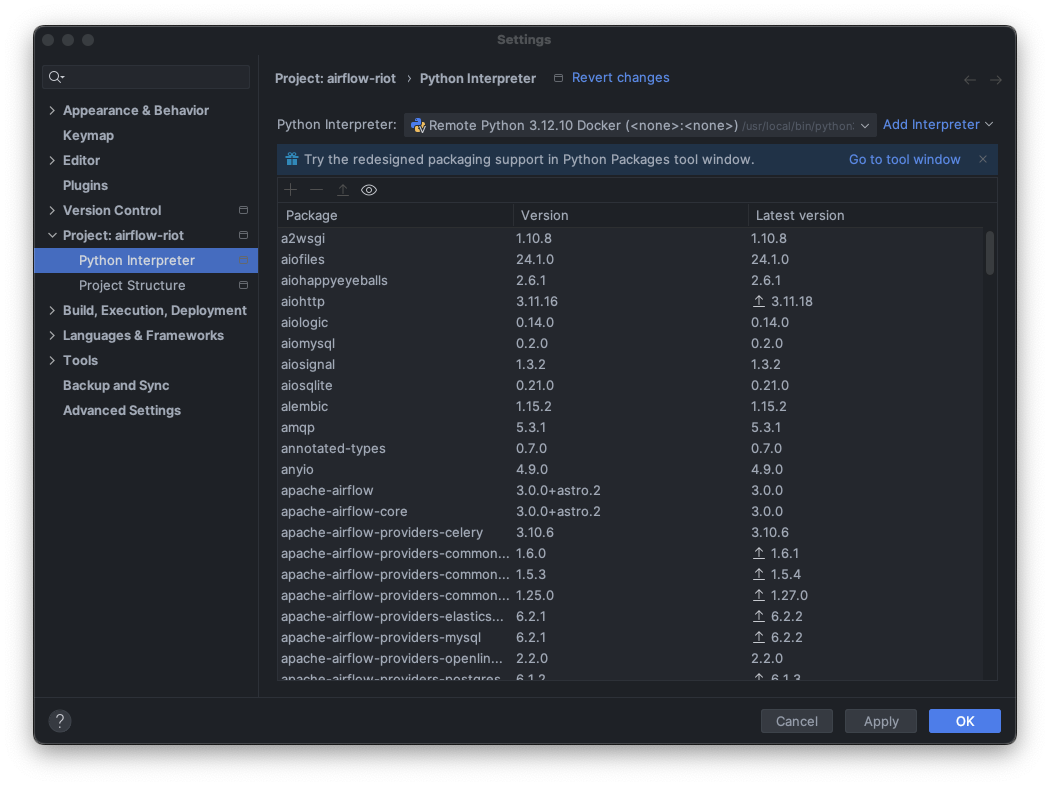 Use Python interpreter from Docker environment in PyCharm, source: by author
Use Python interpreter from Docker environment in PyCharm, source: by author
Note: Personally, I am using Rancher Desktop, an open-source application that provides all the essentials to work with containers and Kubernetes. It is a fully free alternative to Docker Desktop, which works absolutely fine with the setup explained above.
Let’s get started by deleting the example DAG, generated by the Astro CLI in dags/exampledag.py. Then, create your first, minimal DAG as dags/lol.py:
from airflow.sdk import dag, task
@dag(schedule=None)
def lol():
@task
def hello():
print("Hello world")
hello()
lol()Airflow tip: If you set the schedule to None, you don’t need to specify a start date for your DAG. This allows for minimal DAG implementations to get started easily.
Open the Airflow UI in your browser by navigating to http://localhost:8080. Under Dags, you will find the new DAG grid and list, displaying our Hello World DAG named lol.
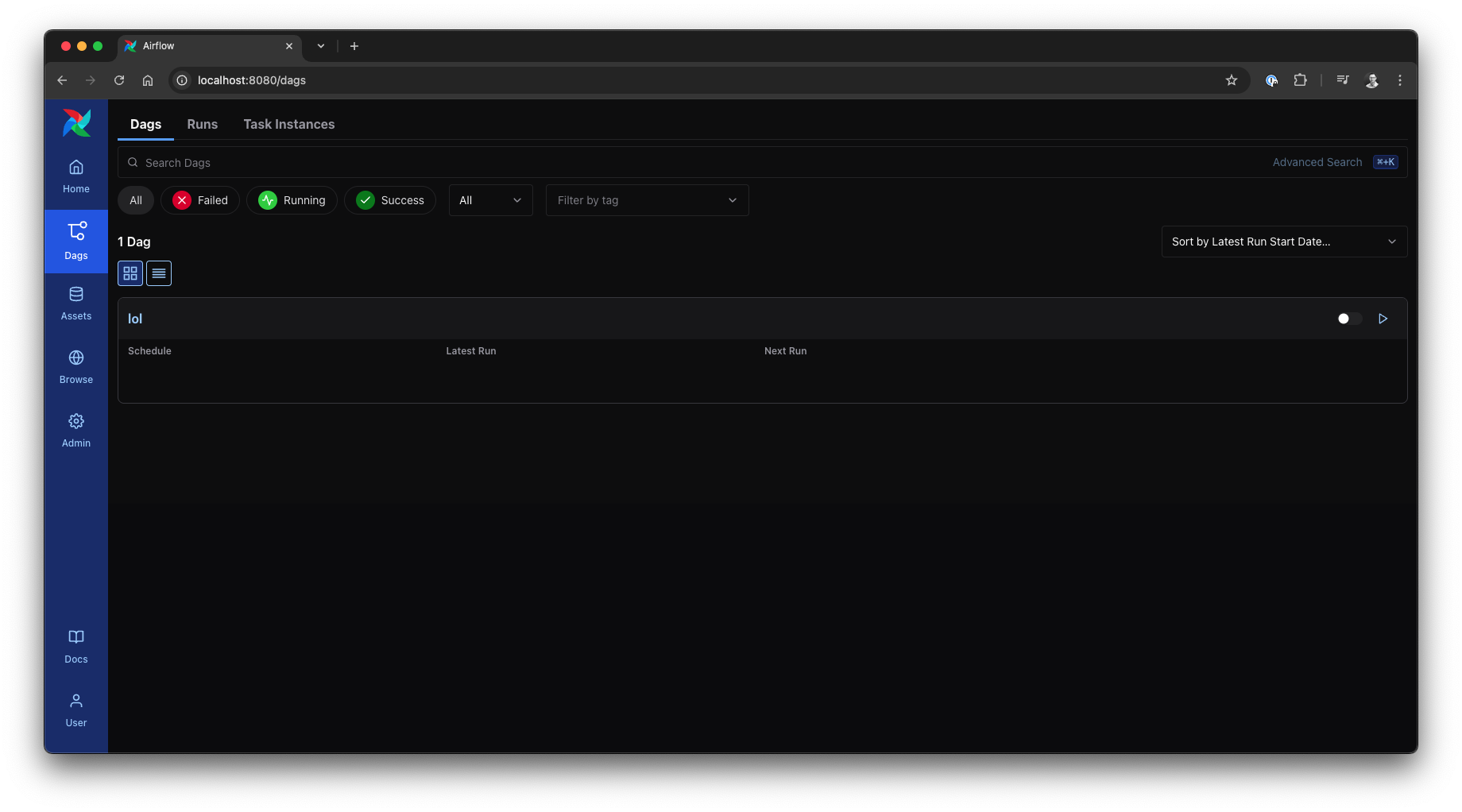 Airflow 3 UI: DAG list, source: by author
Airflow 3 UI: DAG list, source: by author
Clicking on the DAG takes you to the DAG view. On the right side, you will see various details about runs, tasks, events, and the actual implementation. The left side allows you to visualize the individual tasks of the DAG as a grid, which includes all recent runs, or as a graph to illustrate the tasks and their dependencies.
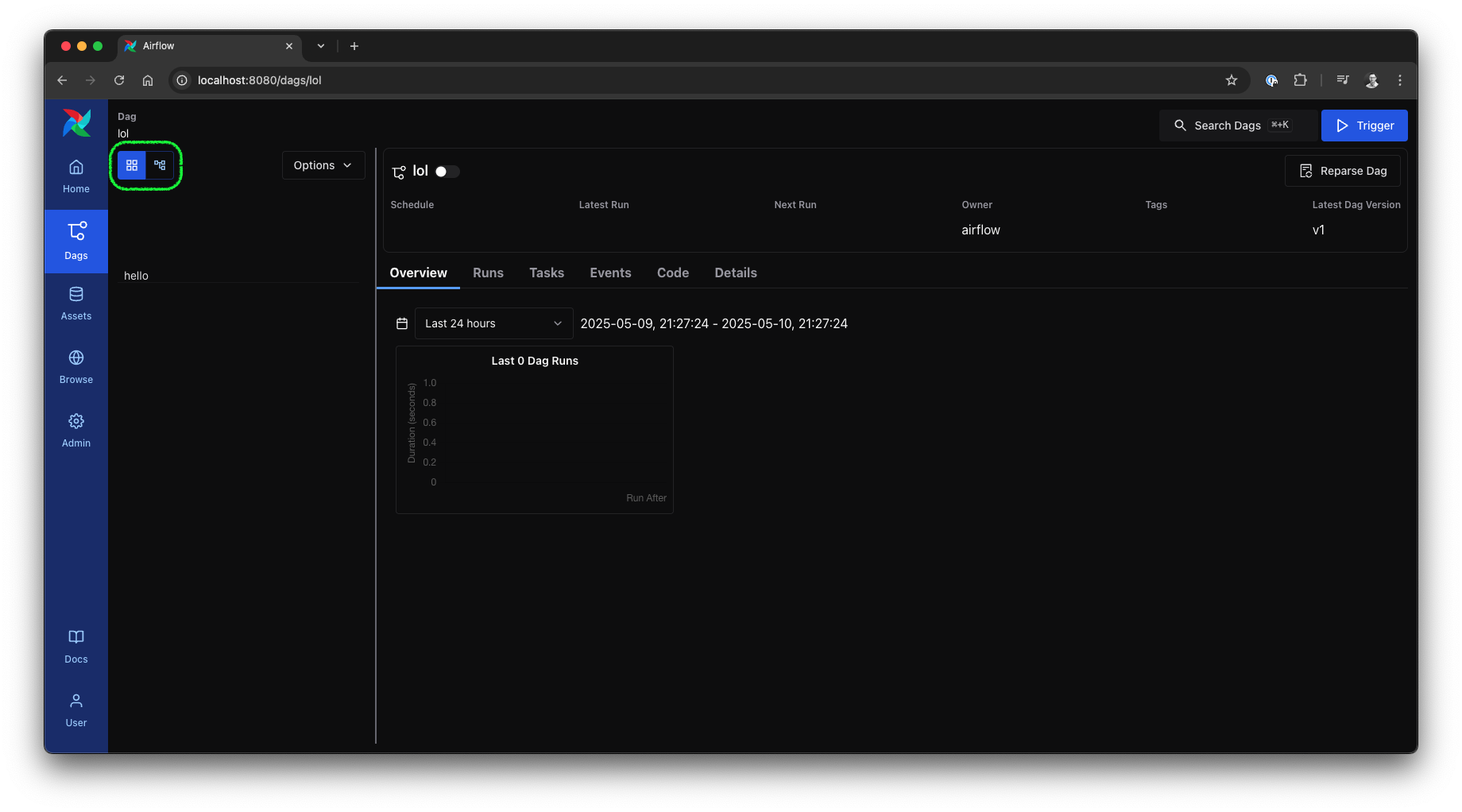 Airflow 3 UI: DAG grid view, source: by author
Airflow 3 UI: DAG grid view, source: by author
In the top right corner of the DAG view, you will find the Reparse Dag button, which is worth noting. It will reparse the DAG source file, allowing you to see changes immediately. Below the button, you will notice a glimpse of the new DAG Versioning feature, showing the DAG Version, which increments with each change.
 Airflow 3 UI: DAG graph view, source: by author
Airflow 3 UI: DAG graph view, source: by author
Clicking on Runs in the DAG view takes you to the DAG runs view, where you can see each run of the DAG along with its type, effective dates, DAG Version, and options to rerun or mark it as a failure or success. By clicking on a run date, you will enter the run view.
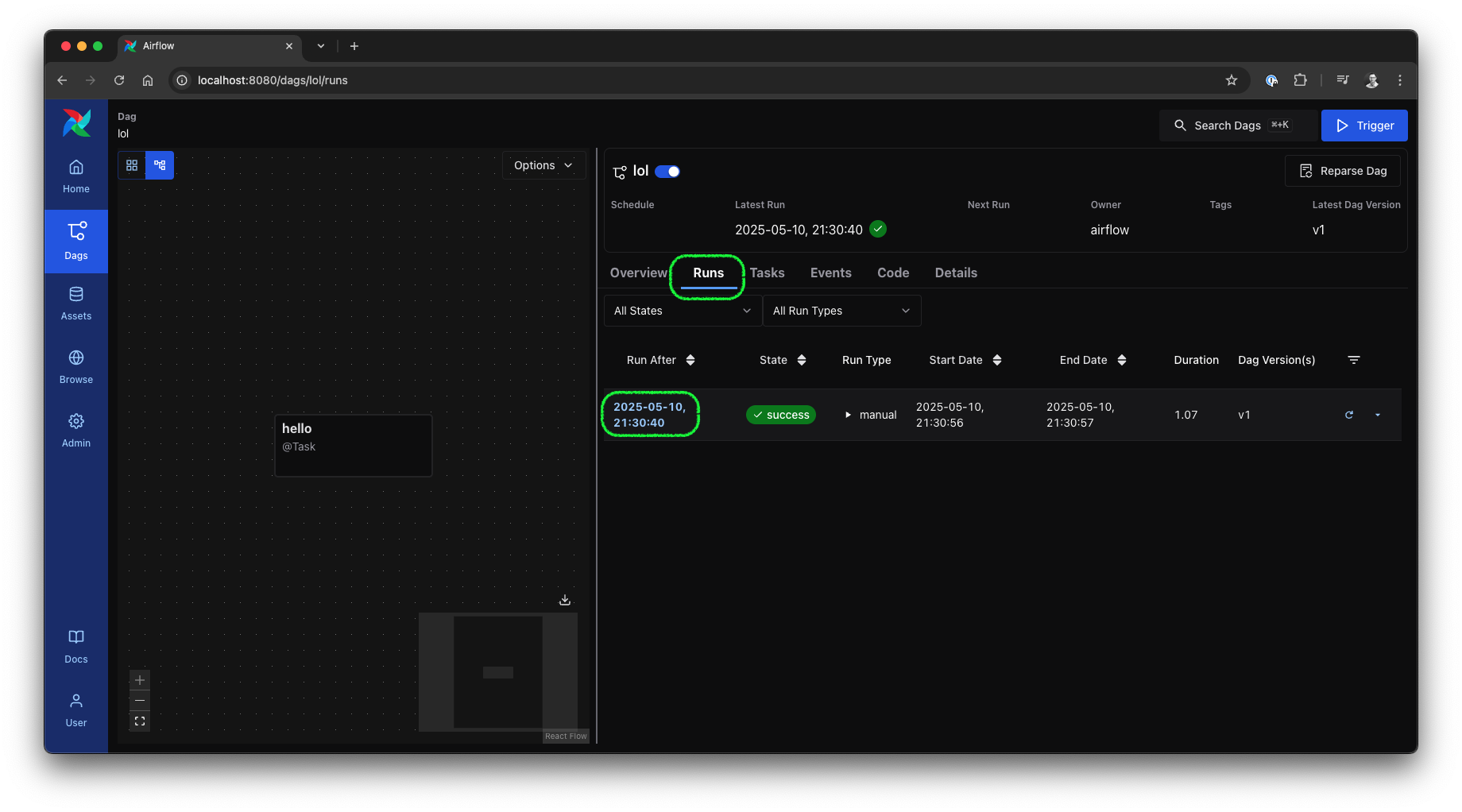 Airflow 3 UI: DAG run view, source: by author
Airflow 3 UI: DAG run view, source: by author
In the run view, you will find a clear overview of all relevant details for this run and the instances of the tasks involved.
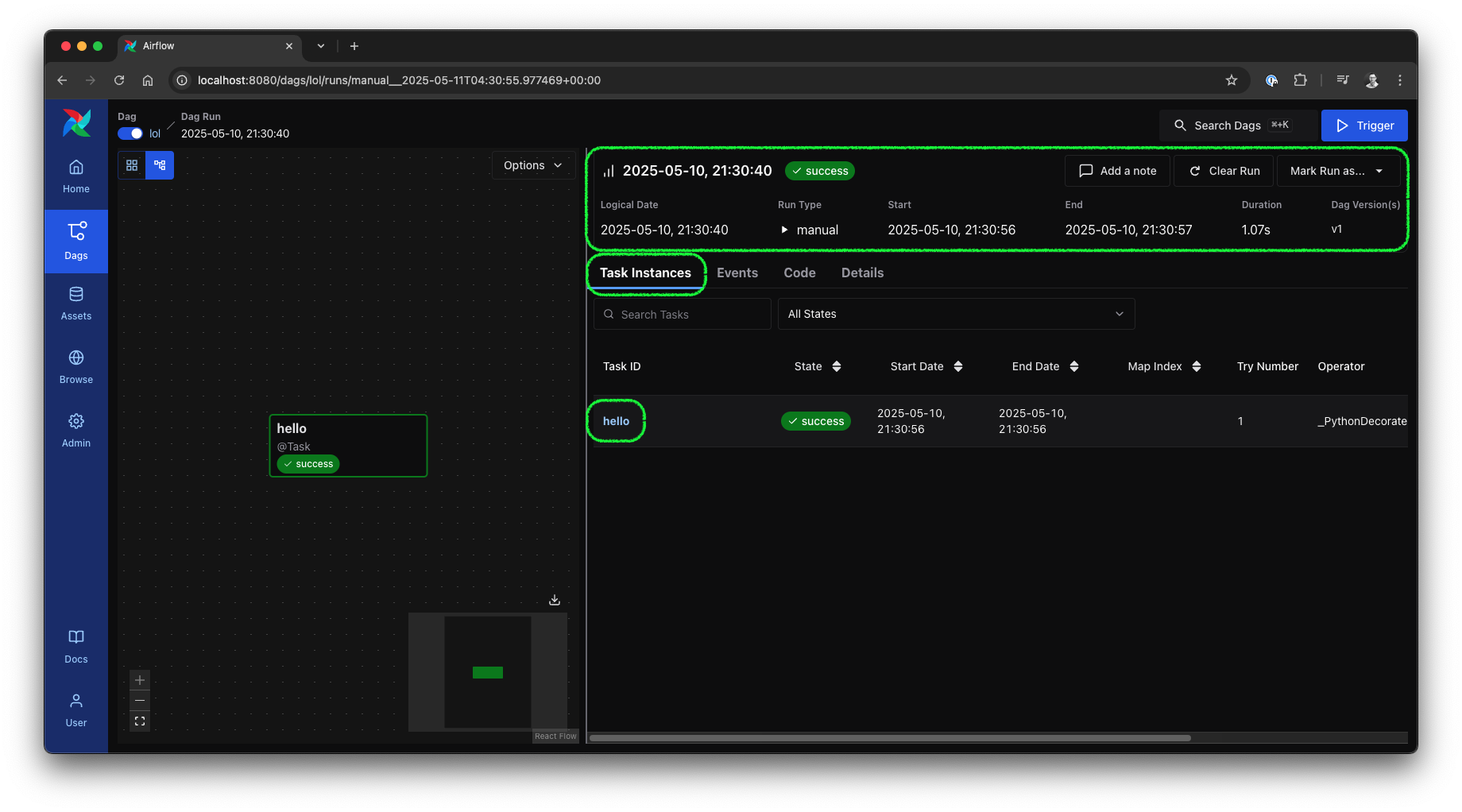 Airflow 3 UI: DAG run view, source: by author
Airflow 3 UI: DAG run view, source: by author
Clicking on an individual task ID will open the new log view. This log view allows for log level filtering, colorized output, and more—a feature I personally appreciate a lot.
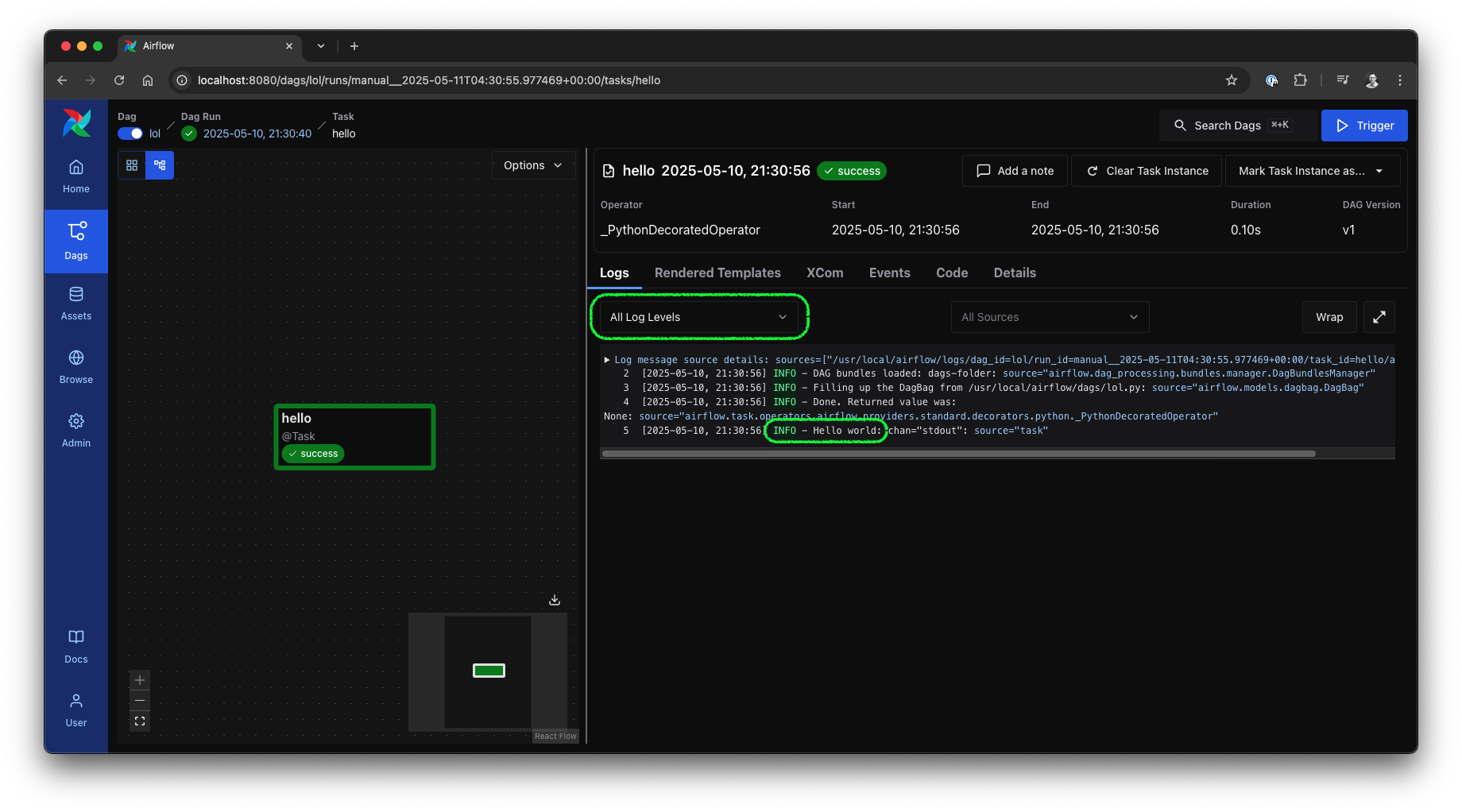 Airflow 3 UI: Task instance logs view, source: by author
Airflow 3 UI: Task instance logs view, source: by author
Now that we are more familiar with the new UI, let’s dive into our end-to-end pipeline.
New in Airflow 3: Key upgrades for the new Airflow UI include a modern React interface, UI-driven backfills, enhanced task logs, and integrated DAG Versioning details, making DAG management much smoother.
Our mission to engineer insights from the League of Legends universe begins with understanding our primary data source: the Riot Games API. Riot generously provides the developer community with access to a wealth of game data, a key part of their commitment to empowering players and developers to enrich the LoL experience. This API is our gateway to the raw information that fuels our analysis.
First, you’ll need to establish your credentials. Navigate to the Riot Games Developer Portal to either log in with your existing Riot account or create a new one.
 Riot Games Developer Portal, source: Riot Games
Riot Games Developer Portal, source: Riot Games
Once logged in, obtaining an API key is straightforward. Click on your user profile in the top right corner, then select Dashboard. Here, you’ll find the option to Generate API Key. Secure this key, as it’s your personal passport to the API.
 Generate API key for Riot Games API, source: Riot Games
Generate API key for Riot Games API, source: Riot Games
Before architecting complex data pipelines or writing extensive client code, effective preparation is key. Our initial scouting mission involves probing the Riot Games API with fundamental CLI tools: curl for making HTTP requests and jq (a lightweight JSON processor) for neatly displaying the JSON responses. This hands-on, minimalist approach allows us to quickly understand the data structures, identify the necessary endpoints, and map out the data relationships crucial for our project, all without the immediate overhead of more complex frameworks.
The API offers a multitude of endpoints, but for our objective—analyzing champion performance based on top-tier player matches—we’ll focus on a specific sequence.
Let’s begin by defining some environment variables for convenience in our curl commands. Remember to replace YOUR-RIOT-API-KEY with the actual key you generated.
REGION="na1"
ROUTING="americas"
API_KEY="YOUR-RIOT-API-KEY"Our analysis will focus on high-level play. In League of Legends, players (often referred to as summoners) are ranked into tiers. We’ll start by fetching a list of players from the Challenger tier in the North American (NA) region for the popular Ranked Solo 5x5 queue.
# Get top-ranked (Challenger tier) players in North America
curl -s "https://$REGION.api.riotgames.com/lol/league/v4/challengerleagues/by-queue/RANKED_SOLO_5x5" \
-H "X-Riot-Token: $API_KEY" | jqThis will give us a list of summoners, including their summonerId.
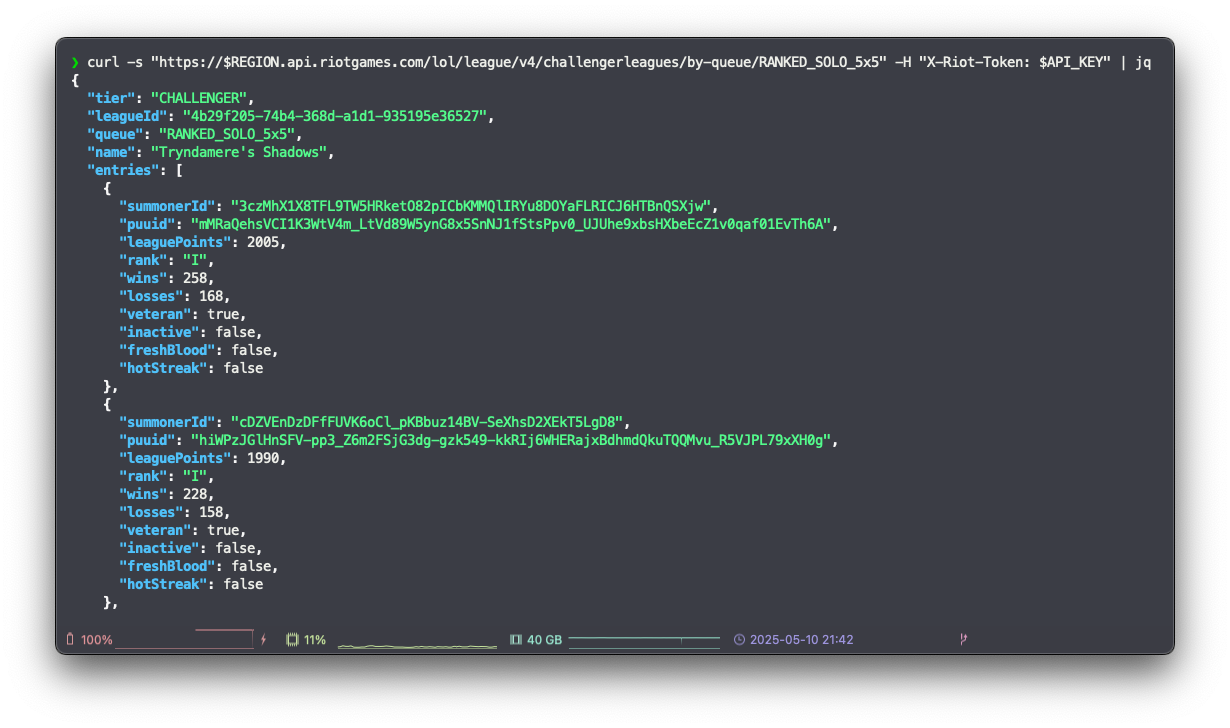 Get top-ranked players via Riot Games API, source: by author
Get top-ranked players via Riot Games API, source: by author
To analyze player performance, we need their match histories. However, the Riot API endpoint for fetching match IDs requires a PUUID (Player Universally Unique Identifier), not the summonerId we just obtained. Therefore, our next step is to retrieve the detailed summoner information for one of these top players to get their PUUID.
Let’s use an example summonerId from the previous step’s output:
# Get detailed summoner information, including PUUID
SUMMONER_ID="NMhRtze2cM1bNRkbbCPFpQjFDRjBxwyRLprUkWlJoDbBgls"
curl -s "https://$REGION.api.riotgames.com/lol/summoner/v4/summoners/$SUMMONER_ID" \
-H "X-Riot-Token: $API_KEY" | jqFrom this response, we can extract the puuid.
With the PUUID in hand, we can now query the API for a list of recent match IDs played by that summoner. We’ll fetch the 5 most recent matches for this example.
# Get 5 most recent match IDs for a player
PUUID="Bfdp2dJ3kOGOlfs_CHofVM5ozPuSnDoyeJ7kASTMzRaixL67raKIppsqYk1oMLbn7YNGnnq9WuWtwQ"
curl -s "https://$ROUTING.api.riotgames.com/lol/match/v5/matches/by-puuid/$PUUID/ids?count=5" \
-H "X-Riot-Token: $API_KEY" | jqFinally, to get the granular data needed for our champion analysis (like which champions were played, kills, deaths, assists, damage dealt, etc.), we need to fetch the full details for each match ID.
# Get detailed match data
MATCH_ID="NA1_5271478301"
curl -s "https://$ROUTING.api.riotgames.com/lol/match/v5/matches/$MATCH_ID" \
-H "X-Riot-Token: $API_KEY" | jqThis detailed match data is precisely what we’ll feed into our pipeline and eventually to our AI for analysis.
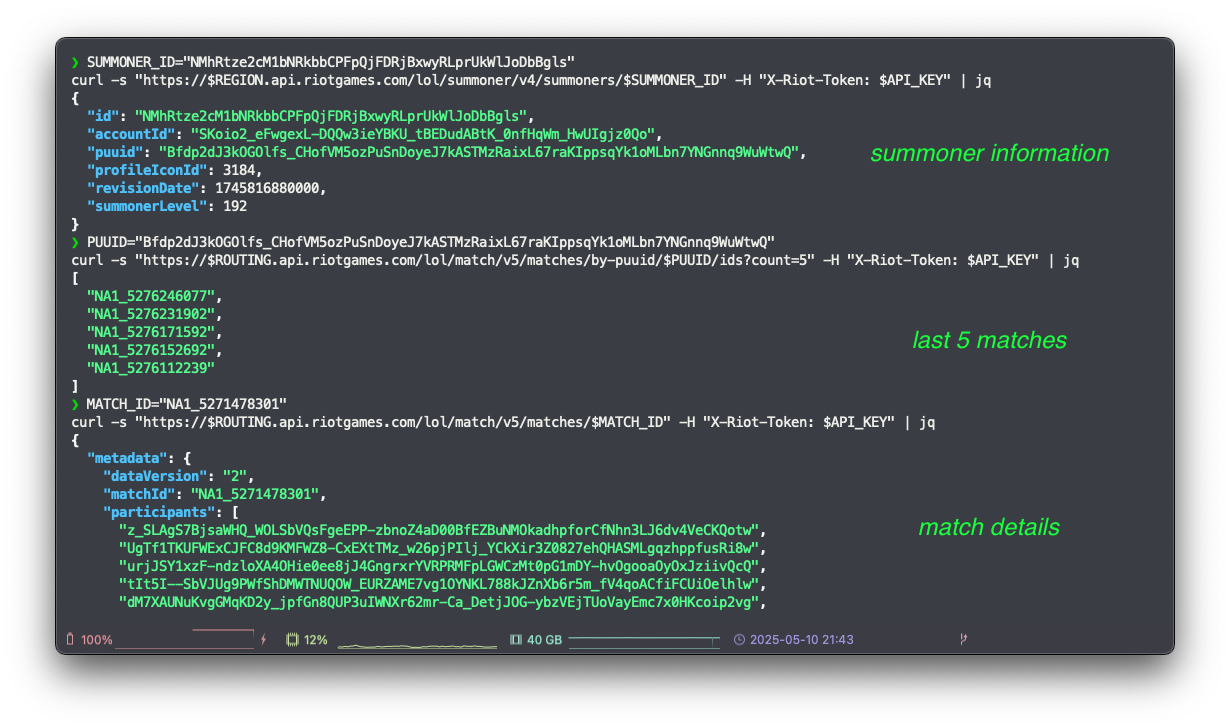 Get detailed match data via Riot Games API, source: by author
Get detailed match data via Riot Games API, source: by author
This pragmatic, step-by-step exploration with basic CLI tools has allowed us to quickly grasp the API’s structure, understand the necessary data flow, and identify the key pieces of information we need. With this foundational knowledge, our scouting mission is complete. We’re now well-prepared to forge a more robust tool for these tasks.
Note: Manually probing an API’s endpoints with simple tools before extensive coding is a cornerstone of effective Data Engineering. This initial exploration helps validate assumptions, understand data relationships (like the PUUID requirement here), and prevent costly design missteps in your client or pipeline. Always know your data source intimately before you code for it.
With our initial exploration of the Riot Games API complete, it’s time to move beyond simple curl commands and forge a legendary item: a dedicated Python API client. A common practice I follow, especially when dealing with more complex API integrations or when aiming for cleaner Airflow DAGs, is to encapsulate all API interaction logic within a standalone client. This separation of concerns keeps the DAG file focused on orchestration, enhancing readability and maintainability.
While Airflow provides tools like the HttpOperator (see documentation), developing a custom client or leveraging well-structured third-party libraries often grants superior flexibility, type safety, and tailored error handling—crucial for production-grade pipelines.
Our goal here is to create exactly that: a modern, maintainable Python client that translates our curl findings into reusable, type-safe functions. We’ll employ a contemporary asynchronous approach using httpx for efficient, non-blocking HTTP requests, and pydantic for robust data validation and modeling.
A common scenario when integrating with external APIs is a mismatch in naming conventions. The Riot Games API, like many web APIs, returns JSON properties in camelCase, while Python best practices (PEP-8) advocate for snake_case in variable and attribute names. Pydantic offers an elegant solution. Instead of manually defining aliases for every field, we can use an alias_generator in our model configuration to automatically handle this conversion:
from pydantic import BaseModel, ConfigDict
from pydantic.alias_generators import to_camel
class LeagueEntry(BaseModel):
model_config = ConfigDict(alias_generator=to_camel)
summoner_id: str
league_points: int
wins: int = 0
losses: int = 0The Riot Games API, like most public APIs, enforces rate limits to ensure fair usage and stability. Our client must be resilient to these. We’ll implement a simple retry mechanism: if we receive an HTTP 429 Too Many Requests status, our client will automatically pause for 60 seconds before retrying, up to a defined maximum number of attempts.
Now, let’s consolidate our API interaction logic, Pydantic models, and the retry strategy into riot.py, a new Python file placed alongside our lol.py DAG file. This client will include an example main function to demonstrate its standalone usage.
import asyncio
from datetime import datetime
from enum import Enum
from typing import List, Dict, Any, Optional
import httpx
from pydantic import BaseModel, ConfigDict
from pydantic.alias_generators import to_camel
class Region(str, Enum):
NORTH_AMERICA = "na1"
class RoutingValue(str, Enum):
AMERICAS = "americas"
class Queue(str, Enum):
RANKED_SOLO = "RANKED_SOLO_5x5"
class LeagueEntry(BaseModel):
model_config = ConfigDict(alias_generator=to_camel)
summoner_id: str
league_points: int
wins: int = 0
losses: int = 0
class Summoner(BaseModel):
model_config = ConfigDict(alias_generator=to_camel)
id: str
account_id: str
puuid: str
summoner_level: int
class Participant(BaseModel):
model_config = ConfigDict(alias_generator=to_camel)
puuid: str
champion_id: int
champion_name: str
win: bool
kills: int
deaths: int
assists: int
total_damage_dealt_to_champions: int
gold_earned: int
vision_score: float
total_minions_killed: int
class MatchInfo(BaseModel):
model_config = ConfigDict(alias_generator=to_camel)
game_creation: datetime
game_duration: int
game_mode: str
game_type: str
game_version: str
map_id: int
participants: List[Participant]
class MatchMetadata(BaseModel):
model_config = ConfigDict(alias_generator=to_camel)
data_version: int
match_id: str
participants: List[str]
class Match(BaseModel):
metadata: MatchMetadata
info: MatchInfo
class RiotApiClient:
def __init__(
self,
api_key: str,
region: str = Region.NORTH_AMERICA.value,
routing: str = RoutingValue.AMERICAS.value,
timeout: int = 10
):
self.api_key = api_key
self.region = region
self.routing = routing
self.timeout = timeout
self.headers = {"X-Riot-Token": api_key}
self.client = httpx.AsyncClient(timeout=timeout)
async def close(self):
await self.client.aclose()
async def __aenter__(self):
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
await self.close()
async def _get(self, url: str, params: Optional[Dict[str, Any]] = None) -> Any:
retry_count = 0
max_retries = 5
while retry_count < max_retries:
try:
response = await self.client.get(url, headers=self.headers, params=params)
response.raise_for_status()
return response.json()
except httpx.HTTPStatusError as e:
if e.response.status_code == 429:
retry_count += 1
print(f"Rate limit exceeded. Waiting 60 seconds... (Attempt {retry_count}/{max_retries})")
await asyncio.sleep(60)
else:
raise
except Exception as e:
raise
raise Exception(f"Rate limit exceeded after {max_retries} retries")
async def get_challenger_league(self, queue: str = Queue.RANKED_SOLO.value) -> List[LeagueEntry]:
url = f"https://{self.region}.api.riotgames.com/lol/league/v4/challengerleagues/by-queue/{queue}"
data = await self._get(url)
return [LeagueEntry.model_validate(entry) for entry in data.get("entries", [])]
async def get_summoner_by_id(self, summoner_id: str) -> Summoner:
url = f"https://{self.region}.api.riotgames.com/lol/summoner/v4/summoners/{summoner_id}"
data = await self._get(url)
return Summoner.model_validate(data)
async def get_top_players(self, count: int = 10) -> List[Summoner]:
challenger_entries = await self.get_challenger_league()
sorted_entries = sorted(challenger_entries, key=lambda entry: entry.league_points, reverse=True)
top_entries = sorted_entries[:count]
tasks = [self.get_summoner_by_id(entry.summoner_id) for entry in top_entries]
return await asyncio.gather(*tasks)
async def get_match_ids_by_puuid(self, puuid: str, count: int = 5, start: int = 0) -> List[str]:
url = f"https://{self.routing}.api.riotgames.com/lol/match/v5/matches/by-puuid/{puuid}/ids"
params = {"count": count, "start": start}
return await self._get(url, params)
async def get_match(self, match_id: str) -> Match:
url = f"https://{self.routing}.api.riotgames.com/lol/match/v5/matches/{match_id}"
data = await self._get(url)
return Match.model_validate(data)
async def get_matches_for_summoners(self, summoners: List[Summoner], matches_per_summoner: int = 5) -> List[Match]:
match_id_tasks = [
self.get_match_ids_by_puuid(summoner.puuid, count=matches_per_summoner)
for summoner in summoners
]
all_match_ids = await asyncio.gather(*match_id_tasks)
unique_match_ids = list(set(match_id for sublist in all_match_ids for match_id in sublist))
match_tasks = [self.get_match(match_id) for match_id in unique_match_ids]
return await asyncio.gather(*match_tasks)
async def example_usage():
api_key = "YOUR-RIOT-API-KEY"
async with RiotApiClient(api_key) as client:
players = await client.get_top_players()
matches = await client.get_matches_for_summoners(players, matches_per_summoner=5)
print(matches)
if __name__ == "__main__":
asyncio.run(example_usage())Executing this riot.py script directly will now demonstrate its capabilities, fetching data and printing match details to your console. We’ve successfully forged our legendary item—a robust, asynchronous, and type-safe client. With this tool in hand, we are exceptionally well-prepared to summon the data within our Airflow DAG.
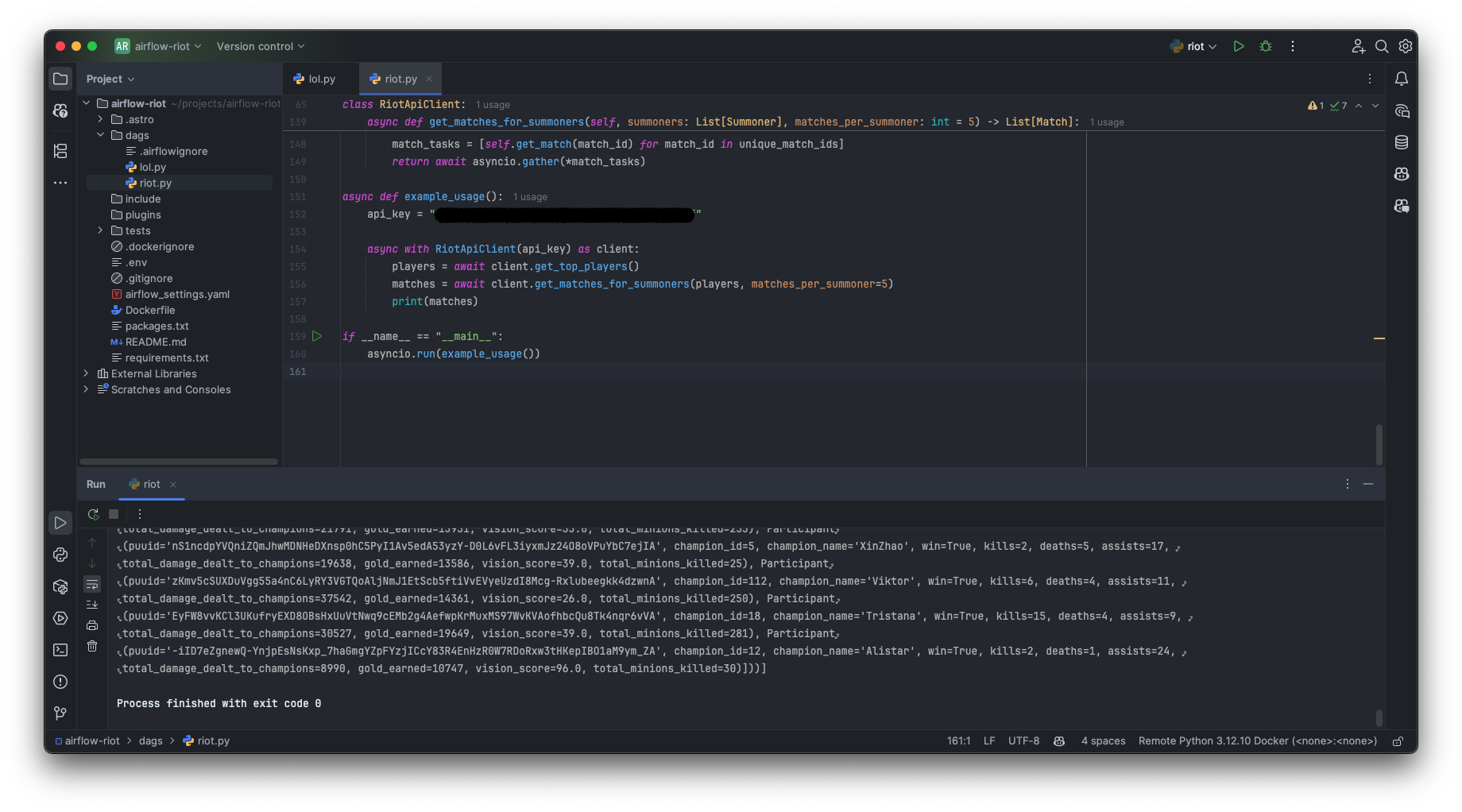 Modern API client in Python, source: by author
Modern API client in Python, source: by author
Airflow tip: For cleaner Airflow DAGs and more robust data integrations, encapsulate API interaction logic within a dedicated, reusable client. This promotes separation of concerns, simplifies DAG readability, and allows for tailored features like type safety (with Pydantic) and custom retry logic.
With our legendary item—the robust RiotApiClient—forged and ready, we now stand at the threshold of orchestration. The next crucial step is to integrate this client into an Apache Airflow DAG, transforming our standalone data fetching capabilities into a repeatable, monitorable, and scalable data pipeline.
However, before we jump into writing DAG code, a moment of strategic planning is essential—much like coordinating a team before a major objective in League of Legends. Blindly implementing tasks can lead to tangled dependencies and unmanageable workflows. Instead, we’ll first outline our data flow and define how responsibilities will be segmented into distinct Airflow tasks. This planning ensures a cleaner, more logical, and maintainable pipeline structure.
Our battle plan for summoning and processing LoL data involves three primary phases, which will translate into at least three or more core tasks within our DAG:
RiotApiClient to fetch a list of top-ranked (Challenger tier) players.This sequence forms the backbone of our DAG, as conceptualized below:
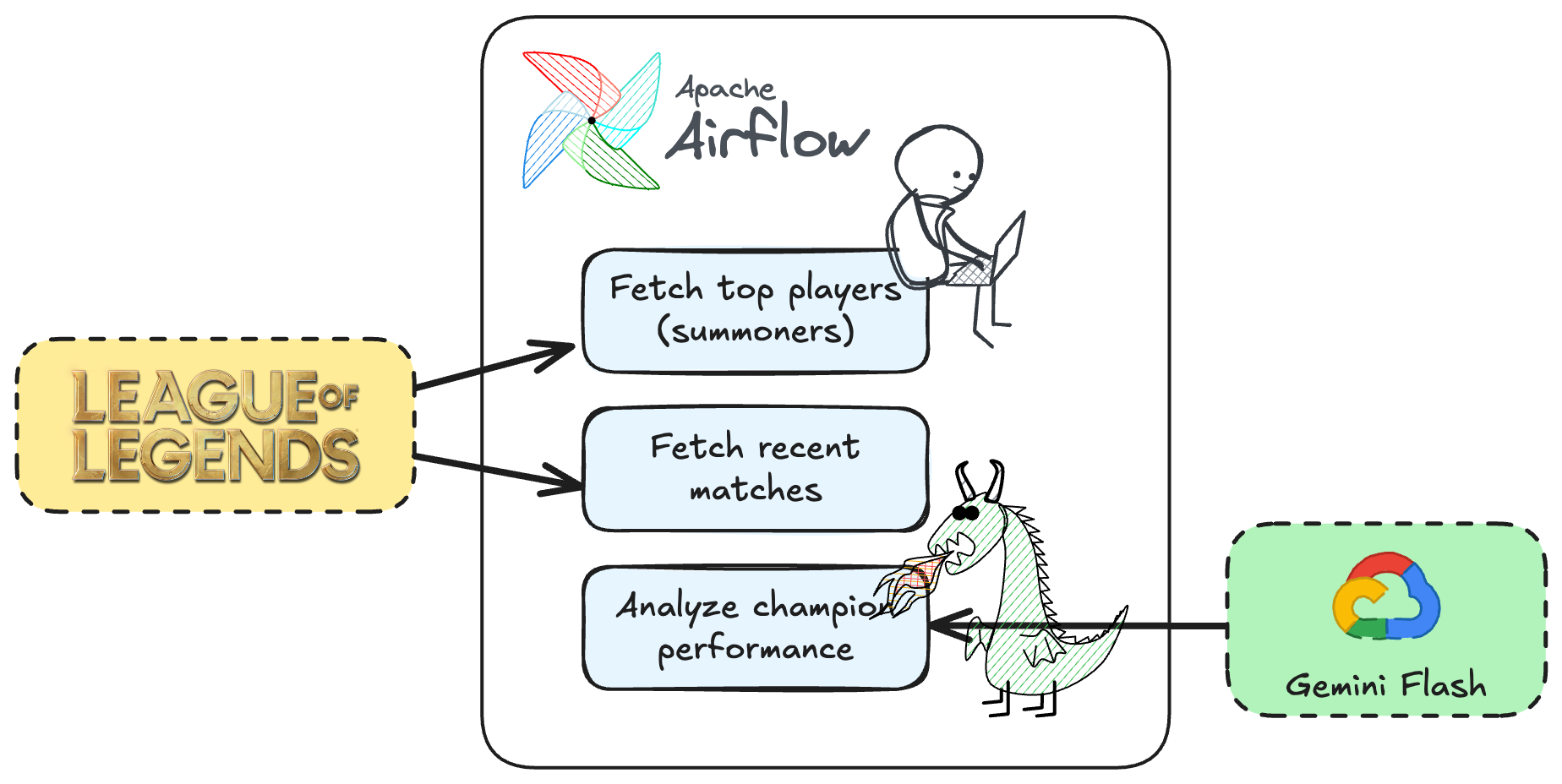 DAG concept, source: by author
DAG concept, source: by author
With this clear strategy in mind, we’re ready to translate our plan into Airflow tasks and construct our data pipeline.
With our strategic plan outlined, let’s take the next logical step in constructing our Airflow pipeline. We’ll begin by modifying our simple Hello World DAG in dags/lol.py to incorporate our newly forged RiotApiClient. The initial goal is straightforward: create a single Airflow task dedicated to fetching the list of top players.
import asyncio
from airflow.sdk import dag, task
from dags.riot import RiotApiClient
API_KEY = "YOUR-RIOT-API-KEY"
@dag(schedule=None)
def lol():
@task
def fetch_top_players():
client = RiotApiClient(API_KEY)
players = asyncio.run(client.get_top_players())
return players
top_players = fetch_top_players()
lol()A word of caution: if you trigger this DAG as is, it will encounter a failure. This presents an excellent opportunity to explore Airflow’s logging capabilities, especially with the new Airflow 3 UI making log access more intuitive. As an exercise, try running the DAG and inspecting the logs for the fetch_top_players task. You should find an error message similar to this:
TypeError: cannot serialize object of type <class 'dags.riot.Summoner'>This TypeError is a common hurdle when working with custom Python objects in Airflow. It arises because Airflow’s mechanism for passing data between tasks (XComs, short for cross-communications) requires that data to be serializable (convertible into a format like JSON that can be easily stored and retrieved). By default, Airflow doesn’t know how to serialize our custom Pydantic model instances.
 Serialization error, source: by author
Serialization error, source: by author
Despite this, we still want to leverage the benefits of Pydantic models (like type safety and auto-validation) within our task logic. One solution is to use the Pydantic models for internal processing within a task and then convert these model instances into a serializable format (typically dictionaries) before returning them for cross-communication. When another task receives this data, it can then deserialize the dictionaries back into Pydantic model instances if needed.
Let’s apply this fix:
import asyncio
from airflow.sdk import dag, task
from dags.riot import RiotApiClient
API_KEY = "YOUR-RIOT-API-KEY"
@dag(schedule=None)
def lol():
@task
def fetch_top_players():
client = RiotApiClient(API_KEY)
players = asyncio.run(client.get_top_players())
# Convert Pydantic models to dictionaries for Airflow compatible serialization
return [player.model_dump(by_alias=True) for player in players]
top_players = fetch_top_players()
lol()Airflow tip: Leverage Pydantic models for robust, type-safe data handling within your task’s business logic. For inter-task data exchange, convert model instances to serializable dictionaries (e.g., using .model_dump()) and deserialize back to models in downstream tasks if needed.
Before we proceed, let’s address the hardcoded API_KEY. Storing sensitive credentials directly in DAG files is not a recommended practice. Airflow provides a secure and flexible way to manage such configurations: Variables. Variables are a global key-value store accessible from your tasks and easily managed via the Airflow UI, CLI, or API.
Replace the hardcoded API key line with:
from airflow.sdk import dag, task, Variable
# ...
API_KEY = Variable.get("riot_api_key")Next, navigate to the Airflow UI: Admin –> Variables –> Add Variable.
riot_api_key.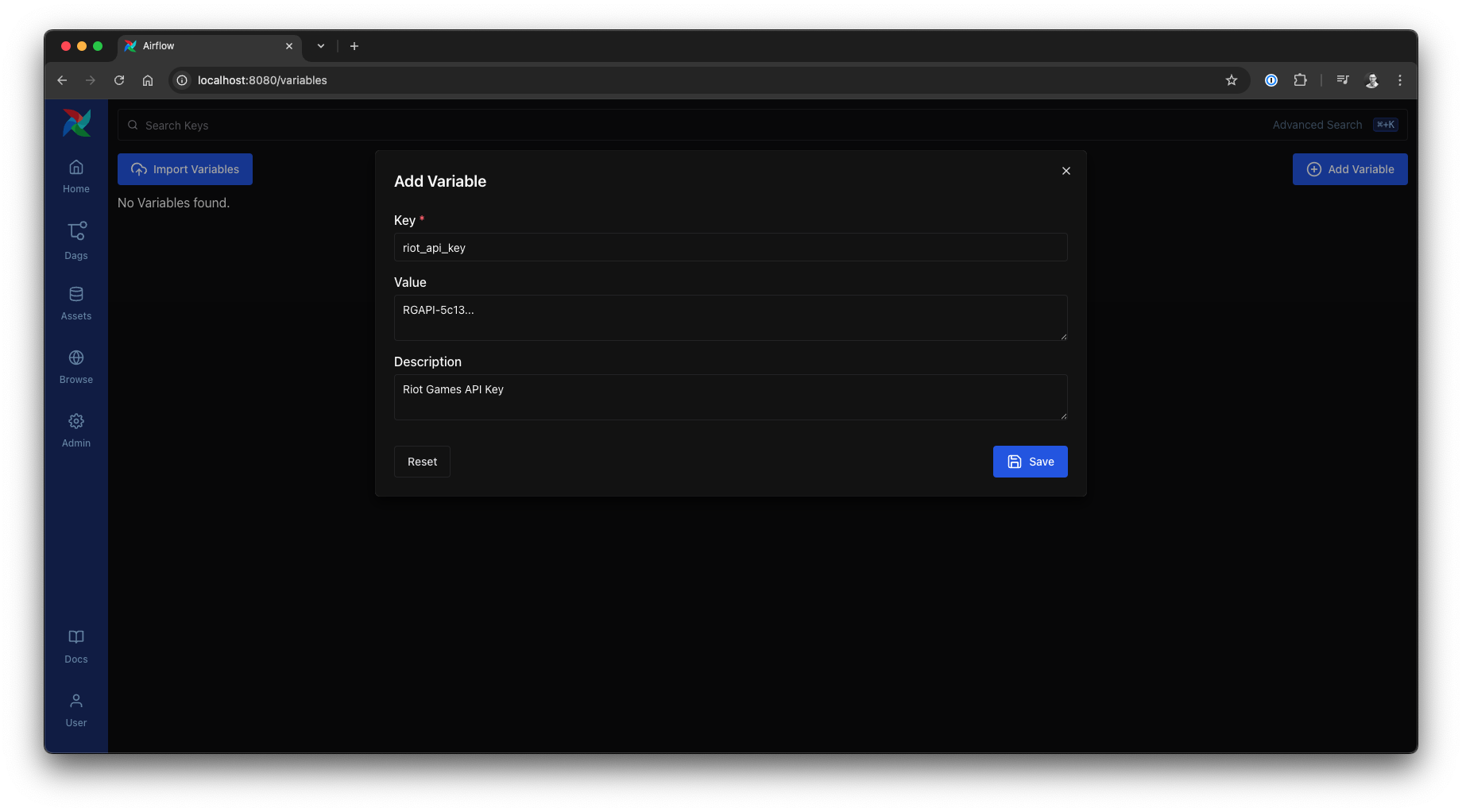 Adding an Airflow Variable for the API key, source: by author
Adding an Airflow Variable for the API key, source: by author
New in Airflow 3: While Airflow Variables are a long-standing feature, the Variables view within the modernized Airflow 3 UI offers improved accessibility and a more streamlined management experience.
With our API key securely stored as an Airflow Variable and our initial task successfully fetching and returning player data, we’re now ready to expand our pipeline and integrate more complex API interactions.
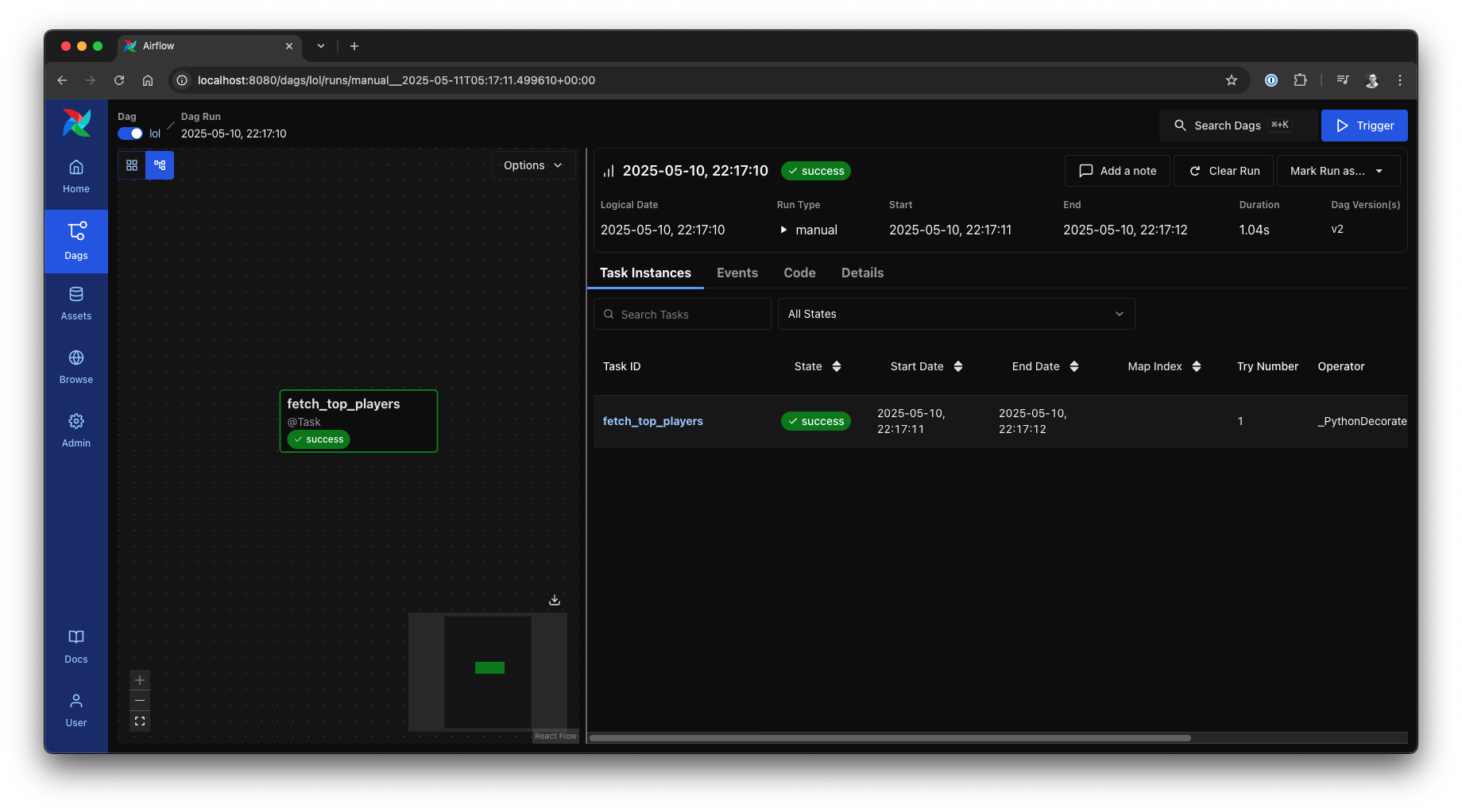 Serialization issue solved, source: by author
Serialization issue solved, source: by author
Our pipeline has successfully identified top-tier players. The next logical step is to gather the recent match histories for each of these players. While our RiotApiClient is capable of fetching matches for a list of summoners, this presents a perfect opportunity to introduce and leverage a powerful, modern Airflow feature designed for exactly this kind of parallel, one-to-many workload: Dynamic Task Mapping.
Instead of fetching all matches sequentially in a single task or manually creating a fixed number of tasks, Dynamic Task Mapping allows a DAG to generate a variable number of task instances at runtime, based on the output of an upstream task. This is ideal for scenarios where the degree of parallelism isn’t known when the DAG is authored, such as processing items from a list whose length can change.
The concept is elegantly simple. An upstream task (like our fetch_top_players) outputs a list (or a dictionary). A downstream task can then be mapped over this output. Airflow will dynamically create one instance of this mapped task for each item in the input list. Each instance receives one item from the list as its input parameter. This is far more dynamic and cleaner than traditional approaches like manually looping within a PythonOperator or defining a fixed number of tasks.
Crucially, the new Airflow 3 UI offers significantly enhanced visualization for these dynamically mapped tasks, making it exceptionally convenient to monitor, debug, and understand the execution of parallelized workflows. This clarity transforms Dynamic Task Mapping into an indispensable tool in the modern Data Engineer’s toolbox.
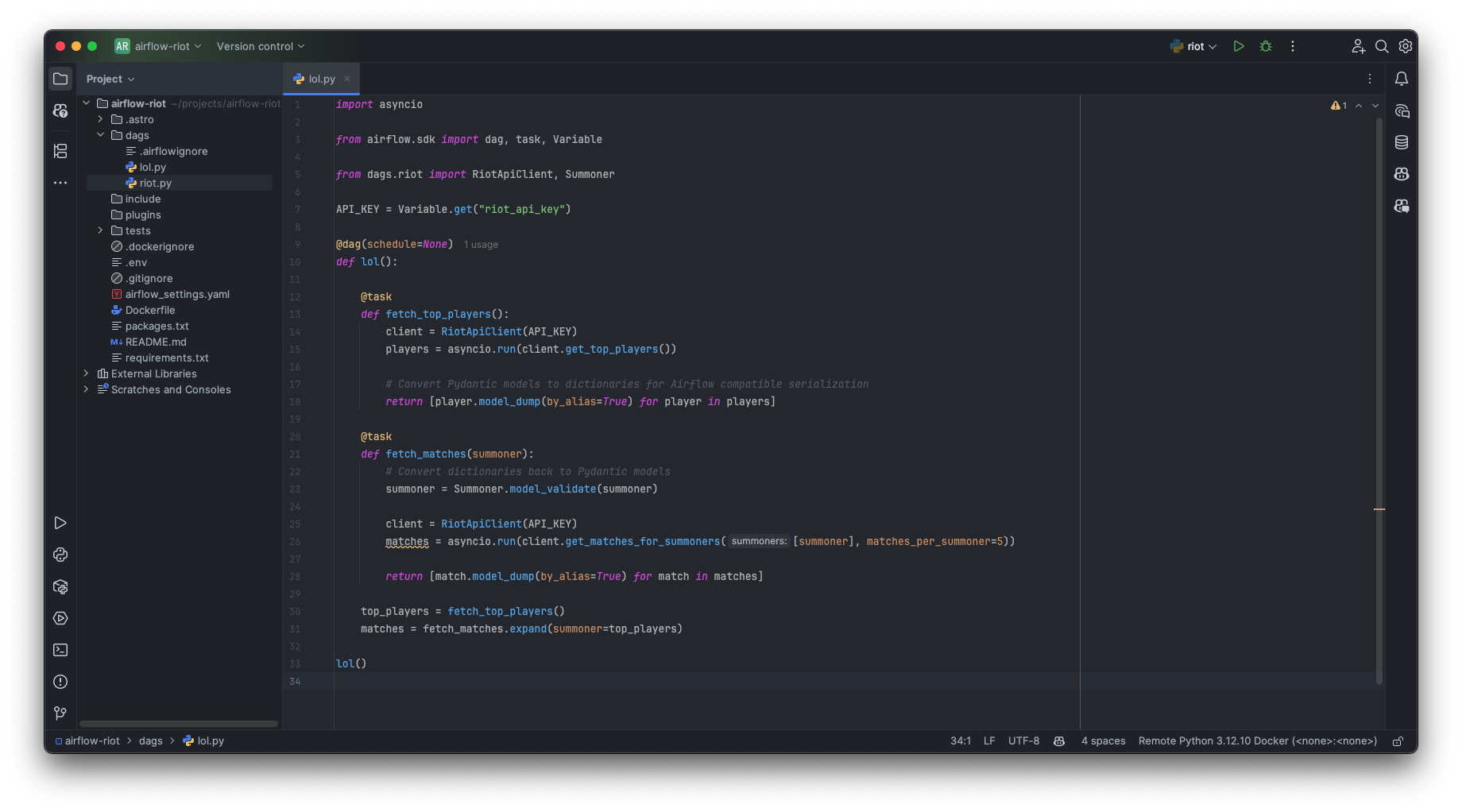
Let’s adapt our DAG to use Dynamic Task Mapping. The fetch_matches task will be expanded based on the list of top_players returned by the fetch_top_players task:
import asyncio
from airflow.sdk import dag, task, Variable
from dags.riot import RiotApiClient, Summoner
API_KEY = Variable.get("riot_api_key")
@dag(schedule=None)
def lol():
@task
def fetch_top_players():
client = RiotApiClient(API_KEY)
players = asyncio.run(client.get_top_players())
# Convert Pydantic models to dictionaries for Airflow compatible serialization
return [player.model_dump(by_alias=True) for player in players]
@task
def fetch_matches(summoner):
# Convert dictionaries back to Pydantic models
summoner = Summoner.model_validate(summoner)
client = RiotApiClient(API_KEY)
matches = asyncio.run(client.get_matches_for_summoners([summoner], matches_per_summoner=5))
return [match.model_dump() for match in matches]
top_players = fetch_top_players()
matches = fetch_matches.expand(summoner=top_players)
lol()When you execute this DAG, the Airflow UI will nicely illustrate the dynamically created instances of fetch_matches. You’ll see a distinct visual representation for each player, allowing you to easily track their individual progress and access logs.
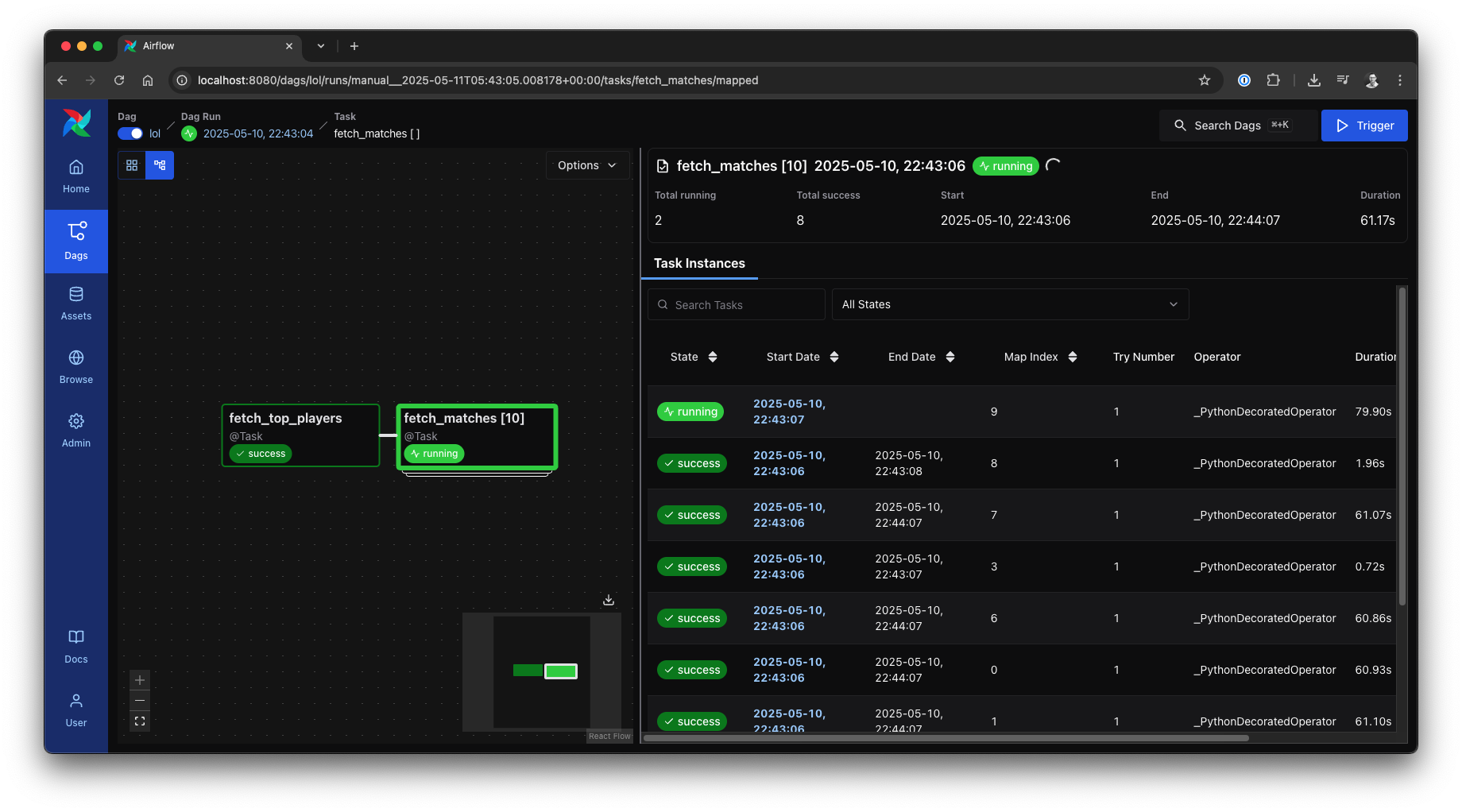 Dynamically mapped tasks in the new Airflow UI, source: by author
Dynamically mapped tasks in the new Airflow UI, source: by author
Dynamic Task Mapping effectively parallelizes our match fetching. However, the output of fetch_matches.expand(...) will be a list of lists—specifically, a list where each element is the list of matches fetched for one player.
 Dynamic Task Mapping implementation, source: by author
Dynamic Task Mapping implementation, source: by author
Our next challenge is to consolidate these results. We need to:
Let’s add a combine_matches task to handle this:
import asyncio
from airflow.sdk import dag, task, Variable
from dags.riot import RiotApiClient, Summoner, Match
API_KEY = Variable.get("riot_api_key")
@dag(schedule=None)
def lol():
@task
def fetch_top_players():
client = RiotApiClient(API_KEY)
players = asyncio.run(client.get_top_players())
# Convert Pydantic models to dictionaries for Airflow compatible serialization
return [player.model_dump(by_alias=True) for player in players]
@task
def fetch_matches(summoner):
# Convert dictionaries back to Pydantic models
summoner = Summoner.model_validate(summoner)
client = RiotApiClient(API_KEY)
matches = asyncio.run(client.get_matches_for_summoners([summoner], matches_per_summoner=5))
return [match.model_dump(by_alias=True) for match in matches]
@task
def combine_matches(match_lists):
all_matches = [Match.model_validate(match) for sublist in match_lists for match in sublist]
unique_matches = []
for match in all_matches:
if match not in unique_matches:
unique_matches.append(match)
return [match.model_dump(by_alias=True) for match in unique_matches]
top_players = fetch_top_players()
matches = fetch_matches.expand(summoner=top_players)
unique_matches = combine_matches(matches)
lol()The unique_matches output from this task now represents the clean, consolidated dataset we need as input for our AI-driven champion analysis in the next stage.
Airflow tip: When you need to run the same task for each item in a list (e.g., processing files, fetching data per ID), Dynamic Task Mapping (.expand()) is your go-to. It simplifies DAGs by dynamically creating task instances at runtime based on upstream output.
Having gathered and prepared our League of Legends match data, we’ve arrived at the exciting moment: transforming this raw information into strategic intelligence. For this, we unleash our ultimate skill—a powerful, yet perhaps still under-the-radar, framework known as the Airflow AI SDK. This innovative SDK, built upon the foundations of PydanticAI, is designed to seamlessly integrate LLMs and AI agent capabilities directly into your Apache Airflow pipelines.
As AI workflows become increasingly integral to modern data strategies, organizations seek pragmatic, scalable, and reliable ways to orchestrate them. Airflow, already the de facto standard for complex data pipeline orchestration, is perfectly positioned to manage these AI-centric processes. The Airflow AI SDK bridges this gap beautifully by:
@task.llm, @task.llm_branch, and @task.agent extends the intuitive @task decorator, making AI integration feel like a natural extension of existing Airflow practices.A heartfelt shoutout to Marc Lamberti for bringing this powerful SDK and its potential onto my radar!
With the @task.llm decorator, for instance, we can effortlessly specify an LLM (like Google’s Gemini, which we’ll use), define a system prompt to guide its behavior, and let the SDK handle the transformation of our Airflow task’s input data into the appropriate format for the LLM. While PydanticAI supports a range of models, our focus here will be on utilizing the capabilities of Gemini.
Before we can integrate our Gemini-powered AI analyst, a few setup steps are required:
Navigate to the Google AI Studio and click on Create API key to obtain your credentials.
 Google AI Studio, source: https://aistudio.google.com/apikey
Google AI Studio, source: https://aistudio.google.com/apikey
To add the necessary dependencies to our Astro CLI-managed Airflow environment, append the following line to your requirements.txt file. This includes support for various LLM providers and tools:
airflow-ai-sdk[google-generativeai,openai,duckduckgo]Securely provide your Gemini API key to Airflow by setting it as an environment variable. Add the following line to the .env file in your Astro project directory:
GEMINI_API_KEY=YOUR-GEMINI-API-KEYFor these modifications to take effect, restart your local Airflow environment:
astro dev restartWith these preparations complete, we are now truly ready to deploy our ultimate skill and infuse our data pipeline with intelligent analysis.
The magic of the Airflow AI SDK shines through its decorator-based approach. We’ll define a new task using @task.llm, which instructs Airflow to treat this task as an interaction with a LLM.
Let’s add the analyze task to our DAG, along with a simple send_report task to save its output:
@task.llm(model="gemini-2.0-flash", result_type=str, system_prompt="""
You're a League of Legends analyst. Analyze the match data and create a champion tier list.
Rank champions into tiers (S, A, B, C, D) based on their performance metrics:
- S Tier: Exceptional performers
- A Tier: Strong, reliable champions
- B Tier: Balanced, decent champions
- C Tier: Underperforming champions
- D Tier: Poor performers
For each tier, list the champions and briefly explain their placement.
""")
def analyze(unique_matches):
return json.dumps(unique_matches, default=str)
@task
def send_report(report):
created_at = datetime.now().strftime("%Y%m%d_%H%M%S")
base_dir = os.path.realpath(os.path.dirname(__file__))
report_path = f"{base_dir}/lol_ai_champion_report_{created_at}.md"
with open(report_path, "w") as f:
f.write(f"*Generated on: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}*\n\n")
f.write(report)
print(f"Report written to {report_path}")
print("::group::Generated report")
print(report)
print("::endgroup::")The beauty of the @task.llm decorator lies in its abstraction. We provide essential LLM details directly in the decorator:
model: Specifies the LLM to use.result_type: Defines the expected Python type of the LLM output (here, str for our Markdown report).system_prompt: Provides instructions to the LLM, guiding its persona and function.The Python function decorated with @task.llm (our analyze) is responsible for preparing and returning the input that will be sent to the LLM. In our case, it takes the unique_matches data and converts it into a JSON string.
The Airflow AI SDK takes the output of analyze and the system_prompt, sends them to the specified model, and retrieves the response.
When you call the analyze task in your pipeline, the value it appears to return is the actual output from the LLM, not the JSON string we returned from the Python function body. The SDK handles this switcheroo seamlessly.
With this understanding, let’s orchestrate the final steps of our pipeline:
top_players = fetch_top_players()
matches = fetch_matches.expand(summoner=top_players)
unique_matches = combine_matches(matches)
report = analyze(unique_matches)
send_report(report)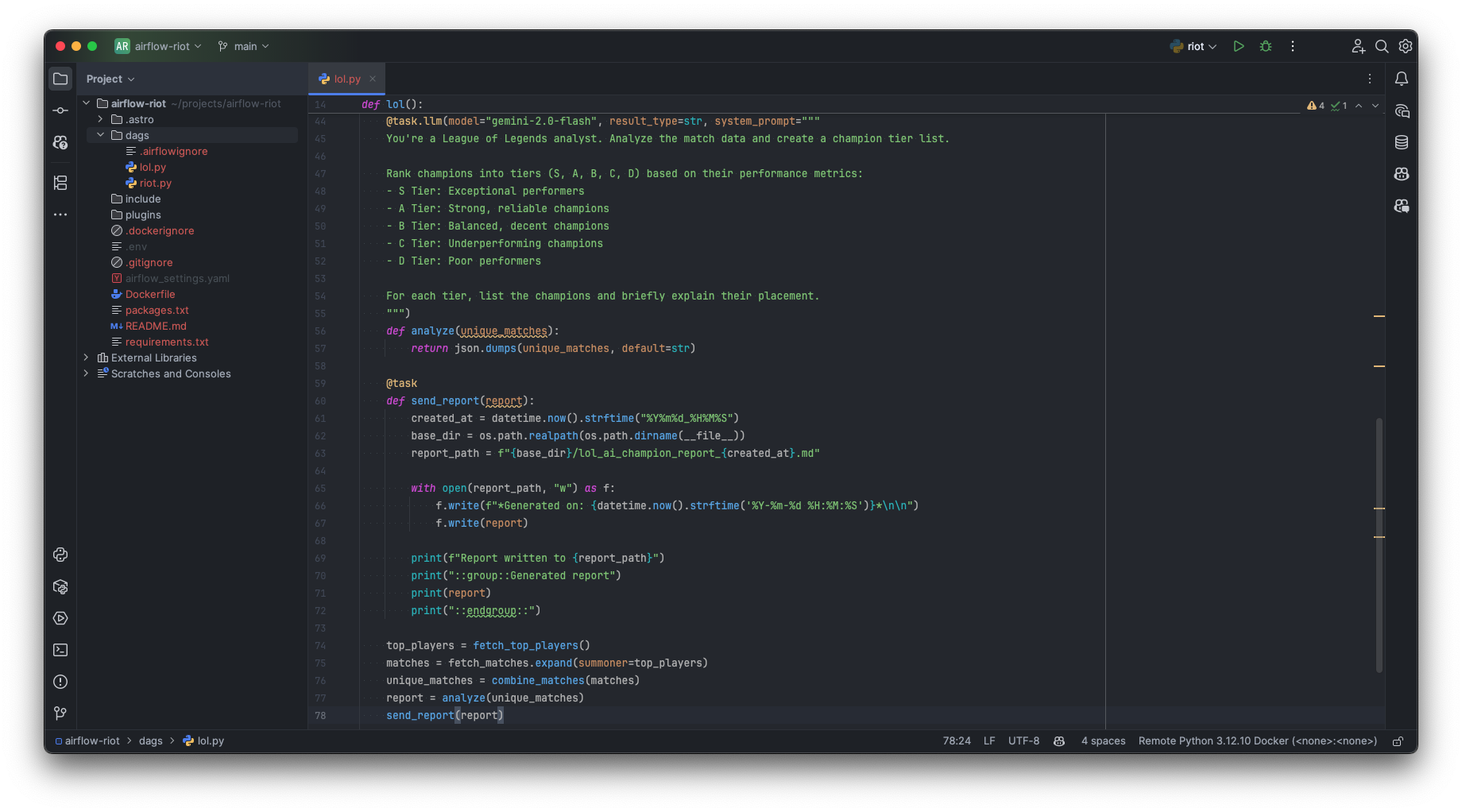 AI directly in Airflow, source: by author
AI directly in Airflow, source: by author
We now have the first complete version of our end-to-end intelligent data pipeline!
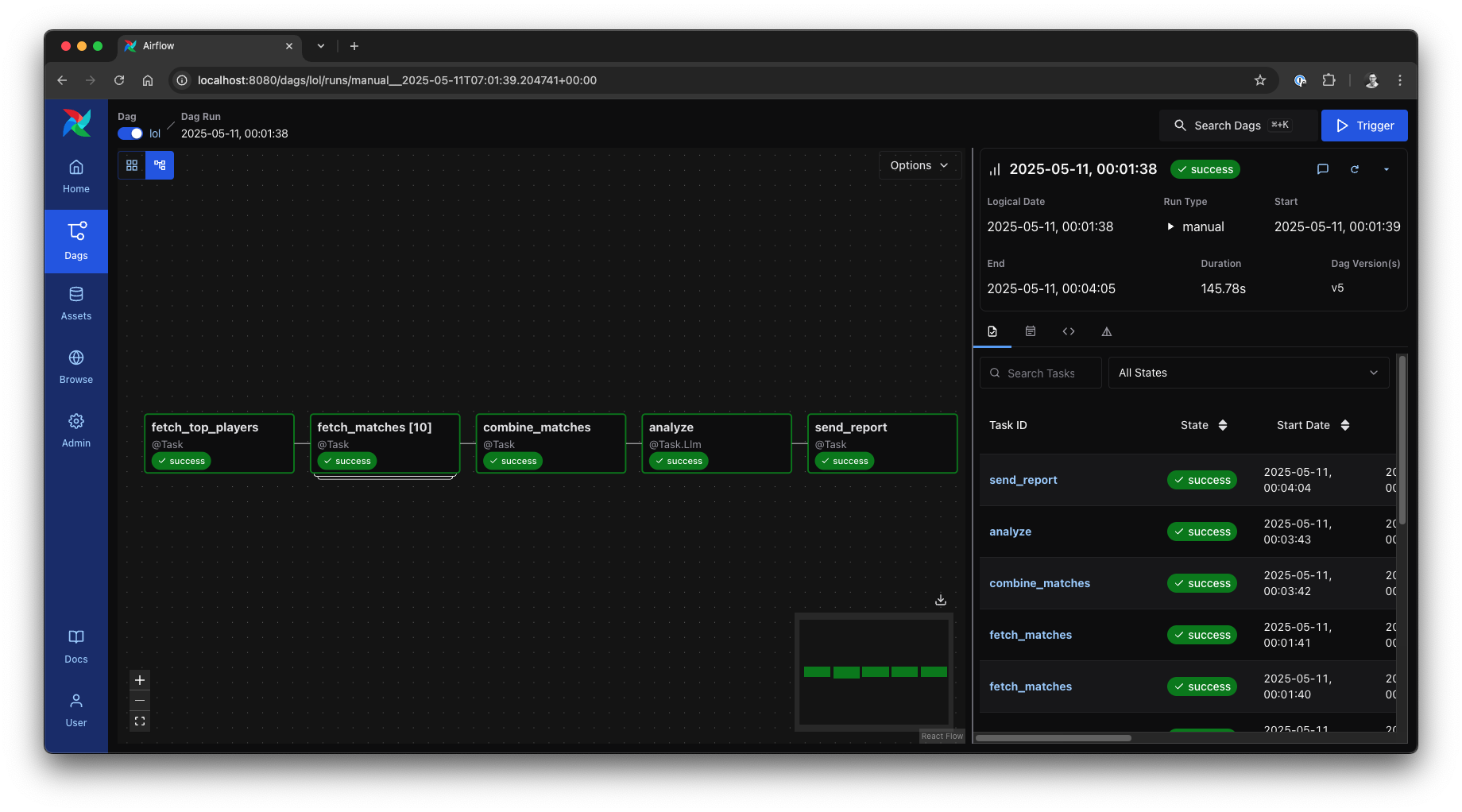 End-to-end League of Legends analysis pipeline in Airflow 3, source: by author
End-to-end League of Legends analysis pipeline in Airflow 3, source: by author
When this DAG runs, it will gather data on top players, fetch their recent matches in parallel, consolidate and deduplicate this information, and then engage our Gemini AI analyst. The result? A dynamically generated Markdown report, timestamped and saved within the DAGs folder, containing a champion tier list based on the latest match data.
The initial outcome is already quite impressive, demonstrating the power of combining robust data orchestration with cutting-edge AI:
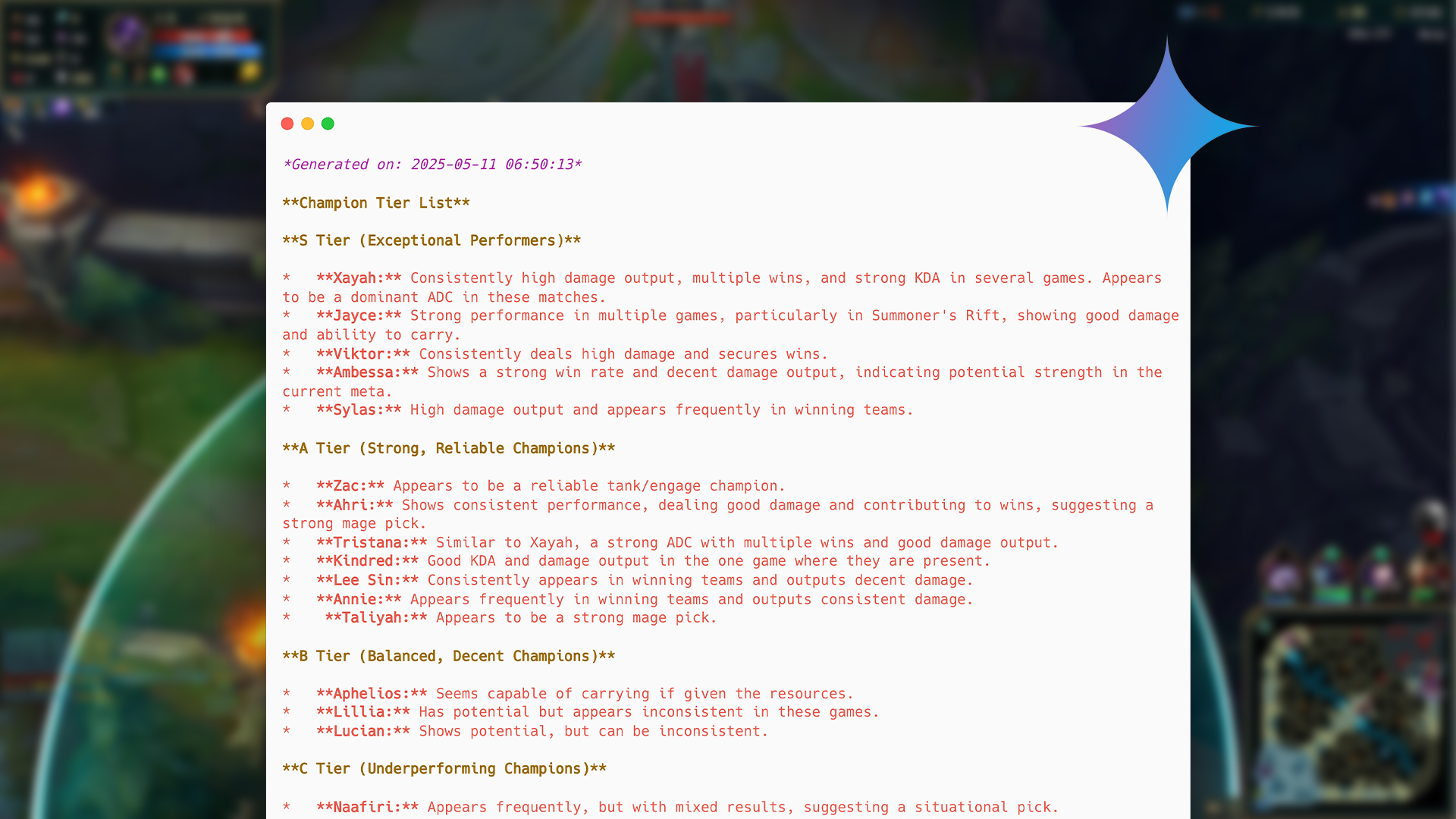 League of Legends AI generated tier list as Markdown, source: by author
League of Legends AI generated tier list as Markdown, source: by author
Our end-to-end pipeline is now operational, successfully transforming raw League of Legends data into an AI-generated champion tier list. While we have a functional version, a crucial, often overlooked, phase in Data Engineering is polishing. This isn’t about over-engineering or chasing perfection indefinitely; rather, it’s about dedicating a focused period—be it a couple of hours or a business day—to refine the solution for better maintainability, usability, and value. As Martin Fowler wisely stated:
Any fool can write code that a computer can understand. Good programmers write code that humans can understand.
Our goal as Data Engineers extends beyond mere technical execution. We must also consider the business context and strive for more business value but also simple to understand and maintainable solutions. The key is to balance sophistication with simplicity, always aiming to improve the core value delivered.
In this spirit, let’s polish our demo project. We’ll focus on two areas: enhancing our DAG definition with new Airflow 3 features and significantly upgrading our AI-generated report.
A common requirement is to run a DAG on different schedules (e.g., twice daily at specific times, or different schedules for weekdays vs. weekends). Airflow 3 simplifies this with the MultipleCronTriggerTimetable. This not only allows for defining multiple cron expressions but also for explicitly setting the timezone for these schedules, which is crucial for avoiding ambiguity.
While the DAG ID must be unique and follow certain conventions, the dag_display_name parameter allows you to set a more human-readable (and even emoji-enhanced!) name that appears in the Airflow UI. This can significantly improve the browsability of your Airflow instance, especially with many DAGs.
Let’s update our @dag decorator to incorporate these, along with a start_date (which is now required as we also set a schedule):
@dag(
schedule=MultipleCronTriggerTimetable(
"0 10 * * *",
"0 14 * * *",
timezone="UTC"
),
start_date=datetime(2025, 5, 10),
dag_display_name="League of Legends 🎮 - Champion Performance Analysis 🏆"
)
def lol():
# ... Multiple cron schedules per DAG, source: by author
Multiple cron schedules per DAG, source: by author
New in Airflow 3: Need your DAG to run on different cron schedules? Airflow 3 introduces MultipleCronTriggerTimetable, allowing multiple, timezone-aware cron schedules for enhanced flexibility.
Airflow Tip: Make your DAGs easier to spot! Use dag_display_name in your DAG definition to give them friendly, descriptive titles in the Airflow UI, improving discoverability. Also works on task-level.
Our current AI analyst generates a Markdown report, which is functional. However, we can significantly enhance its impact and readability by instructing our Gemini AI to produce a visually appealing HTML report instead. This involves refining our system prompt for the @task.llm decorator. A more detailed prompt can guide the LLM to generate structured, styled output, even including elements like champion images.
Here’s our enhanced system prompt for the analyze task:
You are a professional League of Legends analyst. Your task is to analyze the provided match data and generate a\
visually appealing HTML report summarizing champion performance.
The HTML report should include:
1. A main title for the report (e.g., "League of Legends - Champion Performance Analysis").
2. Sections for each champion tier: S, A, B, C, D (best to worst).
3. Within each tier section:
* A clear heading for the tier (e.g., "S Tier Champions").
* A list or cards for each champion in that tier.
* For each champion, display:
* Their name.
* A small image of the champion. Try to use image URLs from Riot's Data Dragon CDN. For example: `http://ddragon.leagueoflegends.com/cdn//img/champion/.png`. (e.g., `Aatrox.png`, `MonkeyKing.png` for Wukong). If you are unsure of the exact champion name key or latest patch, make a best guess or use a generic placeholder image URL if necessary.
* Key performance statistics (e.g., Win Rate, KDA, Games Played from the data).
* A concise justification for their tier placement.
4. Apply basic inline CSS or a `<style>` block for a clean, professional, and visually appealing layout. Consider:
* A readable font family.
* Distinct visual styles for different tiers (e.g., background colors for tier sections or champion cards).
* Good spacing and alignment.
* Making champion images a reasonable size (e.g., 50x50 pixels).
5. The final output MUST be a single, valid HTML string, starting with `<!DOCTYPE html>` and ending with `</html>`.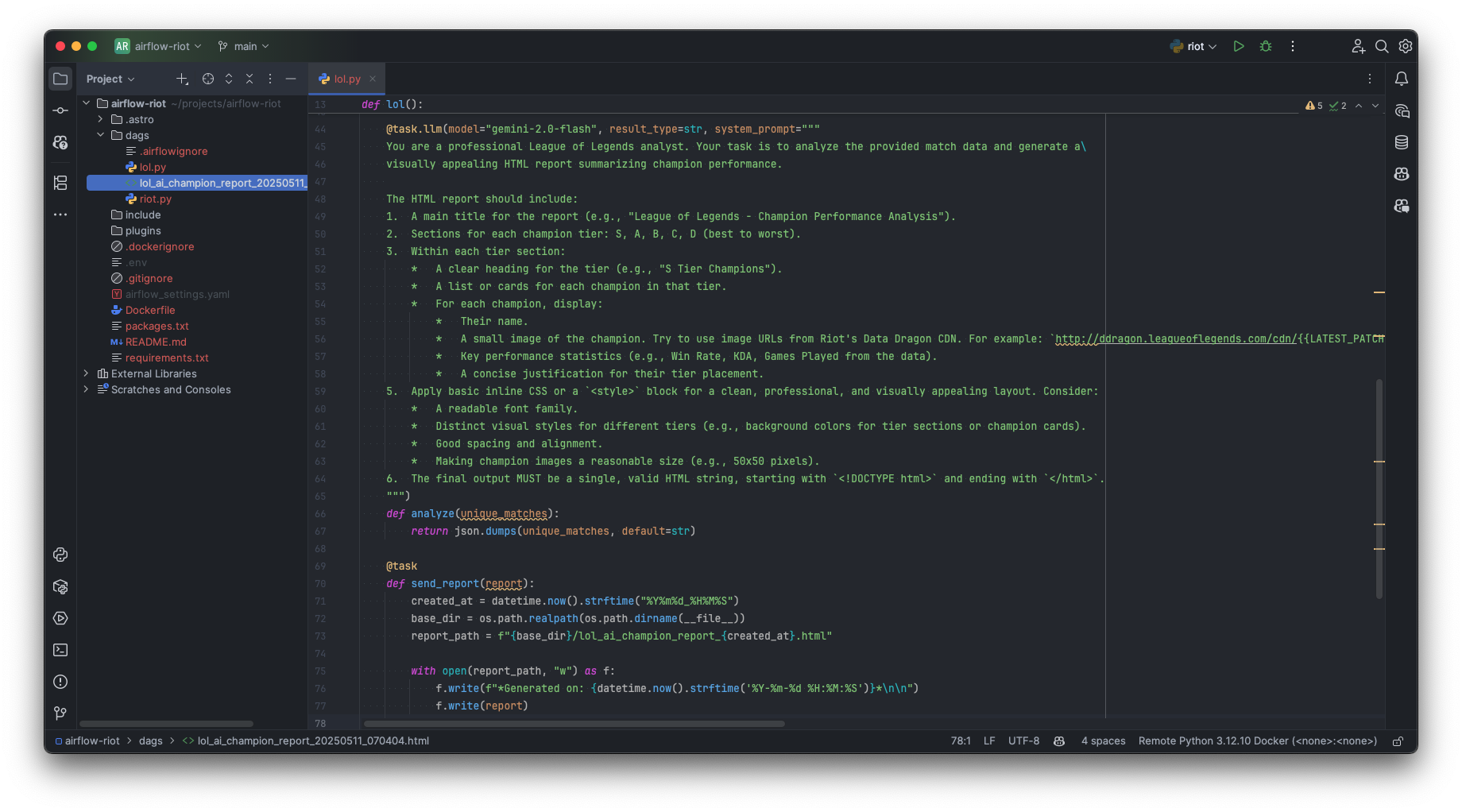 Improved system prompt, source: by author
Improved system prompt, source: by author
These polishing steps—refining the DAG’s scheduling and display, and dramatically improving the utility and presentation of its output—demonstrate how a little extra effort can significantly elevate a Data Engineering project.
We’ve journeyed from the initial idea—analyzing the data behind League of Legends—through planning, client development, dynamic orchestration, AI integration, and finally, dedicated polishing. Each step has built upon the last, incorporating modern Data Engineering practices and leveraging the powerful new features of Apache Airflow 3 and the Airflow AI SDK.
Now, it’s time to unveil the culmination of these efforts: the final, refined version of our end-to-end League of Legends analysis pipeline. This DAG incorporates all the enhancements discussed:
import asyncio
import json
import os
from datetime import datetime
from airflow.sdk import dag, task, Variable
from airflow.timetables.trigger import MultipleCronTriggerTimetable
from dags.riot import RiotApiClient, Summoner, Match
API_KEY = Variable.get("riot_api_key")
@dag(
schedule=MultipleCronTriggerTimetable(
"0 10 * * *",
"0 14 * * *",
timezone="UTC"
),
start_date=datetime(2025, 5, 10),
dag_display_name="League of Legends 🎮 - Champion Performance Analysis 🏆"
)
def lol():
@task
def fetch_top_players():
client = RiotApiClient(API_KEY)
players = asyncio.run(client.get_top_players())
# Convert Pydantic models to dictionaries for Airflow compatible serialization
return [player.model_dump(by_alias=True) for player in players]
@task
def fetch_matches(summoner):
# Convert dictionaries back to Pydantic models
summoner = Summoner.model_validate(summoner)
client = RiotApiClient(API_KEY)
matches = asyncio.run(client.get_matches_for_summoners([summoner], matches_per_summoner=5))
return [match.model_dump(by_alias=True) for match in matches]
@task
def combine_matches(match_lists):
all_matches = [Match.model_validate(match) for sublist in match_lists for match in sublist]
unique_matches = []
for match in all_matches:
if match not in unique_matches:
unique_matches.append(match)
return [match.model_dump(by_alias=True) for match in unique_matches]
@task.llm(model="gemini-2.0-flash", result_type=str, system_prompt="""
You are a professional League of Legends analyst. Your task is to analyze the provided match data and generate a\
visually appealing HTML report summarizing champion performance.
The HTML report should include:
1. A main title for the report (e.g., "League of Legends - Champion Performance Analysis").
2. Sections for each champion tier: S, A, B, C, D (best to worst).
3. Within each tier section:
* A clear heading for the tier (e.g., "S Tier Champions").
* A list or cards for each champion in that tier.
* For each champion, display:
* Their name.
* A small image of the champion. Try to use image URLs from Riot's Data Dragon CDN. For example: `http://ddragon.leagueoflegends.com/cdn//img/champion/.png`. (e.g., `Aatrox.png`, `MonkeyKing.png` for Wukong). If you are unsure of the exact champion name key or latest patch, make a best guess or use a generic placeholder image URL if necessary.
* Key performance statistics (e.g., Win Rate, KDA, Games Played from the data).
* A concise justification for their tier placement.
4. Apply basic inline CSS or a `<style>` block for a clean, professional, and visually appealing layout. Consider:
* A readable font family.
* Distinct visual styles for different tiers (e.g., background colors for tier sections or champion cards).
* Good spacing and alignment.
* Making champion images a reasonable size (e.g., 50x50 pixels).
5. The final output MUST be a single, valid HTML string, starting with `<!DOCTYPE html>` and ending with `</html>`.
""")
def analyze(unique_matches):
return json.dumps(unique_matches, default=str)
@task
def send_report(report):
created_at = datetime.now().strftime("%Y%m%d_%H%M%S")
base_dir = os.path.realpath(os.path.dirname(__file__))
report_path = f"{base_dir}/lol_ai_champion_report_{created_at}.html"
with open(report_path, "w") as f:
f.write(f"*Generated on: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}*\n\n")
f.write(report)
print(f"Report written to {report_path}")
print("::group::Generated report")
print(report)
print("::endgroup::")
top_players = fetch_top_players()
matches = fetch_matches.expand(summoner=top_players)
unique_matches = combine_matches(matches)
report = analyze(unique_matches)
send_report(report)
lol()The Airflow AI SDK, powered by Gemini, transforms our curated match statistics into beautifully formatted HTML reports, providing a clear and engaging champion tier list.
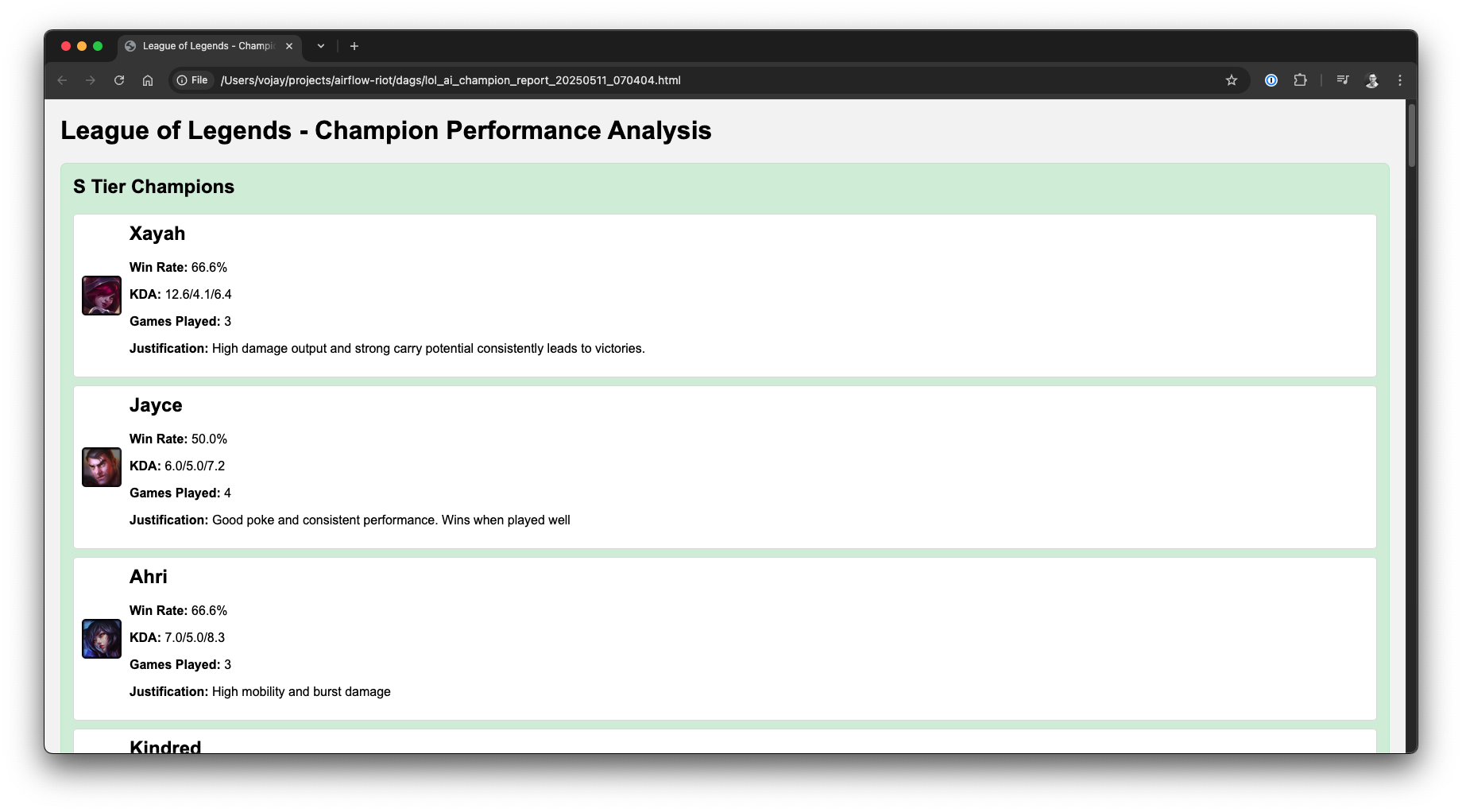 League of Legends AI generated tier list as HTML, source: by author
League of Legends AI generated tier list as HTML, source: by author
As our League of Legends pipeline has evolved, each change to its structure has effectively created a new DAG Version. Airflow 3 embraces this with powerful DAG Versioning, offering clear visibility into how workflows change over time. This involves two key ideas: Airflow’s inherent version tracking and the concept of DAG Bundles.
Airflow 3 automatically and inherently versions your DAGs. It recognizes a new DAG Version whenever a DAG run starts for a DAG whose structure has changed since the last run. Structural changes include modifications to DAG/task parameters, dependencies, task IDs, or adding/removing tasks. Crucially, each DAG run is now explicitly tied to the specific DAG code version active at its creation, a link visible throughout the Airflow UI. New runs always use the latest DAG code.
New in Airflow 3: Automatic DAG Versioning! Airflow now inherently tracks structural changes to your DAGs. Each DAG run is tied to a specific code version, visible in the UI, providing a clear historical trace for easier debugging and auditing of evolving pipelines.
This internal versioning is distinct from DAG Bundles, which are how DAG code (like our dags/lol.py) is provided to Airflow. While the default LocalDagBundle reads from the filesystem, other bundles like GitDagBundle can use external versioning. Regardless of the bundle, Airflow’s automatic versioning tracks changes in the parsed DAG files.
New in Airflow 3: Understand DAG Bundles (e.g., LocalDagBundle, GitDagBundle) as the method for packaging and supplying your DAG code. While Airflow’s internal versioning is automatic, using versioned bundles like GitDagBundle can provide an additional layer of explicit, external version control for your DAG files.
The Airflow 3 UI seamlessly integrates these versioning insights. In the grid view, historical runs accurately reflect the DAG structure of their time, even if tasks were later altered. The Code tab often allows inspection of past DAG definitions, while the graph view typically features a selector to display the DAG’s structure from different historical versions. This dynamic reconstruction is important for understanding past executions or troubleshooting issues tied to older DAG iterations.
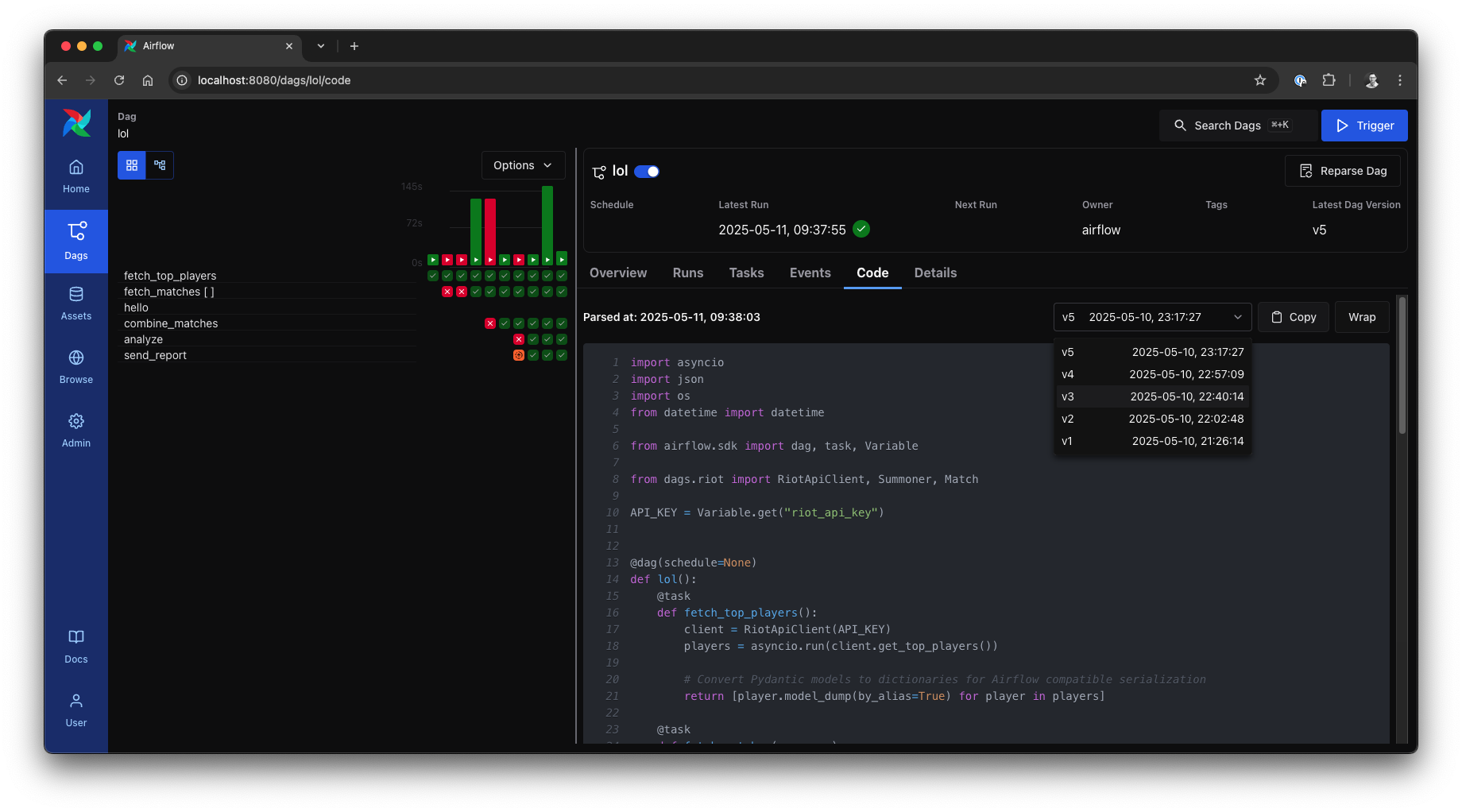 DAG Versioning in grid and code view, source: by author
DAG Versioning in grid and code view, source: by author
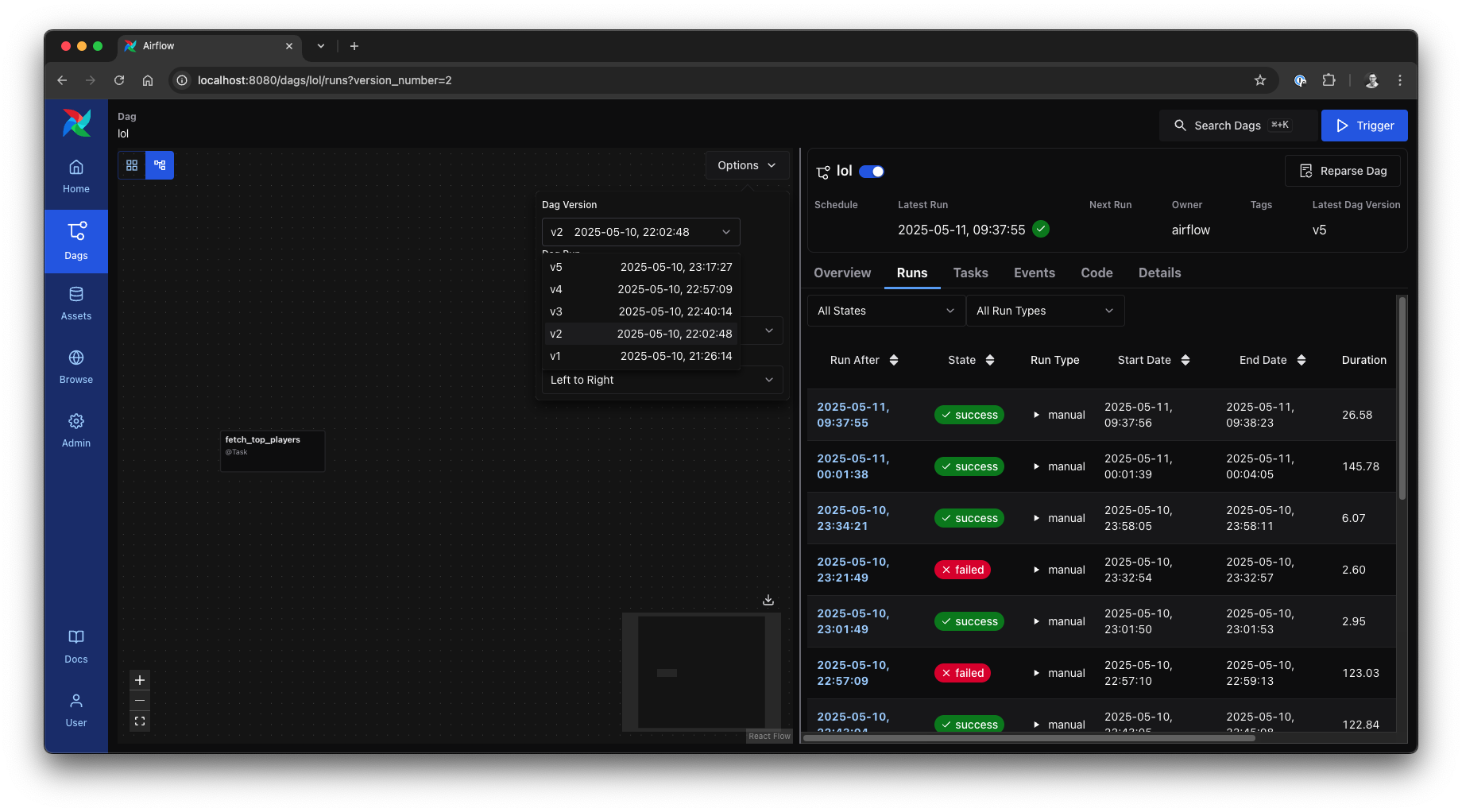 DAG Versioning in graph view, source: by author
DAG Versioning in graph view, source: by author
Collectively, these DAG Versioning features significantly enhance the Airflow experience, offering a traceable history that aids development, debugging, and auditing, ensuring the context of past DAG runs remains clear as pipelines evolve.
Our journey began in the pulsating shadows of the jungle, witnessing the raw generation of data from every calculated move on the battlefield. We’ve since traversed the pathways of Data Engineering, transforming those digital echoes into actionable insights. From the initial exploration of the Riot Games API to the deployment of an AI-powered analyst generating sophisticated champion tier lists, we’ve constructed a complete, end-to-end pipeline—a demonstration of modern orchestration and intelligent automation.
The heart of this transformation lies in the synergy of Apache Airflow 3 and the Airflow AI SDK. We’ve seen firsthand how conceptual evolutions empower us to build more reactive, intuitive, and Python-native data workflows. This is about embracing a paradigm shift, one that allows for greater clarity and efficiency in how we command our data. Complementing this, the Airflow AI SDK, with its seamless integration of powerful LLMs like Google’s Gemini, demonstrated how sophisticated AI capabilities are no longer confined to specialized environments but can be integrated into our everyday data pipelines.
Ekko’s wisdom from Arcane, that “Sometimes taking a leap forward means leaving a few things behind,” has been our guiding principle. By embracing these new tools and approaches, we consciously chose to move beyond some older, perhaps more cumbersome, patterns. The result? A more agile, intelligent, and ultimately more powerful way to engineer insights. I hope this practical exploration has not only illuminated the how but also underlined the why—why this leap forward is essential for any Data Engineer looking to stay at the top of the field.
The pipeline we’ve built serves as a robust foundation, but the true adventure begins when you start to adapt and expand upon it. Consider these potential evolutions for your own projects:
Just as LoL champions adapt and evolve to conquer new challenges, so too can you enhance your Data Engineering horizon. By embracing these cutting-edge tools and the mindset of continuous improvement, you are well-equipped to not just manage data, but to truly master it. The data rift awaits you—go forth and engineer greatness.
A personal journey and practical guide from Hamburg to Hollywood
Create an AI agent with PydanticAI to interact with Airflow DAGs
Supercharge Workflows - How to 10x Your Productivity with Local AI, Ollama, and Raycast - 100% Free & Secure


{kind=link}